 DatabaseMesh与Sharding-JDBC
DatabaseMesh与Sharding-JDBC




 随着微服务架构的普及,数据库访问管理变得日益重要。DatabaseMesh作为一种新兴理念,旨在统一治理分散的数据库资源。Sharding-JDBC作为该领域的先行者之一,提供了包括Driver、Server及Sidecar等多种版本,以适应不同场景的需求。这些工具不仅帮助应用透明地访问多个数据库,还能优化SQL处理,减少内存消耗。
随着微服务架构的普及,数据库访问管理变得日益重要。DatabaseMesh作为一种新兴理念,旨在统一治理分散的数据库资源。Sharding-JDBC作为该领域的先行者之一,提供了包括Driver、Server及Sidecar等多种版本,以适应不同场景的需求。这些工具不仅帮助应用透明地访问多个数据库,还能优化SQL处理,减少内存消耗。
在微服务和云原生大潮的卷席之下,服务化一直以来是人们关注的重点。但服务化之后,真正绕不开的数据访问却鲜有论道。尽管目前的关系型数据库远达不到云原生的要求,并且对分布式的不友好在长期以来也饱受诟病,但不可否置的是,关系型数据库至今依然扮演着极其重要的角色。
\\从其本身以及周边生态圈的成熟度、数据查询的灵活度、开发工程师以及 DBA 对其的掌控程度以及招聘到适合人员的难易度等方面来看,无论是 NoSQL 还是 NewSQL,实难于在近期完全取而代之。
\\那么,对于微服务架构中越来越多的数据库垂直拆分,以及数据量急剧膨胀后的数据库水平拆分,是否存在行之有效的方案来管理呢?当今大为流行的 Service Mesh 理念又能否对数据库的治理带来一些启示呢?
\\Database Mesh
