import xbot
from xbot import web
from xbot import print, sleep
from bs4 import BeautifulSoup
import pymysql
import os
import re
import csv
import hashlib
import tempfile
import PyPDF2
from PyPDF2 import PdfReader
from docx import Document
import win32com.client
import requests
import random
import time
import urllib3
from urllib3.exceptions import InsecureRequestWarning
import base64
# 禁用SSL警告
urllib3.disable_warnings(InsecureRequestWarning)
# ==================== 隧道代理配置 ====================
PROXY_HOST = "f606.kdltpspro.com"
PROXY_PORT = 15818
PROXY_USER = "t16181473250660"
PROXY_PASS = "98iw80lj"
PROXY_URL = f"http://{PROXY_USER}:{PROXY_PASS}@{PROXY_HOST}:{PROXY_PORT}"
print(f"🔧 代理配置: {PROXY_HOST}:{PROXY_PORT}")
# 设置系统代理环境变量(让xbot使用代理)
os.environ['HTTP_PROXY'] = PROXY_URL
os.environ['HTTPS_PROXY'] = PROXY_URL
os.environ['http_proxy'] = PROXY_URL
os.environ['https_proxy'] = PROXY_URL
# 数据库配置
DB_CONFIG = {
"host": "192.168.100.18",
"port": 3306,
"user": "yiyaoqixie",
"password": "123456",
"database": "yiyaoqixie", # 原为 "db" -> 应使用 "database"
"charset": "utf8mb4",
"cursorclass": pymysql.cursors.DictCursor
}
# 使用您的保存路径
SAVE_BASE_DIR = r"D:\作业\yaozhi"
if not os.path.exists(SAVE_BASE_DIR):
os.makedirs(SAVE_BASE_DIR, exist_ok=True)
print(f"📁 创建保存目录: {SAVE_BASE_DIR}")
def create_proxy_session():
"""创建带代理的requests session(仅用于附件下载)"""
session = requests.Session()
session.proxies = {
'http': PROXY_URL,
'https': PROXY_URL
}
auth_str = base64.b64encode(f"{PROXY_USER}:{PROXY_PASS}".encode()).decode()
session.headers.update({
'Proxy-Authorization': f'Basic {auth_str}',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36'
})
session.verify = False
session.trust_env = False
return session
# 轻量过滤函数
def clean_content_chars(text):
if not isinstance(text, str):
return ""
return ''.join([char for char in text if ord(char) <= 0xFFFF])
def md5_id(url):
return hashlib.md5(url.encode('utf-8')).hexdigest()
# 数据库连接
def get_mysql_conn():
try:
conn = pymysql.connect(
host=DB_CONFIG["host"],
port=DB_CONFIG["port"],
user=DB_CONFIG["user"],
password=DB_CONFIG["password"],
database=DB_CONFIG["database"],
charset=DB_CONFIG["charset"],
connect_timeout=10
)
return conn
except Exception as e:
print(f"❌ 数据库连接错误: {str(e)}")
return None
def test_proxy_connection():
"""测试代理连接"""
print("🔍 测试代理连接...")
