







1、代码如下,该段代码爬取的是第 4 代英特尔® 至强® 可扩展处理器的列表。
import requests
from bs4 import BeautifulSoup
import pandas as pd
# 要爬取的URL
url = "https://ark.intel.com/content/www/cn/zh/ark/products/series/228622/4th-gen-intel-xeon-scalable-processors.html"
# 发送GET请求
response = requests.get(url)
# 检查请求是否成功
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
# 创建一个列表存储处理器信息
data = []
# 找到所有处理器的表格行
rows = soup.find_all('tr', class_='blank-table-row')
# 解析每一行处理器信息
for row in rows:
# 获取处理器名称
name = row.find('td', class_='ark-product-name').text.strip()
# 获取发行日期、核心数、最大频率、基础频率、缓存大小、TDP
release_date = row.find_all('td')[1].text.strip() # 发行日期
core_count = row.find_all('td')[2].text.strip() # 核心数
max_freq = row.find_all('td')[3].text.strip() # 最大频率
base_freq = row.find_all('td')[4].text.strip() # 基础频率
cache_size = row.find_all('td')[5].text.strip() # 缓存大小
tdp = row.find_all('td')[6].text.strip() # TDP
# 将数据加入列表
data.append([name, release_date, core_count, max_freq, base_freq, cache_size, tdp])
# 将数据转换为DataFrame
df = pd.DataFrame(data, columns=['处理器名称', '发行日期', '核心数', '最大频率', '基础频率', '缓存大小', 'TDP'])
# 导出到Excel文件
df.to_excel('intel_xeon_processors.xlsx', index=False, engine='openpyxl')
print("数据已成功导出到 intel_xeon_processors.xlsx")
else:
print(f"无法访问页面。状态码: {response.status_code}")
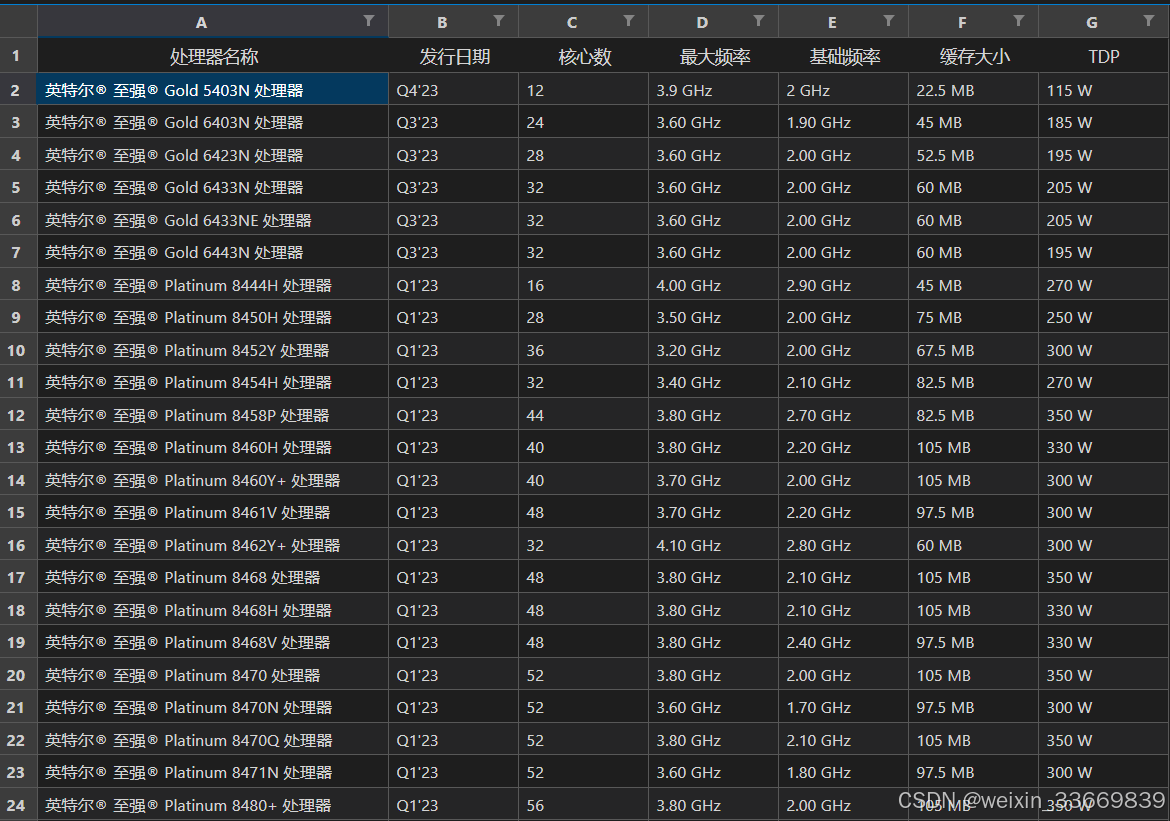
2、代码运行结束后,会在当前文件夹生成excel文件,打开即可查看。

















 1184
1184

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









