






 本次分享重点介绍了BlinkRendering项目中的三个核心部分:RootLayerScrolling改进滚动处理,LayoutNG重构排版逻辑,以及SlimmingPaint优化绘制过程。这些改进旨在提高浏览器性能并减少内存消耗。
本次分享重点介绍了BlinkRendering项目中的三个核心部分:RootLayerScrolling改进滚动处理,LayoutNG重构排版逻辑,以及SlimmingPaint优化绘制过程。这些改进旨在提高浏览器性能并减少内存消耗。
作者在 4 月 18~19 期间和同事一起在湾区参加了为其两天的 BlinkOn 9 会议。每次 BlinkOn 都是了解当前 Blink & Chrome 和 Web 技术演进现状和发展方向的一个不错机会,两天的会议下来大概听了 6 ~ 7 场分享,有些主题是之前已经有所了解,这次又更新了最新的进展信息;有些主题则是完全陌生,在这次 BlinkOn 上才第一次知悉。作者接下来会撰写一系列文章,每篇文章针对一个特定的主题,尽可能把相关的信息回馈给读者。
BlinkOn9 上 Blink Rendering - Rebuilding the Engine Mid-Flight 还是信息量比较足的一场分享,几位分享的 Googler 对 Blink 里面的祖传代码的怨念之深,从 “Rebuilding the Engine Mid-Flight” 这个副标题也可窥一斑,在现场听的时候更是让人印象深刻(笑)。
所谓 Blink Rendering,确切地说只包括:
- Layout —— 决定每个排版对象的大小和位置;
- Compositing setup —— 决定哪些排版对象需要生成合成图层,决定最终的合成图层树结构;
- Paint —— 以 display list 的形式记录每个合成图层的绘制内容(绘制指令);
而光栅化和合成的部分,那是在 Blink 之外由合成器负责的,不属于 Blink 的范畴。
分享的内容可以大致分为两部分,第一部分简单介绍了浏览器渲染的一些内部实现,作为后续内容的背景知识,在这里本文就不再重复,感兴趣的读者自行看一下分享的幻灯片,或者也可以参考作者的另外一篇文章 - 浏览器渲染流水线解析与网页动画性能优化,这篇文章提供了关于浏览器渲染的更多信息。
第二部分主要是讲述已经完成和进行中的三个项目,分别和滚动,绘制和排版相关。
Root Layer Scrolling
滚动处理相关代码由于历史原因,文档滚动和 Div 滚动一直是分开的不同代码,而现在浏览器的滚动处理逻辑越来越复杂,两套功能相似的代码给维护者带来了极大的痛苦,Root Layer Scrolling 这个项目主要的目标就是统一代码,移除大量重复的代码,提供更好的代码可维护性,并为后续其它功能和性能优化项目打下基础。相关的实现已经在 M66 上上线。
Layout NG
排版相关代码也是一个历史非常悠久的部分,关于 Blink 里面代码的可读可理解可维护性的吐槽,排版是当之无愧的排在第一位的。
排版逻辑之所以复杂,组合爆炸是一个重要原因,CSS Custom Layout 又加剧了这一点。Blink 目前的排版相关代码最远可以追溯到 KHTML 时期(KHTML -> WebKit -> Blink),存在缺少模块化,缺少封装,不可重入,非线程安全等诸多问题。Layout NG 项目 主要就是解决以上问题,该项目计划重构整个 Blink 排版相关代码,支持子树排版,多线程,将绘制部分移到其它线程等等。不过这个项目才刚刚开始,看起来任重而道远。