try:
session = create_proxy_session()
response = session.get('http://httpbin.org/ip', timeout=20)
if response.status_code == 200:
ip_info = response.json()
current_ip = ip_info.get('origin', '未知')
print(f"✅ 代理连接成功,当前IP: {current_ip}")
return True
else:
print(f"❌ 代理测试失败,状态码: {response.status_code}")
return False
except Exception as e:
print(f"❌ 代理连接失败: {str(e)}")
return False
def download_attachment(attach_url, save_dir, attach_name):
"""下载附件文件"""
if not os.path.exists(save_dir):
try:
os.makedirs(save_dir, exist_ok=True)
except Exception as e:
print(f"❌ 创建目录失败: {str(e)}")
return ""
valid_name = re.sub(r'[\\/:*?"<>|]', "_", attach_name)
full_path = os.path.join(save_dir, valid_name)
try:
if attach_url.startswith(('http://', 'https://')):
full_attach_url = attach_url
else:
full_attach_url = f"https://db.yaozh.com{attach_url}"
print(f"📥 下载附件: {full_attach_url}")
session = create_proxy_session()
resp = session.get(full_attach_url, timeout=60, stream=True)
resp.raise_for_status()
with open(full_path, "wb") as f:
for chunk in resp.iter_content(chunk_size=1024):
if chunk:
f.write(chunk)
print(f"✅ 附件下载成功:{full_path}")
return full_path
except Exception as e:
print(f"❌ 附件下载失败[{valid_name}]: {str(e)[:80]}")
return ""
def read_attachment_content(attach_url):
"""读取附件内容(PDF、Word等)"""
content = ""
try:
session = create_proxy_session()
response = session.get(attach_url, timeout=60)
response.raise_for_status()
if attach_url.endswith(".pdf"):
with tempfile.NamedTemporaryFile(suffix=".pdf", delete=False) as temp_file:
temp_file.write(response.content)
temp_path = temp_file.name