\\Database Mesh,一个搭乘 Service Mesh 浪潮衍生出来的新兴词汇。顾名思义,Database Mesh 使用一个啮合层,将散落在系统各个角落中的数据库统一治理起来。通过啮合层集中在一起的应用与数据库之间的交互网络,就像蜘蛛网一样复杂而有序。
\\从这一点来看,Database Mesh 的概念与 Service Mesh 如出一辙。之所以称其为 Database Mesh,而非 Data Mesh,是因为它的首要目标并非啮合存储于数据库中的数据,而是啮合应用与数据库间的交互。
\\Database Mesh 的关注重点在于如何将分布式的数据访问应用与数据库有机串联起来,它更加关注的是交互,是将杂乱无章的应用与数据库之间的交互有效的梳理。
\\使用 Database Mesh,访问数据库的应用和数据库终将形成一个巨大的网格体系,应用和数据库只需在网格体系中对号入座即可,它们都是被啮合层所治理的对象。
\\Service Mesh 回顾
\\服务治理主要关注服务发现、负载均衡、动态路由、降级熔断、调用链路以及 SLA 采集等非功能性需求。通常来说,可以通过代理端和客户端这两种架构方案实现。
\\代理端的方案是基于网关的。提供服务的应用服务器被隐藏在网关之后,访问请求必须经由网关,由网关进行相应的服务治理动作后,再将流量路由至后端应用。Nginx、Kong、Kubernetes Ingress 等采用此类方案。
\\客户端的方案则是由部署在应用端的类库进行相应的服务治理动作,并以点对点的方式访问服务提供者。Dubbo、Spring Cloud 等采用此种方案。
\\无论使用代理端还是客户端进行服务治理,都有其各自的优缺点。
\\在代理端进行服务治理的优点是应用只需获取网关地址即可,后端的复杂部署结构被完全屏蔽。缺点则是代理端自身的性能和可用性是整个系统的瓶颈,一旦宕机后果较为严重。其中心化架构理念,与云原生背道而驰。
