






 本文是关于华盛顿共享单车需求预测的Kaggle项目,通过收集、准备、分析数据,选择特征值和模型,预测共享单车的租赁需求。项目涉及数据包括日期、天气、季节、节假日等信息,对数据进行了异常值处理和特征工程,最终通过随机森林模型进行预测。
本文是关于华盛顿共享单车需求预测的Kaggle项目,通过收集、准备、分析数据,选择特征值和模型,预测共享单车的租赁需求。项目涉及数据包括日期、天气、季节、节假日等信息,对数据进行了异常值处理和特征工程,最终通过随机森林模型进行预测。

目录
1 数据收集
1.1 项目说明
1.2 数据内容说明
1.3 提出问题
1.4 变量说明2 数据准备
2.1 检查缺失值
2.2 检查并处理异常值3 分析数据
3.1 整体观察
3.2 逐项展示4. 选择特征值5. 选择模型、训练模型6. 预测测试集数据
1.收集数据:
数据下载自Kaggle
https://www.kaggle.com/c/bike-sharing-demand
1.1 项目说明
自行车共享系统是一种租赁自行车的方法,注册会员、租车、还车都将通过城市中的站点网络自动完成,通过这个系统人们可以根据需要从一个地方租赁一辆自行车然后骑到自己的目的地归还。
在这次比赛中,参与者需要结合历史天气数据下的使用模式,来预测D.C.华盛顿首都自行车共享项目的自行车租赁需求。
1.2 数据内容说明
比赛提供了跨越两年的每小时租赁数据,包含天气信息和日期信息,
训练集由每月前19天的数据组成,测试集是每月第二十天到当月底的数据。
1.3 提出问题
通过测试集中的天气等特征值预测共享单车在华盛顿的需求,即预测会员租赁数量,临时租赁数量和总租赁数量。
1.4 变量说明
datetime(日期) - hourly date + timestamp
season(季节) - 1 = spring, 2 = summer, 3 = fall, 4 = winter
holiday(是否假日) - whether the day is considered a holiday
workingday(是否工作日) - whether the day is neither a weekend nor holiday
weather(天气等级) -
1. 清澈,少云,多云。
2. 雾+阴天,雾+碎云、雾+少云、雾
3. 小雪、小雨+雷暴+散云,小雨+云
4. 暴雨+冰雹+雷暴+雾,雪+雾
temp(温度) - temperature in Celsius
atemp(体感温度) - "feels like" temperature in Celsius
humidity(相对湿度) - relative humidity
windspeed(风速) - wind speed
casual(临时租赁数量) - number of non-registered user rentals initiated
registered(会员租赁数量) - number of registered user rentals initiated
count(总租赁数量) - number of total rentals
2.准备数据:
2.1检查缺失值
%matplotlib inline
import numpy as np
import pandas as pd
from datetime import datetime
import warnings
warnings.filterwarnings('ignore')
import matplotlib.pyplot as plt
import seaborn as sns
sns.set(style='whitegrid' , palette='tab10')
train=pd.read_csv('train.csv')
#查看训练集数据是否有缺失值
train.info()输出
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 10886 entries, 0 to 10885
Data columns (total 12 columns):
datetime 10886 non-null object
season 10886 non-null int64
holiday 10886 non-null int64
workingday 10886 non-null int64
weather 10886 non-null int64
temp 10886 non-null float64
atemp 10886 non-null float64
humidity 10886 non-null int64
windspeed 10886 non-null float64
casual 10886 non-null int64
registered 10886 non-null int64
count 10886 non-null int64
dtypes: float64(3), int64(8), object(1)
memory usage: 1020.6+ KB#查看测试集数据是否有缺失值
test=pd.read_csv('test.csv')
test.info()输出
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 6493 entries, 0 to 6492
Data columns (total 9 columns):
datetime 6493 non-null object
season 6493 non-null int64
holiday 6493 non-null int64
workingday 6493 non-null int64
weather 6493 non-null int64
temp 6493 non-null float64
atemp 6493 non-null float64
humidity 6493 non-null int64
windspeed 6493 non-null float64
dtypes: float64(3), int64(5), object(1)
memory usage: 456.6+ KB本数据集没有缺失数据,但没有缺失不代表没有异常。
2.2 检查异常值
#观察训练集数据描述统计
train.describe()输出
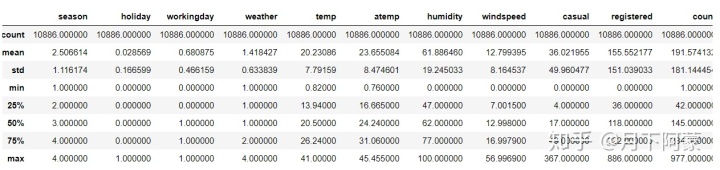
先从数值型数据入手,可以看出租赁额(count)数值差异大,所以希望观察一下它们的密度分布
#观察租赁额密度分布
fig = plt.figure()
ax = fig.add_subplot(1, 1, 1)
fig.set_size_inches(6,5)
sns.distplot(train['count'])
ax.set(xlabel='count',title='Distribution of count',)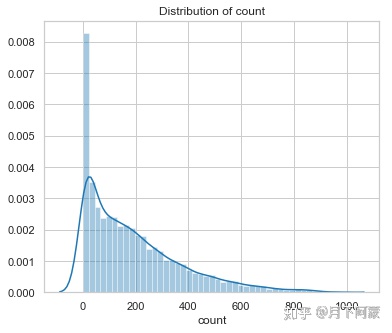
分布偏斜比较严重,所以希望能把这一列数据的异常值处理一下,首先排除掉3个标准差以外的数据.