reader = PdfReader(temp_path)
content = "\n".join([page.extract_text() for page in reader.pages if page.extract_text()])
os.unlink(temp_path)
elif attach_url.endswith(".docx"):
with tempfile.NamedTemporaryFile(suffix=".docx", delete=False) as temp_file:
temp_file.write(response.content)
temp_path = temp_file.name
doc = Document(temp_path)
content = "\n".join([para.text for para in doc.paragraphs])
os.unlink(temp_path)
elif attach_url.endswith(".doc"):
with tempfile.NamedTemporaryFile(suffix=".doc", delete=False) as temp_file:
temp_file.write(response.content)
temp_path = temp_file.name
word = win32com.client.Dispatch("Word.Application")
word.Visible = False
word.DisplayAlerts = 0
doc = word.Documents.Open(FileName=temp_path, Format=0)
content = doc.Range().Text.strip()
doc.Close(SaveChanges=0)
word.Quit()
os.unlink(temp_path)
except Exception as e:
print(f"❌ 附件内容读取失败: {str(e)[:50]}")
return clean_content_chars(content)
# ==================== 关键修改:恢复使用xbot的web模块 ====================
def get_page_links(page):
"""获取指定页面的文章链接 - 使用xbot真实点击进入页面"""
url = f"https://db.yaozh.com/policies?p={page}"
print(f"📄 正在爬取第{page}页链接: {url}")
try:
# 使用xbot的web模块真实打开浏览器
web_object = web.create(url, 'Microsoft Edge', load_timeout=60)
page_html = web_object.get_html()
soup = BeautifulSoup(page_html, 'html.parser')
hrefs = []
for th in soup.find_all('th'):
a_tag = th.find('a', class_='cl-blue')
if a_tag:
href = a_tag.get('href', '')
full_href = href if href.startswith(('http', 'https')) else f"https://db.yaozh.com{href}"
hrefs.append(full_href)
web_object.close()