\\在客户端进行服务治理的优点是使用无中心化架构,无需担心某个节点成为系统瓶颈。缺点则是服务治理对业务代码的侵入。对于云原生所看重的零侵入来说,使用客户端进行服务治理的方式显然是不可行的。客户端治理的方案更无法做到对异构语言的支持。
\\在既希望零入侵、又需要无中心的云原生架构下,第三种架构模型——Sidecar 则显得更加契合。Sidecar 以一个独立的进程启动,可以每台宿主机共用同一个 Sidecar 进程,也可以每个应用独占一个 Sidecar 进程。
\\所有的服务治理功能,都由 Sidecar 接管,应用的对外访问仅需要访问 Sidecar 即可。显而易见,基于 Sidecar 模式的 Service Mesh 才是云原生架构的更好的实现方式,零侵入和无中心化使得 Service Mesh 倍受推崇。
\\尤其是配合 Mesos 或 Kubernetes 一起使用时,通过 Marathon 或 DeamonSet 确保 Sidecar 在每个宿主机都能够启动,再配合其对容器的动态调度能力,能发挥更大的威力。Kubernetes(Mesos) + Service Mesh = 弹性伸缩 + 零侵入 + 无中心,它们合力完成了一个云端所需的基础设施。
\\Database Mesh 与 Service Mesh 的异同
\\数据库应用治理与服务治理的目标既有重叠,又有所不同。相比于服务,数据库是有状态的,无法像服务一样随意路由到对等节点,因此数据分片是一个重要的能力。相对来说,数据库实例的自动发现能力则不那么重要,原因也是数据库的有状态性,启动或停止一个新的数据库实例,往往意味着数据迁移。当然也可以采用多数据副本、读写分离、主库多写等方式进行进一步的处理。其他功能诸如对多从库的负载均衡、熔断、链路采集等,在数据库治理中也同样适用。
