






 本文详细介绍了K-means聚类算法的实现流程,包括初始化中心点、更新标签、计算新的中心点以及停止条件。并通过Python代码示例展示了算法的具体实现过程,最后给出了一组数据的聚类结果。
本文详细介绍了K-means聚类算法的实现流程,包括初始化中心点、更新标签、计算新的中心点以及停止条件。并通过Python代码示例展示了算法的具体实现过程,最后给出了一组数据的聚类结果。
k-means方法实现流程: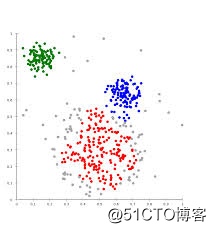
输入:k, data[n];
(1) 选择k个初始中心点,例如c[0]=data[0],…c[k-1]=data[k-1];
(2) 对于data[0]….data[n], 分别与c[0]…c[k-1]比较,假定与c[i]差值最少,就标记为i;
(3) 对于所有标记为i点,重新计算c[i]={ 所有标记为i的data[j]之和}/标记为i的个数;
(4) 重复(2)(3),直到所有c[i]值的变化小于给定阈值。
k-means方法具体实现和流程:
import numpy as np
#X样本点坐标矩阵
def kmeans(X, k, maxIt):
#X.shape:矩阵的形状,返回值为行和列
numPoints, numDim = X.shape
#得到一个比原矩阵多一列的0矩阵
dataSet = np.zeros((numPoints, numDim + 1))
#前面n-1列为点的值
dataSet[:, :-1] = X
#Initialize centroids randomls随机产生初始中心
#中心点为任意一行数据
centroids = dataSet[np.random.randint(numPoints, size=k), :]
centroids = dataSet[0:2, :]
#为中心点赋予类名称,range函数的特点是按顺序从前往后赋值1到k,但是k+1必须小于列数,复制到k时,后面的值自动为0
centroids[:, -1] = range(1, k + 1)
#第一个为存储迭代次数,第二个存储旧的中心
iterations = 0
oldCentroids = None
while not shouldStop(oldCentroids, centroids, iterations, maxIt):
print("iteration: \n", iterations)
print("dataSet: \n", dataSet)
print("centroids: \n", centroids)
#复制一份中心数据,这样互不影响,引用则不行
oldCentroids = np.copy(centroids)
#每进行一次这个程序,迭代次数就增加1次
iterations += 1
#调用方法更新标签
updateLabels(dataSet, centroids)
#调用方法更新中心
centroids = getCentroids(dataSet, k)
#We can get the labels too by calling getLabels(dataSet, centroids)
return dataSet
#结束条件:迭代次数大于设定的次数或者旧的迭代中心和新得到的迭代中心相等
def shouldStop(oldCentroids, centroids, iterations, maxIt):
if iterations > maxIt:
return True
return np.array_equal(oldCentroids, centroids)
#Update a label for each piece of data in the dataset.
def updateLabels(dataSet, centroids):
# For each element in the dataset, chose the closest centroid.
#Make that centroid the element's label.
numPoints, numDim = dataSet.shape
#循环获取每一行数据
for i in range(0, numPoints):
#dataSet[i,-1]表示后面每一行数据的分类标签
dataSet[i, -1] = getLabelFromClosestCentroid(dataSet[i, :-1], centroids)
def getLabelFromClosestCentroid(dataSetRow, centroids):
label = centroids[0, -1];
#第一行数据与目标的距离定义为最小值
minDist = np.linalg.norm(dataSetRow - centroids[0, :-1])
#依次比较距离,最终得到属于的标签
for i in range(1, centroids.shape[0]):
dist = np.linalg.norm(dataSetRow - centroids[i, :-1])
if dist < minDist:
minDist = dist
label = centroids[i, -1]
print("minDist:", minDist)
return label
#Returns k random centroids, each of dimension n.
def getCentroids(dataSet, k):
result = np.zeros((k, dataSet.shape[1]))
#k表示聚类中心个数
for i in range(1, k + 1):
print(dataSet)
#找出同类型的点,取出样本点的向量值
oneCluster = dataSet[dataSet[:, -1] == i, :-1]
print("--------------------")
print(oneCluster)
print("-------------------")
#通过均值计算中心点
result[i - 1, :-1] = np.mean(oneCluster, axis=0)
#给中心点赋标签值
result[i - 1, -1] = i
return result
x1 = np.array([1, 1])
x2 = np.array([2, 1])
x3 = np.array([4, 3])
x4 = np.array([5, 4])
testX = np.vstack((x1, x2, x3, x4))
result = kmeans(testX, 2, 10)
print("final result:")
print(result)转载于:https://blog.51cto.com/13831593/2298447

















 2269
2269

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