print(f"第{page}页共提取{len(hrefs)}个链接")
return hrefs
except Exception as e:
print(f"❌ 获取第{page}页链接失败: {str(e)[:50]}")
return []
def parse_article(detail_url):
"""解析文章详情页内容 - 使用xbot真实点击进入详情页"""
data = {
"student": "李耀铭",
"title": "", "cat": "", "code": "", "public_date": "",
"content": "", "attachments": "", "url": detail_url,
"platform_id": md5_id(detail_url)
}
try:
print(f"开始请求详情页: {detail_url}")
# 使用xbot的web模块真实打开详情页
web_object = web.create(detail_url, 'Microsoft Edge', load_timeout=60)
page_html = web_object.get_html()
soup = BeautifulSoup(page_html, 'html.parser')
# 提取标题 - 完全保持您原来的代码
title_element = soup.find('h1', class_="title")
if title_element:
data["title"] = clean_content_chars(title_element.get_text().strip())
print(f"标题: {data['title'] or '未获取'}")
# 提取发布部门 - 完全保持您原来的代码
try:
depart_span = soup.find('span', string='【发布部门】')
if depart_span:
depart_div = depart_span.parent
data["cat"] = clean_content_chars(depart_div.get_text().split('】')[-1].strip())
except Exception as e:
print(f"发布部门提取失败: {e}")
# 提取发文字号/效力级别 - 完全保持您原来的代码
try:
code_span = soup.find('span', string='【发文字号】') or soup.find('span', string='【效力级别】')
if code_span:
code_div = code_span.parent
data["code"] = clean_content_chars(code_div.get_text().split('】')[-1].strip())
except Exception as e:
print(f"发文字号提取失败: {e}")
# 提取发布日期 - 完全保持您原来的代码
try:
date_span = soup.find('span', string='【发布日期】')
if date_span:
date_div = date_span.parent
data["public_date"] = clean_content_chars(date_div.get_text().split('】')[-1].strip())
except Exception as e:
print(f"发布日期提取失败: {e}")