\\与服务治理一样,对数据库应用的治理同样可以套用这三种架构方案。
\\基于代理端的解决方案是使用一个实现相应数据库通信协议(如 MySQL)的代理服务器。Cobar、MyCAT、kingshard 以及即将推出的 Sharding-JDBC-Server 等采用此种方案。基于客户端的解决方案则必须与开发语言强绑定,例如 Java 语言一般可以通过 JDBC 或某个 ORM 框架来实现。TDDL 和 Sharding-JDBC 等采用此种方案。
\\同理,无论是代理端还是客户端,都有各自的优缺点。代理端的优点是异构语言的支持,缺点依然是中心化架构。客户端的优点是无中心化架构,缺点则是无法支持异构语言,因此,对各种数据库的命令行以及图形界面的客户端便无法有效支持。
\\采用 Sidecar 模式,同样可以有效的结合代理端与客户端的优点,并屏蔽其缺点。但是,基于服务治理的 Sidecar 和基于数据库访问的 Sidecar 是一样的么?当然不是。最主要的不同在于数据分片。
\\分片是一个复杂的过程,如果希望做到对应用透明,业界常见的做法是针对 SQL 进行解析,并将其精准路由至相应的数据库中执行,最终将执行结果进行归并,以保证数据在分片的情况下逻辑仍然正确。
\\一个数据分片的核心流程是 SQL 解析 –\u0026gt; SQL 路由 –\u0026gt; SQL 改写 –\u0026gt; SQL 执行 –\u0026gt; 结果归并。为了满足对遗留代码的零侵入,还需要对 SQL 的执行协议进行封装。比如,在代理端则需要模拟 MySQL 或其他相应数据库的通信协议;在 Java 客户端实现,则需要覆盖 JDBC 接口的相应方法。
