






 本文介绍了一种早期使用Seq2Seq模型解决机器翻译问题的方法,该模型由Google的Ilya Sutskever博士提出。文章详细阐述了Seq2Seq模型的基本结构及其在机器翻译任务中的有效性。此外,还探讨了输入序列翻转这一技巧如何提高模型性能。
本文介绍了一种早期使用Seq2Seq模型解决机器翻译问题的方法,该模型由Google的Ilya Sutskever博士提出。文章详细阐述了Seq2Seq模型的基本结构及其在机器翻译任务中的有效性。此外,还探讨了输入序列翻转这一技巧如何提高模型性能。
seq2seq+各种形式的attention近期横扫了nlp的很多任务,本篇将分享的文章是比较早(可能不是最早)提出用seq2seq来解决机器翻译任务的,并且取得了不错的效果。本文的题目是Sequence to Sequence Learning with Neural Networks,作者是来自Google的Ilya Sutskever博士(现在OpenAI)。可以说这篇文章较早地探索了seq2seq在nlp任务中的应用,后续的研究者在其基础上进行了更广泛的应用,比如自动文本摘要,对话机器人,问答系统等等。
这里看一张很经典的图,如下:
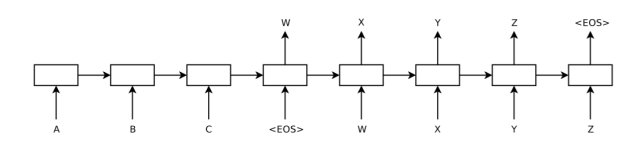
图的左半边是encoder,右半边是decoder,两边都采用lstm模型,decoder本质上是一个rnn语言模型,不同的是在生成词的时候依赖于encoder的最后一个hidden state,可以用下式来表示:
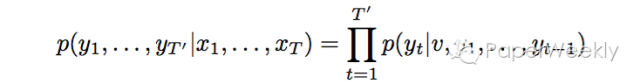
模型非常简单,就是最普通的多层lstm,实际实现的时候有几点不同:
-
用了两种不同的lstm,一种是处理输入序列,一种是处理输出序列。
-
更深的lstm会比浅的lstm效果更好,所以本文选择了四层。
-
将输入的序列翻转之后作为输入效果更好一些。
这里在decoder部分中应用了beam search来提升效果,beam search大概的思路是每次生成词是取使得整个概率最高的前k个词作为候选,这里显然beam size越大,效果越好,但是beam size越大会造成计算的代价也增大,所以存在一个trade off。
最后通过机器翻译的数据集验证了了seq2seq模型的有效性。
这里需要讨论的一点是,为什么将输入倒序效果比正序好?文中并没有说,只是说这是一个trick。但后面读了关于attention的文章之后,发现soft attention或者说alignment对于seq2seq这类问题有着很大的提升,我们都知道rnn是一个有偏模型,顺序越靠后的单词在最终占据的信息量越大,那么如果是正序的话,最后一个词对应的state作为decoder的输入来预测第一个词,显然在alignment上来看,这两个词并不是对齐的,反过来,如果用倒序的话,之前的一个词成了最后一个词,在last state中占据了主导,用这个词来预测decoder的第一个词,从某种意义上来说实现了alignment,所以效果会好一些。
来源:paperweekly

















 880
880

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