# 提取正文 - 完全保持您原来的代码
content_elem = soup.find("div", class_="Three_xilan_07")
if not content_elem:
content_elem = soup.find("div", class_="new_detail_content") or soup.find("div", class_="text") or soup.find("div", class_="con")
if content_elem:
content_text = content_elem.get_text().strip()
content_text = re.sub(r'\s+', ' ', content_text)
data["content"] = clean_content_chars(content_text)
print(f"网页正文长度: {len(data['content'])}字符")
else:
print("未找到正文标签,正文为空")
# 处理附件 - 完全保持您原来的代码
attach_paths = []
attach_content_list = []
# 1. 优先从"相关附件"表格提取
attach_table = soup.find("table")
if attach_table:
for row in attach_table.find_all("tr")[1:]:
cols = row.find_all("td")
if len(cols) >= 2:
table_attach_name = cols[1].get_text().strip()
attach_link = cols[1].find("a")
if attach_link and table_attach_name:
attach_url = attach_link.get("href", "").strip()
print(f"从表格提取附件名称: {table_attach_name}")
if data["public_date"]:
save_dir = os.path.join(SAVE_BASE_DIR, data["public_date"])
local_path = download_attachment(attach_url, save_dir, table_attach_name)
if local_path:
relative_path = os.path.relpath(local_path, SAVE_BASE_DIR)
attach_paths.append(relative_path)
full_attach_url = attach_url if attach_url.startswith(('http', 'https')) else f"https://db.yaozh.com{attach_url}"
attach_content = read_attachment_content(full_attach_url)
if attach_content:
attach_content_list.append(f"【附件:{table_attach_name}】\n{attach_content}")
# 2. 若表格中无附件,从relatedNews提取
else:
related_news = soup.find("div", class_="relatedNews")
if related_news:
attach_links = related_news.select("a[href$='.pdf'], a[href$='.docx'], a[href$='.doc']")