\\说了很多,那么当前是否有 Database Mesh 的实现方案呢?遗憾的是,目前还没有。即使是流行度很广的 Service Mesh,它的各个产品也都还是在成熟的路上。
\\出现稍早的 Linkerd 和 Envoy 虽然可以在生产环境使用,但新一代的 Istio 以更加宏伟的构图吸引着业界的眼球,只是目前还无法用于生产环境。Database Mesh 作为 Service Mesh 的延展,则更是处于发展的萌芽状态。
\\Sharding-JDBC
\\Sharding-JDBC 于 2016 年由当当开源。最初,它是一个在 Java 的 JDBC 层实现分库分表的数据库中间层。今年,京东金融云决定将 Sharding-JDBC 作为其核心的对外输出。
\\那么,Sharding-JDBC 势必要进行革新,面对云端,Database Mesh 无疑是正确的发展方向。Sharding-JDBC 决定实现 Sidecar 版本,期望可以成为一个纯粹的云原生数据库中间层产品。
\\目标
\\Sharding-JDBC 的终极目标是像使用一个数据库一样透明的使用散落在各个系统中的数据库。让应用开发者和 DBA 尽可能顺畅地将其工作迁移至基于 Sharding-JDBC 的云原生环境中。Sharding-JDBC 希望提供一个无中心化、零侵入以及跨语言的云原生解决方案。
\\演进历程
\\Sharding-JDBC 一直以来,以 JDBC 层分片作为其核心理念。它的架构图如下:
\\
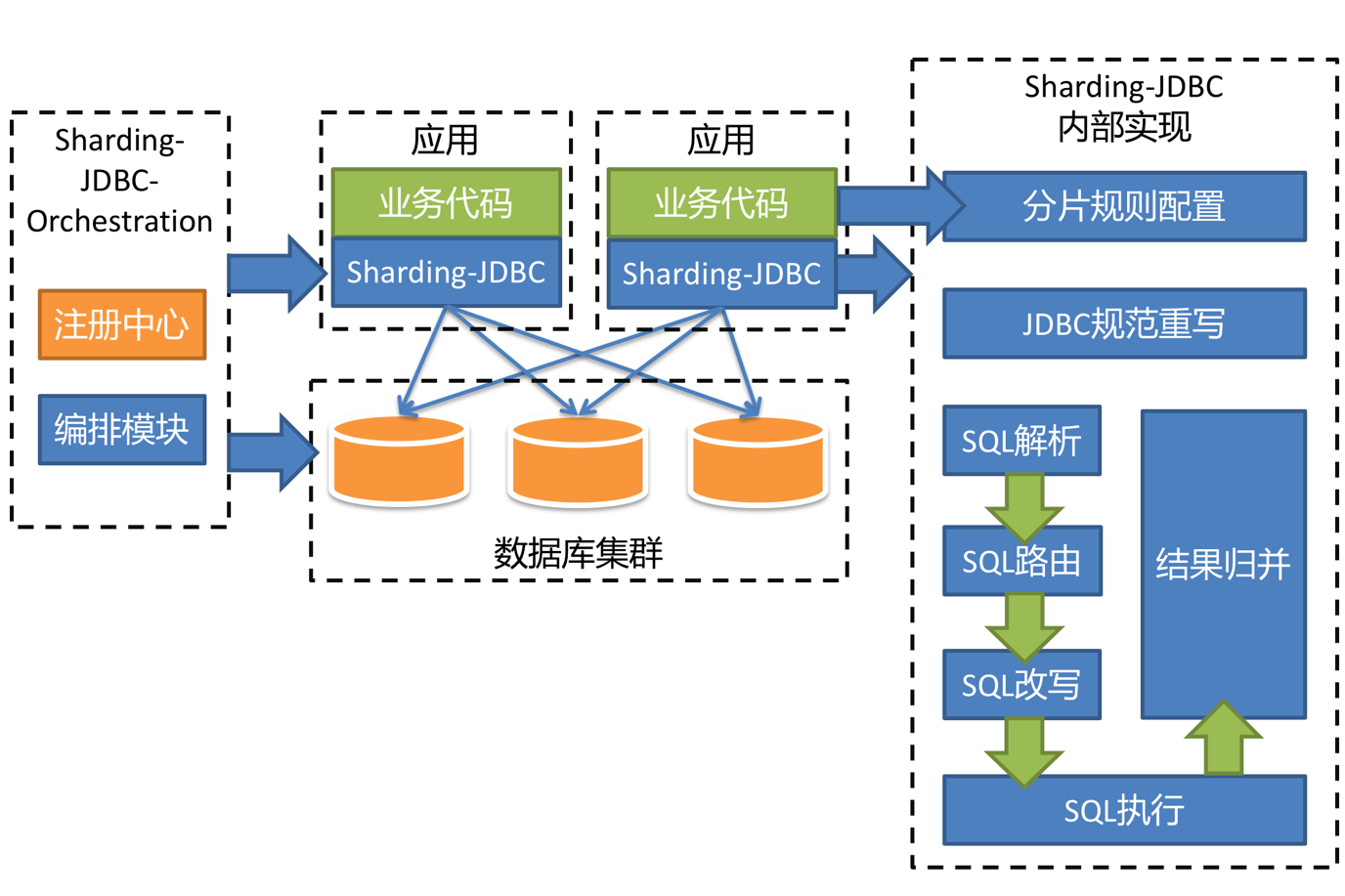
它分为分片模块、柔性事务模块以及数据库治理模块。作为其核心的分片模块完整的实现了 SQL 解析、路由、改写、执行和归并的过程。但是,作为一个立志服务于云原生架构的产品,仅在 JDBC 层提供服务是远远不够的。
