好的,以下是一个详细的问题描述,包含了系统环境、配置文件信息和错误信息,应该能帮助你更清晰地向他人求助:
---
**问题描述:**
在运行 MMsegmentation 中的 Mask2Former 模型训练时,遇到了以下错误:
```plaintext
AttributeError: class `Mask2FormerHead` in mmseg/models/decode_heads/mask2former_head.py: 'ConfigDict' object has no attribute 'layer_cfg'
```
**系统环境:**
* **操作系统:** Ubuntu 22.04
* **Python 版本:** 3.9.23
* **CUDA 版本:** 11.6
* **PyTorch 版本:** 1.13.1+cu116
* **TorchVision 版本:** 0.14.1+cu116
* **MMEngine 版本:** 0.7.4
* **GPU:** NVIDIA GeForce RTX 4090
**配置文件:**
```python
model = dict(
type='Mask2Former',
data_preprocessor=dict(
type='SegDataPreProcessor',
mean=[123.675, 116.28, 103.53],
std=[58.395, 57.12, 57.375],
bgr_to_rgb=True,
pad_val=0,
seg_pad_val=255,
size=(512, 512)),
backbone=dict(
type='ResNet',
depth=50,
num_stages=4,
out_indices=(0, 1, 2, 3),
frozen_stages=1,
norm_cfg=dict(type='SyncBN', requires_grad=True),
norm_eval=False,
style='pytorch',
init_cfg=dict(type='Pretrained', checkpoint='torchvision://resnet50')),
neck=dict(
type='FPN',
in_channels=[256, 512, 1024, 2048],
out_channels=256,
num_outs=4),
decode_head=dict(
type='Mask2FormerHead',
in_channels=[256, 512, 1024, 2048],
strides=[4, 8, 16, 32],
num_classes=6,
in_index=[0, 1, 2, 3],
feat_channels=256,
out_channels=256,
num_queries=100,
num_transformer_feat_level=3,
pixel_decoder=dict(
type='mmdet.MSDeformAttnPixelDecoder',
num_outs=3,
norm_cfg=dict(type='GN', num_groups=32),
act_cfg=dict(type='ReLU'),
encoder=dict(
type='DetrTransformerEncoder',
num_layers=6,
transformerlayers=dict(
type='BaseTransformerLayer',
attn_cfgs=dict(
type='MultiScaleDeformableAttention',
embed_dims=256,
num_heads=8,
num_levels=3,
num_points=4,
im2col_step=64),
ffn_cfgs=dict(
type='FFN',
embed_dims=256,
feedforward_channels=1024,
num_fcs=2,
ffn_drop=0.0,
act_cfg=dict(type='ReLU'))),
positional_encoding=dict(
type='SinePositionalEncoding', num_feats=128, normalize=True)),
enforce_decoder_input_project=False,
positional_encoding=dict(
type='SinePositionalEncoding', num_feats=128, normalize=True),
transformer_decoder=dict(
type='DetrTransformerDecoder',
return_intermediate=True,
num_layers=9,
# Missing `layer_cfg` here, which causes the error
),
loss_cls=dict(
type='CrossEntropyLoss',
use_sigmoid=False,
loss_weight=2.0,
class_weight=[1.0, 1.0, 1.0, 1.0, 1.0, 0.1]),
loss_mask=dict(
type='CrossEntropyLoss',
use_sigmoid=True,
loss_weight=5.0,
reduction='mean'),
loss_dice=dict(
type='DiceLoss', use_sigmoid=True, activate=True,
loss_weight=5.0)),
train_cfg=dict(
assigner=dict(
type='HungarianAssigner',
match_costs=[dict(type='ClassificationCost', weight=2.0),
dict(type='CrossEntropyLossCost', weight=5.0, use_sigmoid=True),
dict(type='DiceCost', weight=5.0, pred_act=True, eps=1.0)])),
test_cfg=dict(mode='whole'))
```
**错误信息:**
```plaintext
Traceback (most recent call last):
File "/home/lwy/.conda/envs/mmseg39/lib/python3.9/site-packages/mmengine/config/config.py", line 52, in __getattr__
value = super().__getattr__(name)
File "/home/lwy/.conda/envs/mmseg39/lib/python3.9/site-packages/addict/addict.py", line 67, in __getattr__
return self.__getitem__(item)
File "/home/lwy/.conda/envs/mmseg39/lib/python3.9/site-packages/mmengine/config/config.py", line 48, in __missing__
raise KeyError(name)
KeyError: 'layer_cfg'
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/home/lwy/mmsegmentation/mmseg/models/decode_heads/mask2former_head.py", line 42, in __init__
super().__init__(**kwargs)
File "/home/lwy/.conda/envs/mmseg39/lib/python3.9/site-packages/mmdet/models/dense_heads/mask2former_head.py", line 106, in __init__
assert pixel_decoder.encoder.layer_cfg.