if attach_links and data["public_date"]:
save_dir = os.path.join(SAVE_BASE_DIR, data["public_date"])
for link in attach_links:
attach_name = link.get("title") or link.get_text().strip()
if not attach_name:
attach_name = link.get("href", "").split("/")[-1] or f"未命名附件_{len(attach_paths)+1}"
attach_url = link.get("href", "").strip()
print(f"从relatedNews提取附件名称: {attach_name}")
local_path = download_attachment(attach_url, save_dir, attach_name)
if local_path:
relative_path = os.path.relpath(local_path, SAVE_BASE_DIR)
attach_paths.append(relative_path)
full_attach_url = attach_url if attach_url.startswith(('http', 'https')) else f"https://db.yaozh.com{attach_url}"
attach_content = read_attachment_content(full_attach_url)
if attach_content:
attach_content_list.append(f"【附件:{attach_name}】\n{attach_content}")
# 合并附件内容到正文
if attach_content_list:
data["content"] += "\n\n" + "\n\n".join(attach_content_list)
data["attachments"] = ",".join(attach_paths) if attach_paths else ""
print(f"附件路径: {data['attachments'] or '无附件'}")
web_object.close()
except Exception as e:
print(f"❌ 文章解析异常: {str(e)[:80]}")
return data
def save_article(data):
"""保存文章数据到数据库"""
if not data["title"] or not data["url"]:
print("标题或URL为空,跳过入库")
return False
try:
conn = get_mysql_conn()
cursor = conn.cursor()
cursor.execute("""
INSERT INTO yaozh_policies (
student, title, cat, code, public_date, content, attachments, url, platform_id
) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s)
ON DUPLICATE KEY UPDATE
title = VALUES(title),
cat = VALUES(cat),
code = VALUES(code),
public_date = VALUES(public_date),