\\Sharding-JDBC 将分别实现 Driver、Server 以及 Sidecar 这三个不同的版本,一起组成 Sharding-JDBC 的生态圈,为不同的需求与环境提供更加具有针对性的差异化服务。近期,Sharding-JDBC 将发布其 Server 版本。在不久的将来,Sharding-JDBC 的 Sidecar 版本也将投入开发。原有的 Sharding-JDBC 将重命名为 Sharding-JDBC-Driver。由于分片的核心功能已经实现完毕,因此架构模型的调整并不复杂,Sharding-JDBC-Server 的核心代码仍然使用 Sharding-JDBC 的原有分片逻辑,只是在外围包装了 MySQL 协议,未来也将提供其他数据库的兼相关容协议。架构图如下:
\\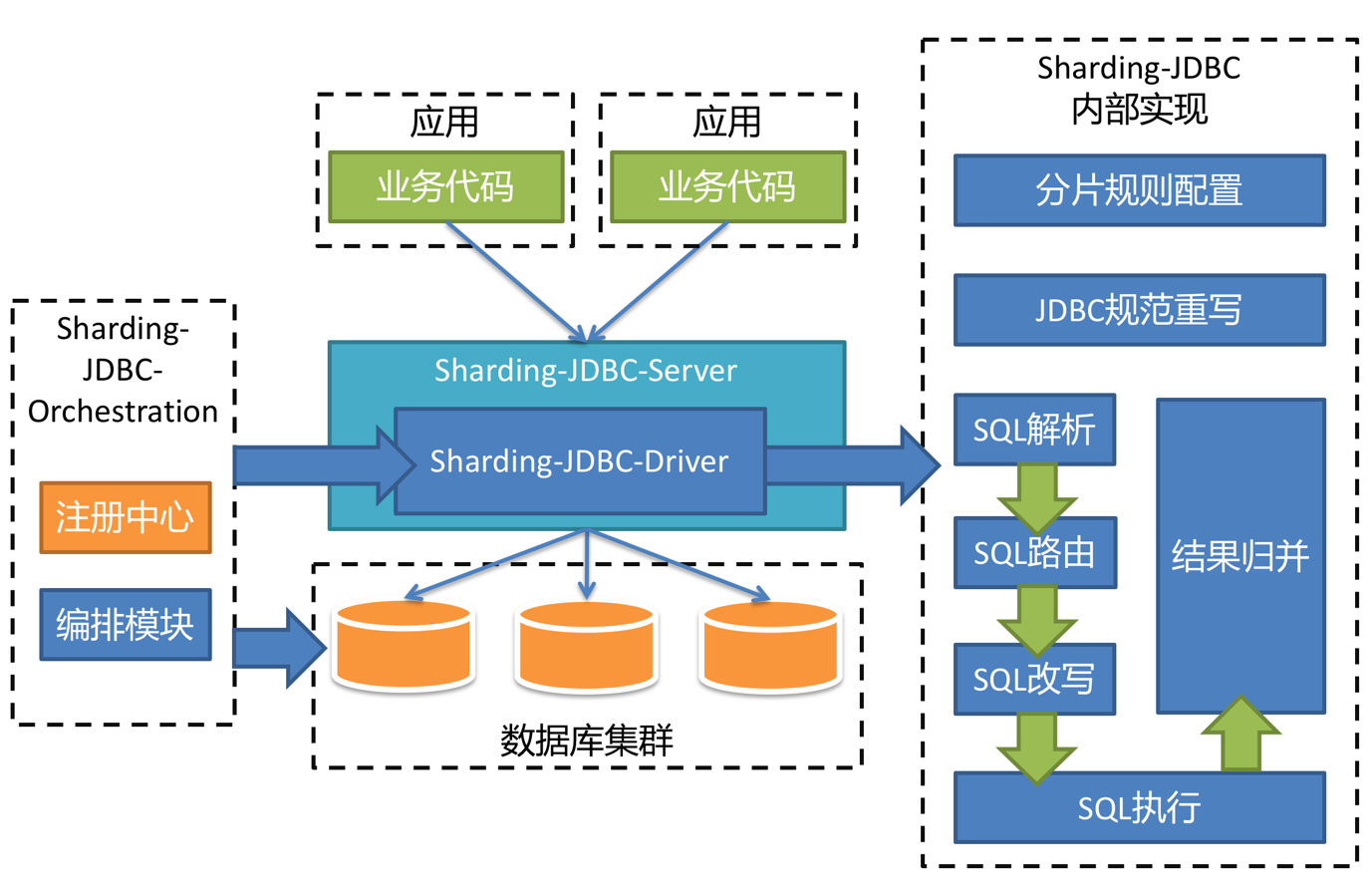
由于 Sharding-JDBC-Server 的出现,使得原来 DBA 通过 Sharding-JDBC-Driver 无法对数据进行操作的缺憾得到了补偿。由于 Sharding-JDBC-Driver 无需通过代理层进行二次转发,因此线上性能更佳,可以通过以下的混合部署方案使用 Sharding-JDBC:
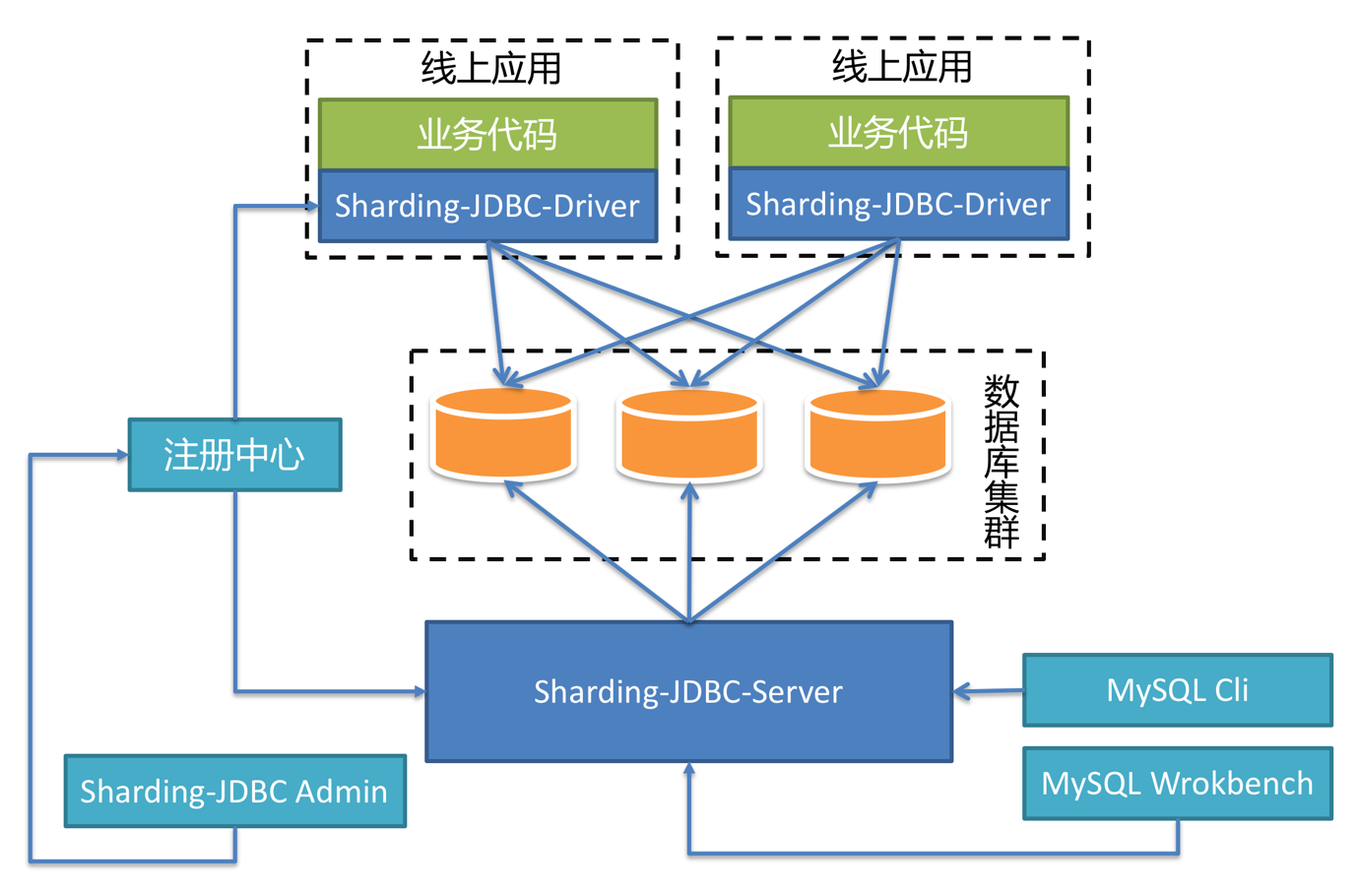
线上应用使用 Sharding-JDBC-Driver 直连数据库以获取最优性能,使用 MySQL 命令行或 UI 客户端连接 Sharding-JDBC-Server 方便的查询数据和执行各种 DDL 语句。它们使用同一个注册中心集群,通过管理端配置注册中心中的数据,即可由注册中心自动将配置变更推送至 Driver 和 Server 应用。若数据库拆分的过多而导致连接数会暴涨,则可以考虑直接在线上使用 Sharding-JDBC-Server,以达到有效控制连接数的目的。