AttributeError: 'ConfigDict' object has no attribute 'layer_cfg'
```
最新发布




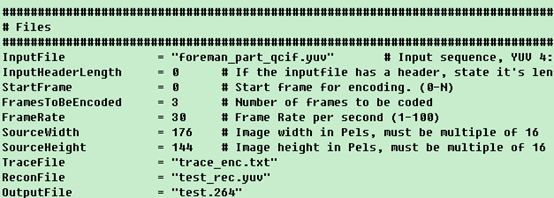
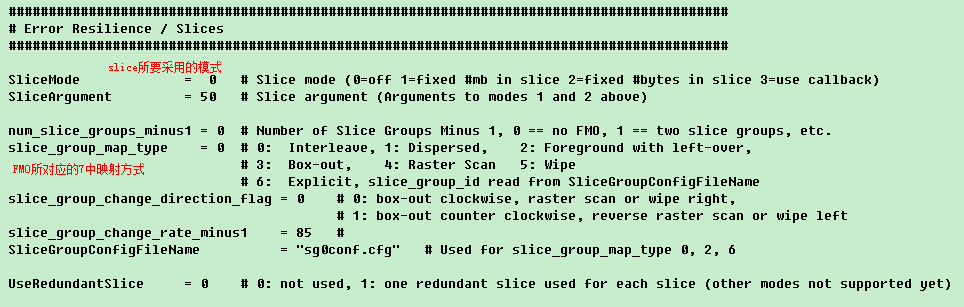
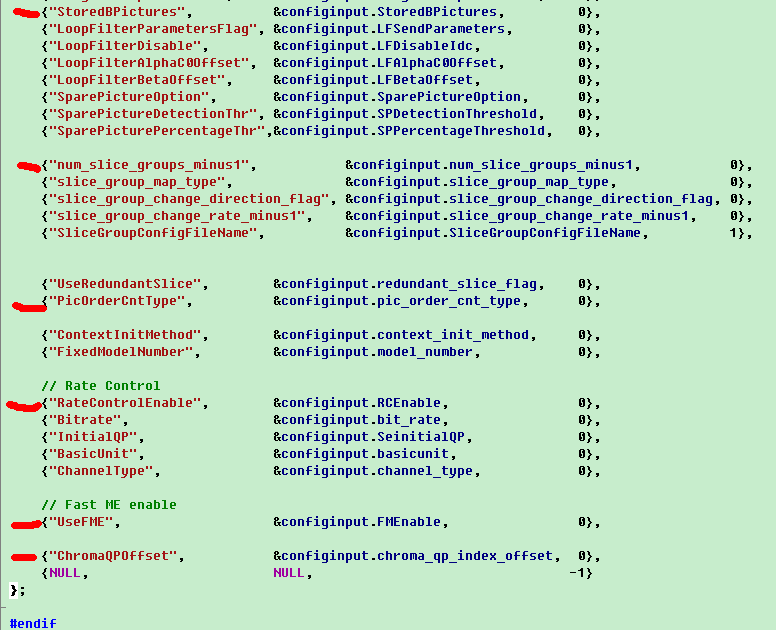
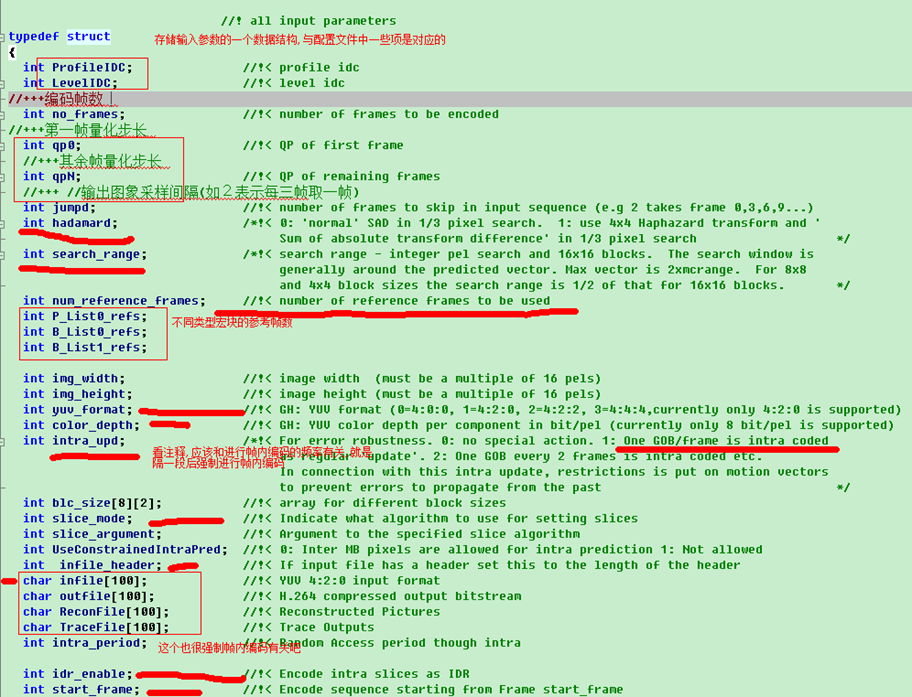
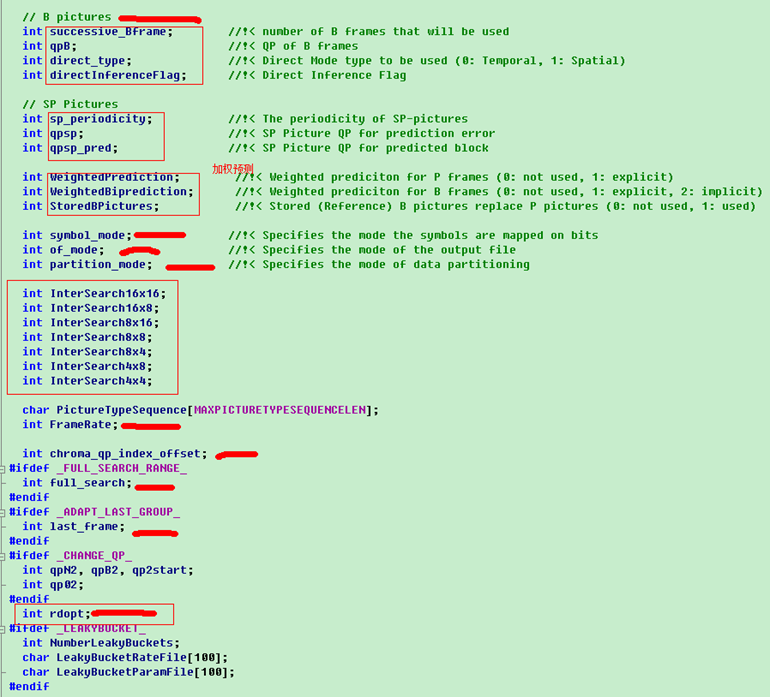
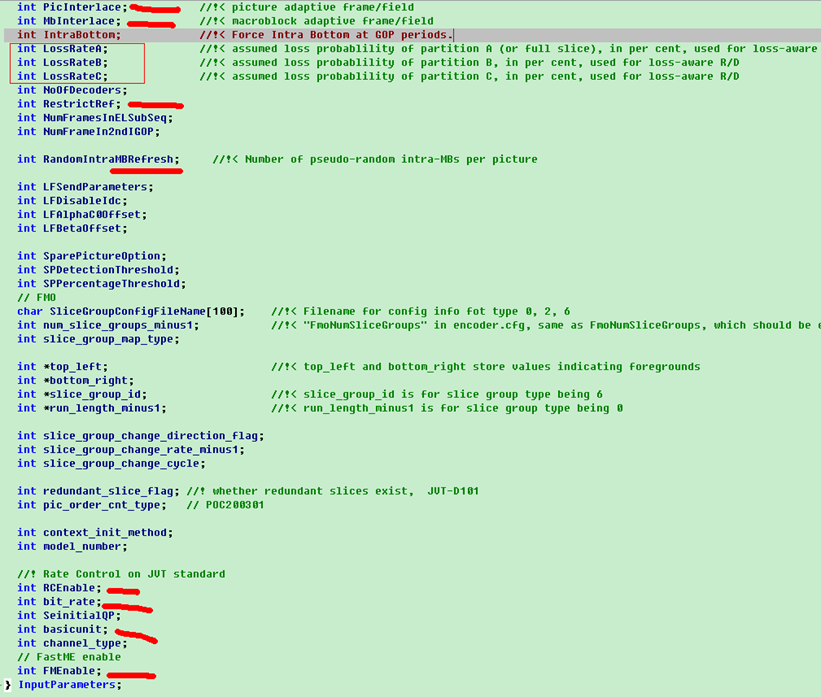
 本文深入探讨编码控制与配置文件使用,详细解释了配置文件中的各项参数设置,包括输入/输出文件配置、B帧与SP帧参数设置、NAL输出控制、CABAC编码方式、MbAFF与PAFF选择等,并提供了对配置文件的理解与分析。
本文深入探讨编码控制与配置文件使用,详细解释了配置文件中的各项参数设置,包括输入/输出文件配置、B帧与SP帧参数设置、NAL输出控制、CABAC编码方式、MbAFF与PAFF选择等,并提供了对配置文件的理解与分析。


























 1384
1384

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