content = VALUES(content),
attachments = VALUES(attachments),
url = VALUES(url)
""", (
data["student"],
data["title"],
data["cat"] or "",
data["code"] or "",
data["public_date"] or "",
data["content"] or "",
data["attachments"] or "",
data["url"],
data["platform_id"]
))
conn.commit()
if cursor.rowcount == 1:
print(f"✅ 数据入库成功:{data['title'][:20]}")
elif cursor.rowcount == 2:
print(f"🔄 数据更新成功:{data['title'][:20]}")
cursor.close()
conn.close()
return True
except Exception as e:
if 'conn' in locals():
conn.rollback()
print(f"❌ 数据入库失败[{data['title'][:20]}]: {str(e)[:60]}")
return False
def export_to_csv(csv_path, data_list):
if not data_list:
print("无数据可导出到CSV")
return
with open(csv_path, "w", encoding="utf-8-sig", newline="") as f:
headers = ["student", "title", "cat", "code", "public_date", "content", "attachments", "url", "platform_id"]
writer = csv.DictWriter(f, fieldnames=headers)
writer.writeheader()
for row in data_list:
writer.writerow({k: row[k] if row[k] is not None else "" for k in headers})
print(f"CSV导出成功:{csv_path}(共{len(data_list)}条数据)")
def main(params=None):
print("===== 药智数据政策法规爬虫启动 =====")
print(f"使用代理: {PROXY_HOST}:{PROXY_PORT}")
print(f"📁 保存目录: {SAVE_BASE_DIR}")
# 测试代理连接
if not test_proxy_connection():
print("⚠️ 代理连接测试失败,但程序将继续运行")
total_pages = 2
all_data = []
success_count = 0
fail_count = 0
for page in range(1, total_pages + 1):
try:
# 页面间随机延迟
page_delay = random.uniform(4, 10)
print(f"页面间延迟 {page_delay:.2f} 秒")
time.sleep(page_delay)
hrefs = get_page_links(page)
if not hrefs:
print(f"第{page}页无有效链接,跳过")
continue