\\在不久的将来,Sharding-JDBC-Sidecar 也将问世,它的部署架构是这样的:
\\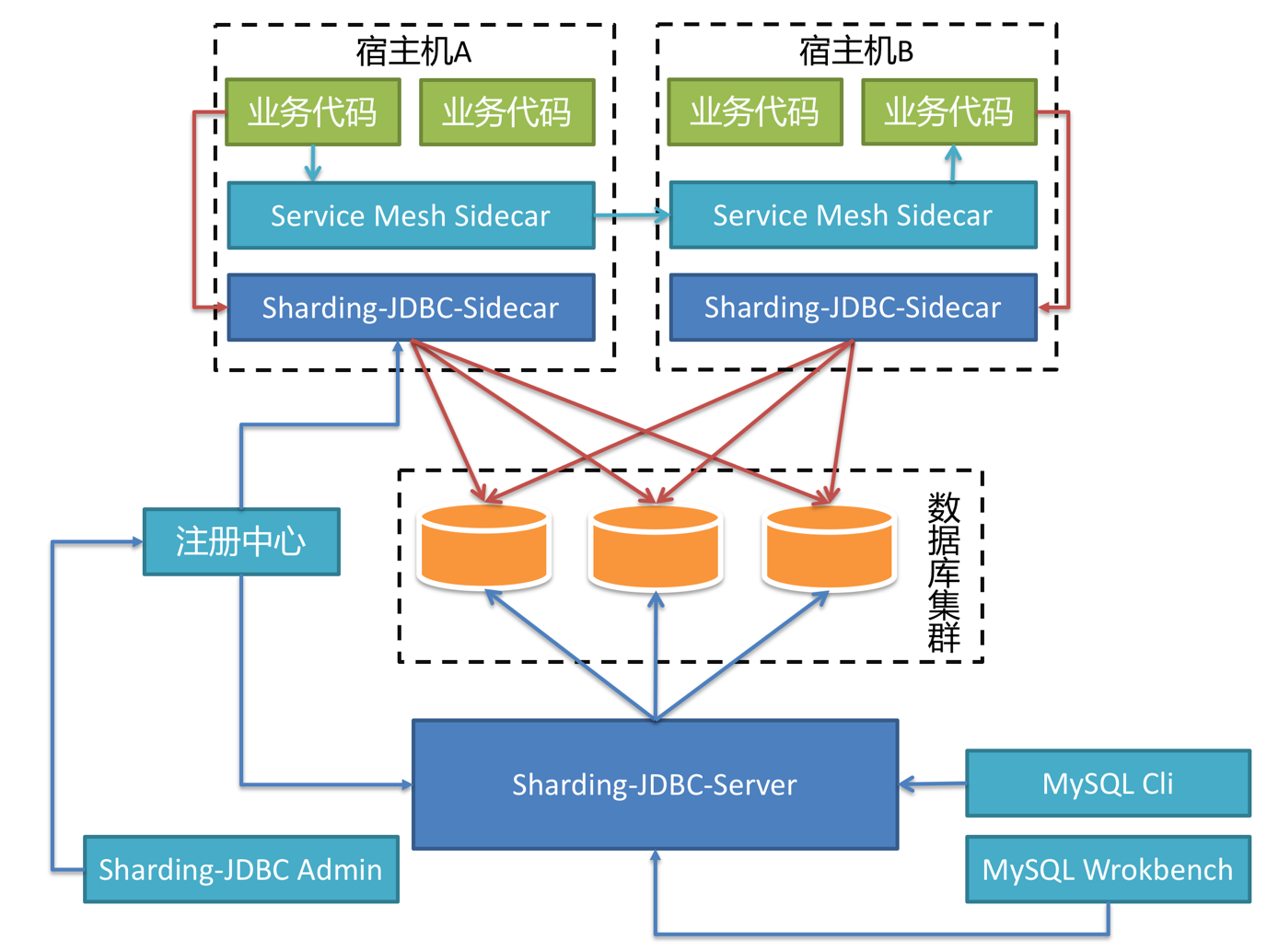
基于 Sharding-JDBC 的 Database Mesh 与 Service Mesh 互不干扰,相得益彰。服务之间的交互由 Service Mesh Sidecar 接管,基于 SQL 的数据库访问由 Sharding-JDBC-Sidecar 接管。
对于业务应用来说,无论是 RPC 还是对数据库的访问,都无需关注其真实的物理部署结构,做到真正的零侵入。由于 Sharding-JDBC-Sidecar 是随着宿主机的生命周期创建和消亡的,
\\因此,它并非静态 IP,而是完全动态和弹性的存在,整个系统中并无任何中心节点的存在。对于数据运维等操作,仍然可以通过启动一个 Sharding-JDBC-Server 的进程作为静态 IP 的入口,通过各种命令行或 UI 客户端进行操作。
\\拨开 Sharding-JDBC 的迷雾
\\Sharding-JDBC 自诞生以来,使用手册已经比较完善。但由于它一直处于高速发展的状态中,因此很少对外披露其内部的实现细节。虽然代码都是开源的,但要求技术人员在选型时将第三方的代码都通读一遍,显然是不现实的。篇幅有限,本文无法将 Sharding-JDBC 的所有源码从头到尾分析一遍,但可以对常见的疑问给予解答。
\\1. Sharding-JDBC 的 SQL 解析是如何做的,效率是否有问题?