Slimming Paint
这是分享内容最多的,也作者一直以来比较关注的项目。合成图层的概念和架构是 Apple 最早引入 WebKit 的,当时主要是解决在图层内容没有发生变化的状况下,因为滚动,矩阵变换,透明变化等原因导致图层不断重复光栅化的问题。但是沿袭至今的处理逻辑,就是目前先排版,然后更新合成图层树,然后更新绘制,接下来再交由合成器在合成线程去做光栅化和合成的方式存在诸多问题,有绘制正确性的,也有性能的,Slimming Paint 项目就是为了解决上述问题。
问题的根源是在于合成图层树是由 Blink 根据排版的结果来生成的,而更合理的逻辑是由合成器根据绘制的结果,和当前帧的各个绘制元素的合成属性(滚动位置,变换矩阵等)来决定合成图层树。
目前存在的问题包括:
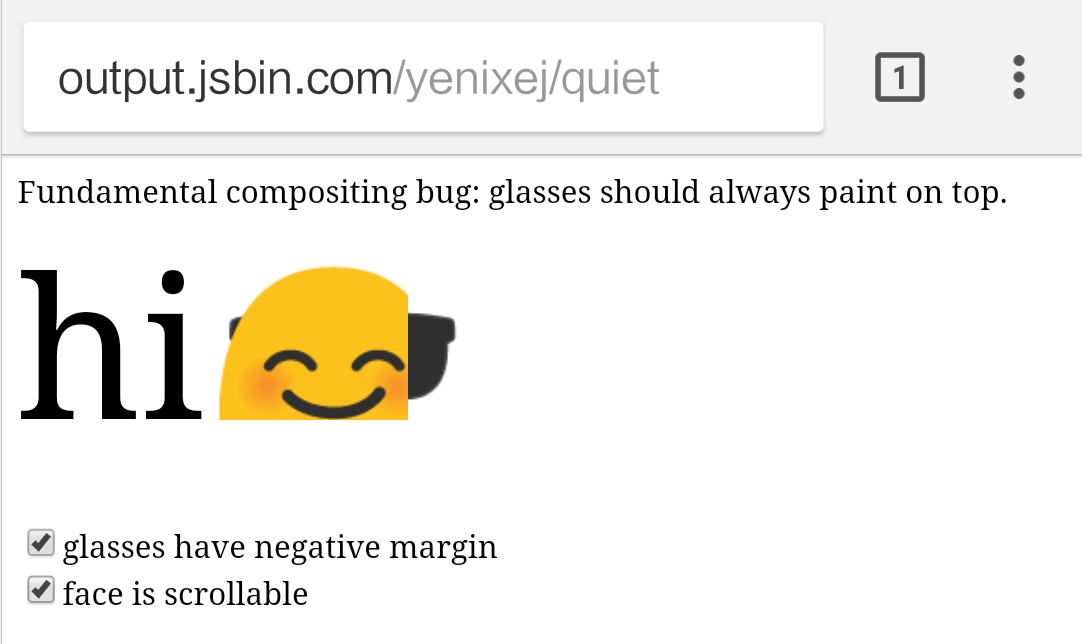
- 无法解决的根本性合成错误,因为单纯根据排版结果,需要提升成合成图层的排版对象缺少足够的信息而没有获得提升,导致遮挡错误。上图显示了一个这样的错误,可以使用移动版 Chrome 访问这个网站查看(PC 版的 Chrome 因为合成图层的生成策略跟移动版有些差异,所以该页面可能不会出错);
- 为了避免合成器动画过程中产生遮挡错误,不得不把潜在的所有可能会 Overlap 的排版对象都提升成合成图层,从而导致图层爆炸,占用了大量内存;
- 更新合成图层树占用了主线程的 CPU 时间,而主线程又比较拥挤,要做的事情很多,导致其它关键任务更容易被阻塞;
- 妨碍了合成器更好地平衡性能和内存占用,根据不同设备和页面来调整合成图层的生成策略;
- 妨碍了将更多动画交由合成器去运行,获得更好的动画性能;
解决上述问题的方法就是,Blink 只负责排版和绘制,绘制根据排版的结果来为每个排版对象生成 display list。合成器接收 Blink 传递的 display list 和合成属性树,自己来决定如何生成合适的合成图层树,在保证正确性的前提下,更好平衡性能和内存占用。
Slimming Paint 项目当前还在进行中,比较完整的里程碑实现会在今年的下半年完成。
Slimming Paint + Viz
可以预想一下当 Slimming Paint 和 Viz 都完成后的最终状态,浏览器的渲染流水线分布在 Renderer 进程和 Viz 进程:
- Renderer 进程的 Blink 对外输出 display list 和合成属性树,提供足够的数据描述页面绘制的内容;
- Renderer 进程将上述数据序列化后通过 IPC 发送到 Viz 进程;
- Viz 进程的合成器根据 display list 和合成属性树来决定合成图层树的结构,并对 display list 进行光栅化;
- Viz 进程的合成器将光栅化后的结果合成输出;

















 6700
6700

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