for idx, detail_url in enumerate(hrefs, 1):
print(f"\n----- 处理第{page}页第{idx}篇: {detail_url[:60]} -----")
article_data = parse_article(detail_url)
if article_data["title"]:
if save_article(article_data):
all_data.append(article_data)
success_count += 1
else:
fail_count += 1
else:
print("文章标题为空,跳过保存")
fail_count += 1
# 文章间随机延迟
article_delay = random.uniform(3, 6)
print(f"文章间延迟 {article_delay:.2f} 秒")
time.sleep(article_delay)
except Exception as e:
print(f"第{page}页处理失败: {str(e)[:100]}")
fail_count += 1
error_delay = random.uniform(20, 30)
print(f"出错后等待 {error_delay:.2f} 秒")
time.sleep(error_delay)
csv_path = os.path.join(SAVE_BASE_DIR, "all.csv")
export_to_csv(csv_path, all_data)
print("\n===== 程序执行完毕 =====")
print(f"✅ 成功爬取: {success_count} 篇")
print(f"❌ 失败数量: {fail_count} 篇")
print(f"📊 CSV已导出至: {csv_path}")
return f"爬取完成:成功{success_count}篇,失败{fail_count}篇"
if __name__ == "__main__":
main()查看代码的问题




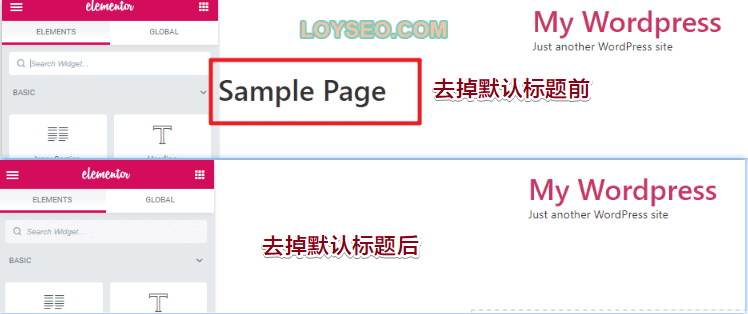
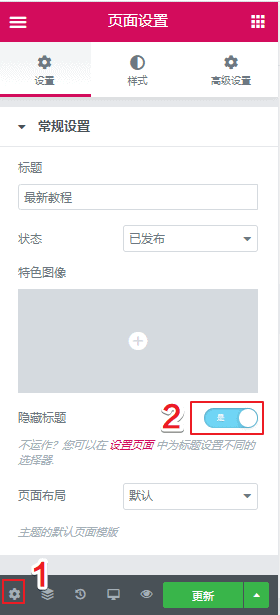
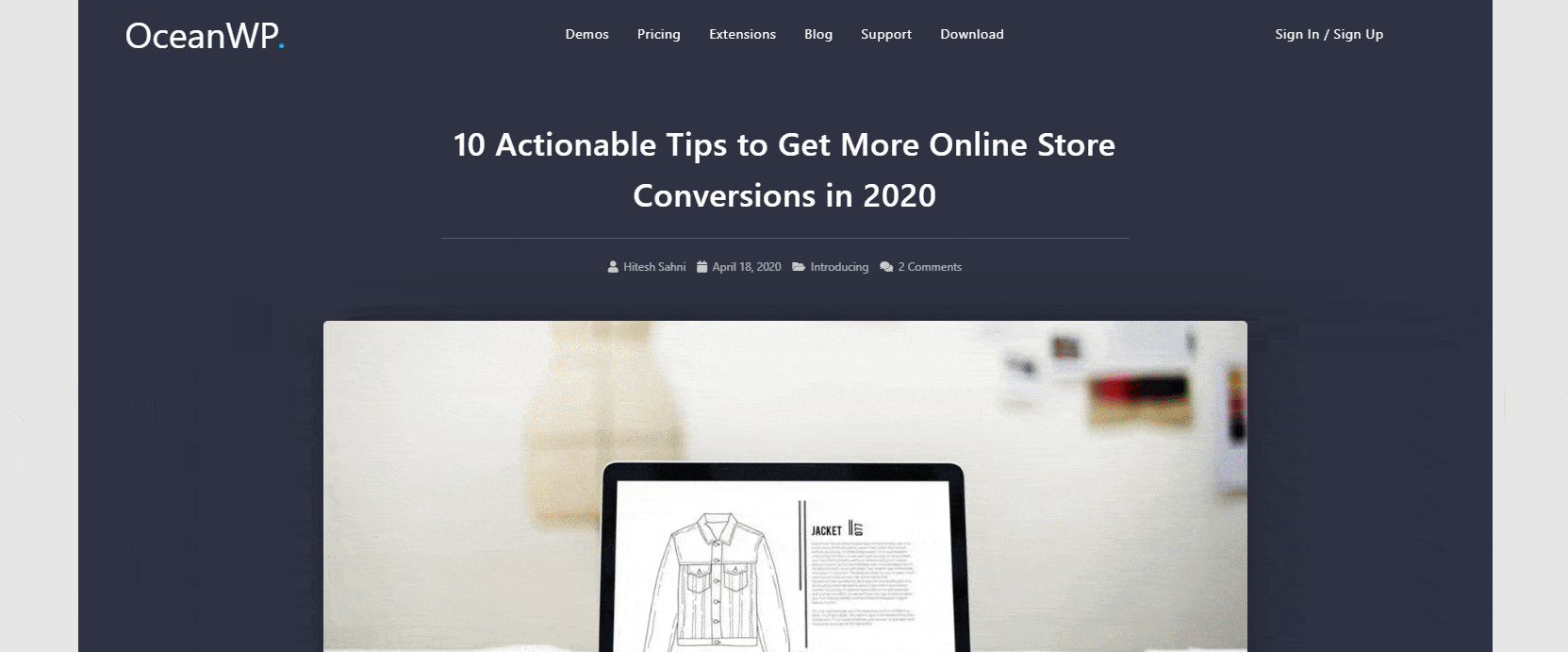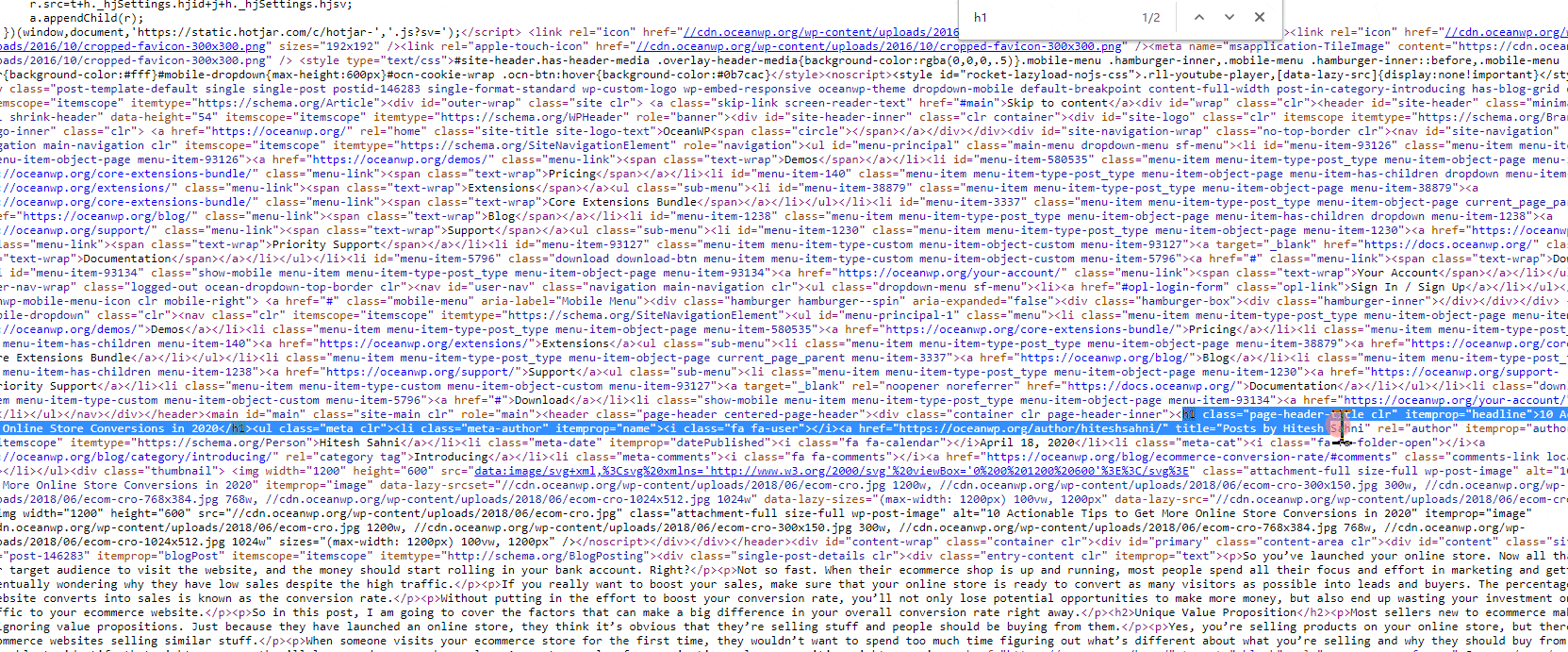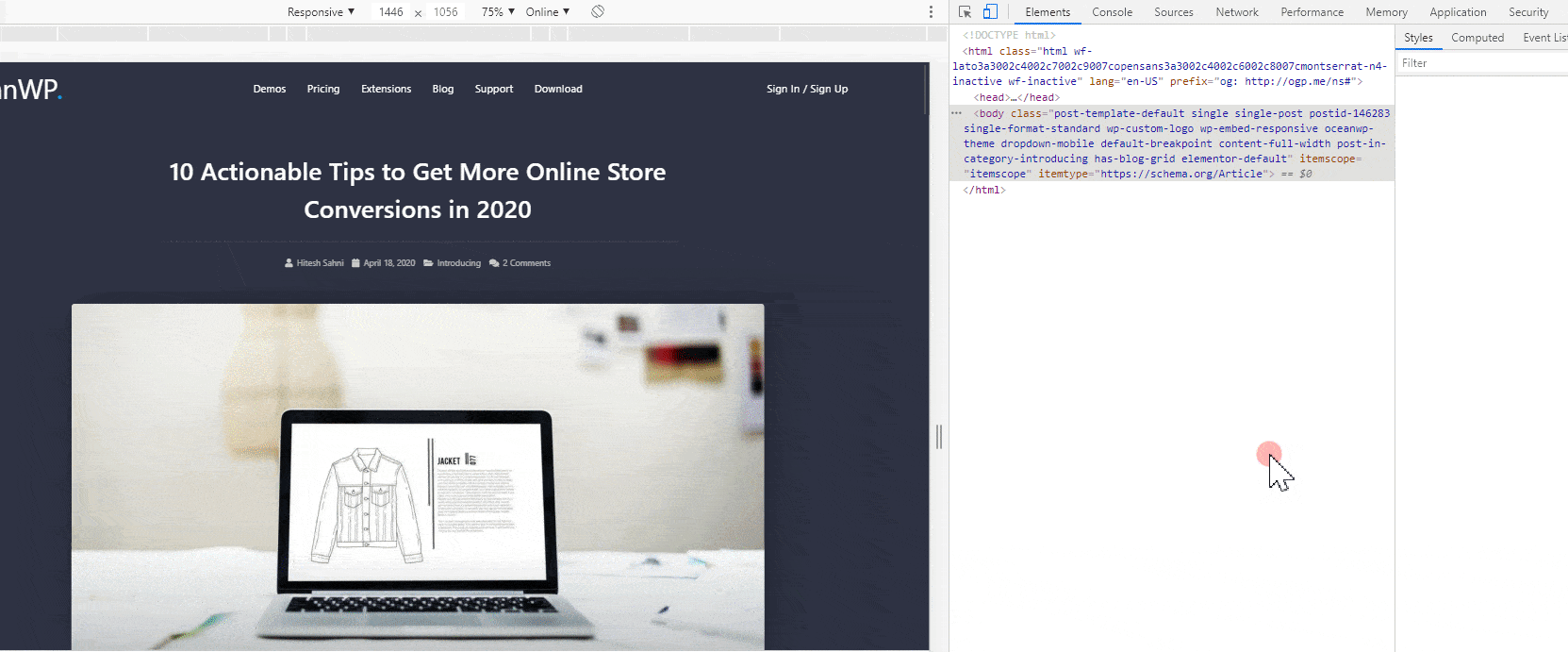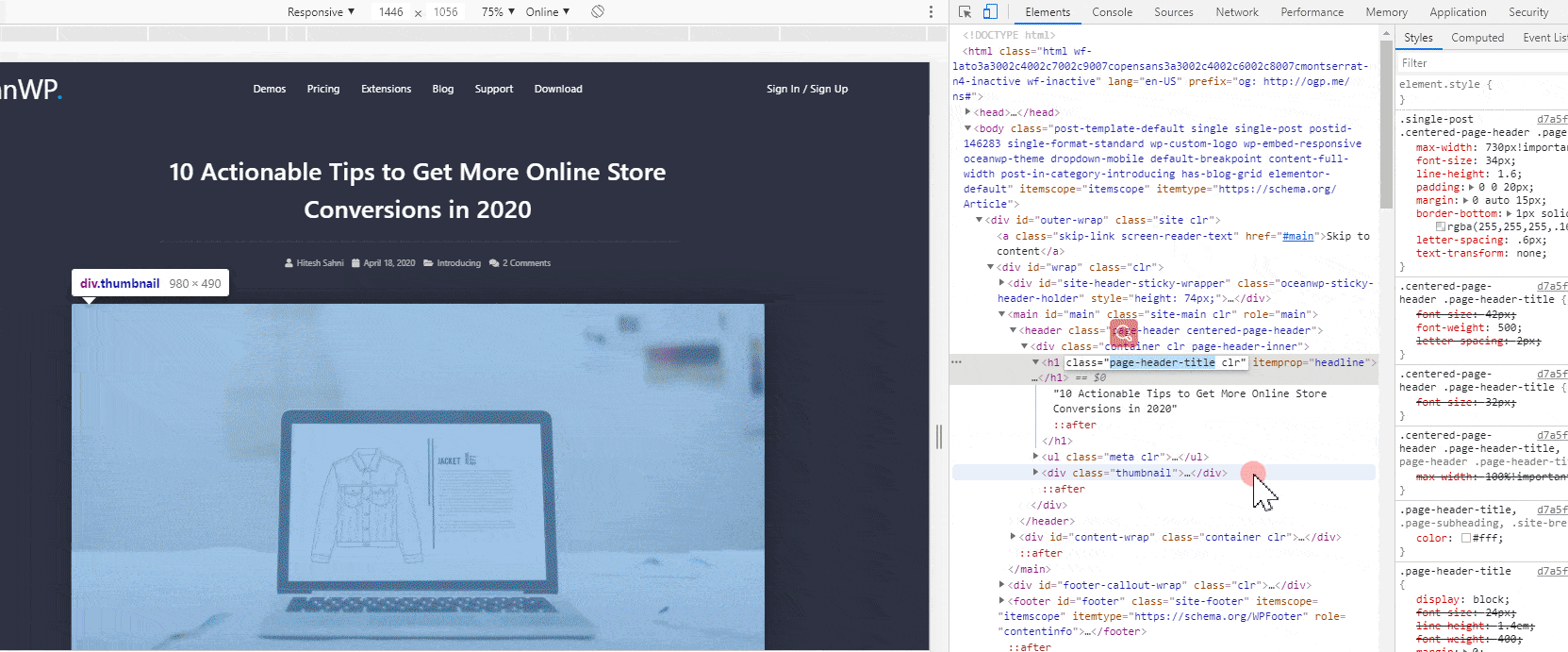
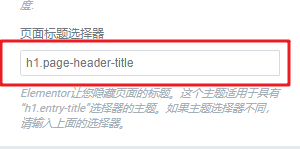
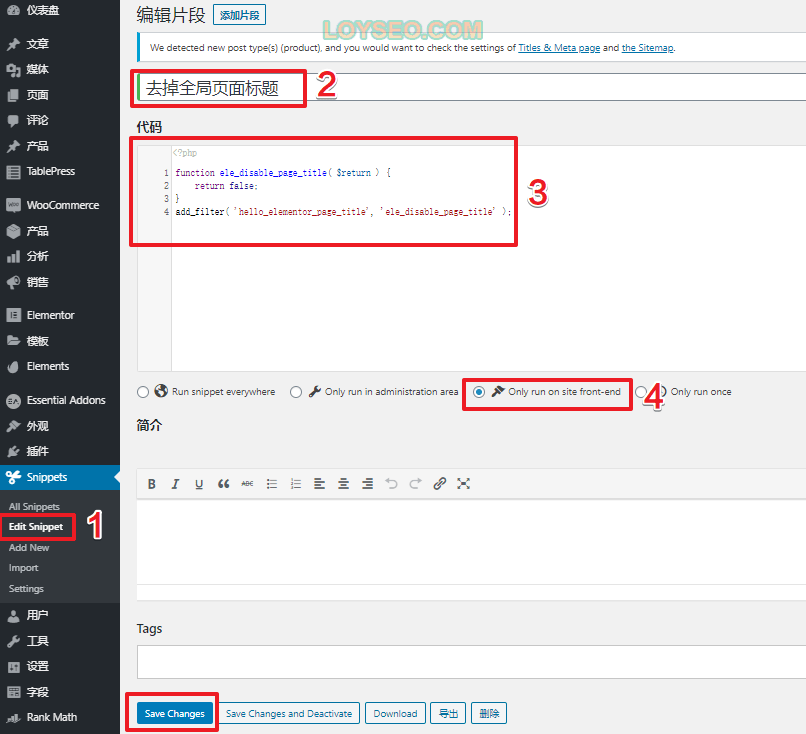
 本文详述了两种在Elementor中隐藏页面标题的方法,包括单个页面隐藏和全局隐藏,尤其适用于Hello Elementor和Astra主题。通过Elementor编辑器设置或使用Code snippets插件实现禁用标题,确保页面呈现更整洁的布局。
本文详述了两种在Elementor中隐藏页面标题的方法,包括单个页面隐藏和全局隐藏,尤其适用于Hello Elementor和Astra主题。通过Elementor编辑器设置或使用Code snippets插件实现禁用标题,确保页面呈现更整洁的布局。

















 5458
5458

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