\\回答:Sharding-JDBC 采用词法 + 语法解析的方式解析 SQL,先将 SQL 拆成一个个词根,再根据 SQL 语法配合其上下文进行语法解析。Sharding-JDBC 的 SQL 解析并不会产生 AST(抽象语法树),而是直接将分片所需的解析上下文提炼出来,如:Tables、Select Items、Conditions、Order Items、Group By Items、Limit 等。并直接将解析上下文应用于路由,免去了对 AST 的二次遍历,进一步提升了性能。Sharding-JDBC 的一个较为复杂的 SQL 解析大约需要 10ms,相对于 JSqlParser 等基于 JavaCC 的 SQL 解析器,性能会快数倍甚至十倍以上。
\\2. Sharding-JDBC 对于分页、排序和分组等查询,是否需要将数据全部取到内存中进行操作,这样内存是否会被撑爆?
\\回答: Sharding-JDBC 使用流式归并和内存归并两种归并方式,流式归并是完全不占用内存的,其原理与 JDBC 的 ResultSet 一样,每调用一次 next,数据的游标会下移一位;而内存归并是需要占用内存的,会将 ResultSet 中所有的数据全部取出放入内存才能进行归并。可能与大部分人的想象不同,Sharding-JDBC 仅在一种情况下才会使用内存归并,即 ORDER BY 与 GROUP BY 同时存在且排序不一致时。
\\而 LIMIT、仅 ORDER BY、仅 GROUP BY 以及 ORDER BY 与 GROUP BY 同时存在但顺序相同的情况下,都是流式归并,不会占用额外内存。具体的实现细节在本文中无法详尽说明,以后会有更多的文章另行分析。总之,Sharding-JDBC 在内核方面做了大量优化。
\\具不完全统计,已经有几十甚至上百家公司在使用 Sharding-JDBC,这其中不乏一些知名企业。在逐渐拨开迷雾的同时,希望 Sharding-JDBC 能够为技术选型者带来充足的信心。
\\未来规划
\\2018 年的 Sharding-JDBC 仍将是快速发展一年。未来的规划重点在以下四个方面:
\\- \\t
云原生。Sharding-JDBC-Driver 已经比较成熟,Sharding-JDBC-Server 即将于近期发布,Sharding-JDBC-Sidecar 也将于近期提上日程。Sharding-JDBC 将全面拥抱这三种架构模型。让其在云原生架构中熠熠生辉。
\\t\\t - \\t
SQL 兼容性。目前 Sharding-JDBC 的 SQL 内核支持除了子查询和 OR 之外的绝大部分 DQL、DML、DDL、DCL 以及 MySQL 的 admin 等相关语句。作为一个数据库产品的最核心模块,Sharding-JDBC 也将加大对子查询和 OR 的支持力度,争取支持尽量多的 SQL,真正的达到对遗留代码的最大限度兼容。
\\t\\t - \\t
功能闭环。数据库中间层关注的重点是数据分片、分布式事务和数据库治理这三方面。Sharding-JDBC 在数据分片方面涉猎较多,其余两方面则是分身乏术。未来,在完善数据分片的同时,也会逐渐对其他两个方面加强投入。Database Mesh 是对数据访问层和数据库两个部分的治理,目前的 Sharding-JDBC 对数据库治理这块的功能还有待展开。分布式事务这块,Sharding-JDBC 也会对柔性事务进行改进,通过解析 binlog 的方式自动回滚数据。
\\t\\t - \\t
链路采集。Sharding-JDBC 目前已经支持 opentracing 协议,并获得其官方的首肯。与另外一个 APM 知名项目 SkyWalking 也完成了集成,可以通过 SkyWalking 直接查看和分析 Sharding-JDBC 的调用链路。对于京东金融云的另一个核心产品分布式服务跟踪平台 SGM(Service Governance And Monitoring)也会进行整合,使得京东金融云提供更加一体化的对外服务。更多 SGM 的官方信息将于近期披露。
\\t\
如果读者对 Sharding-JDBC 感兴趣,欢迎访问 GitHub:
\\https://github.com/shardingjdbc。
\\感谢郭蕾对本文的审校。

















 1483
1483

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