train_WithoutOutliers = train[np.abs(train['count']-
train['count'].mean())<=(3*train['count'].std())]
train_WithoutOutliers .shape输出
(10739, 12)观察去除3个标准差之后的租赁额统计描述
train_WithoutOutliers['count'] .describe()输出
count 10739.000000
mean 183.003818
std 166.681429
min 1.000000
25% 41.000000
50% 141.000000
75% 276.000000
max 734.000000
Name: count, dtype: float64看下去掉3个标准差以外数据后的密度分布
fig = plt.figure()
ax1 = fig.add_subplot(1, 2, 1)
ax2 = fig.add_subplot(1, 2, 2)
fig.set_size_inches(12,5)
sns.distplot(train_WithoutOutliers['count'],ax=ax1)
sns.distplot(train['count'],ax=ax2)
ax1.set(xlabel='count',title='Distribution of count without outliers',)
ax2.set(xlabel='registered',title='Distribution of count')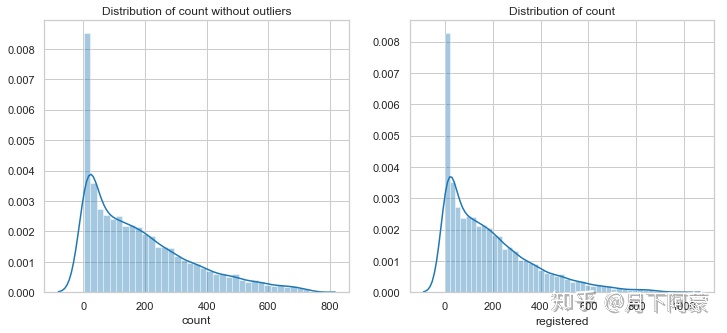
可以看到数据波动依然很大,而我们希望波动相对稳定,否则容易产生过拟合,
所以希望对数据进行变换,使得数据相对稳定,选择对数变化,来完成这项任务
yLabels=train_WithoutOutliers['count']
yLabels_log=np.log(yLabels)
sns.distplot(yLabels_log)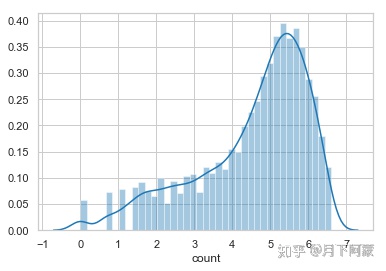
经过对数变换后数据分布更均匀,大小差异也缩小了,使用这样的标签对训练模型是有益的,
接下来对其余的数值型数据进行处理,由于其他数据同时包含在两个数据集中,
为方便数据处理先将两个数据集合并。
Bike_data=pd.concat([train_WithoutOutliers,test],ignore_index=True)
#查看数据集大小
Bike_data.shape输出
(17232, 12)观察数据结构
Bike_data.head()
因为最终需要使用随机森林预测,并且为了方便查可视化数据,先把datetime拆分成成日期、时段、年份、月份、星期 五列
Bike_data['date']=Bike_data.datetime.apply( lambda c : c.split( )[0])
Bike_data['hour']=Bike_data.datetime.apply( lambda c : c.split( )[1].split(':')[0]).astype('int')
Bike_data['year']=Bike_data.datetime.apply( lambda c : c.split( )[0].split('-')[0]).astype('int')
Bike_data['month']=Bike_data.datetime.apply( lambda c : c.split( )[0].split('-')[1]).astype('int')
Bike_data['weekday']=Bike_data.date.apply( lambda c : datetime.strptime(c,'%Y-%m-%d').isoweekday())
Bike_data.head()
观察上面的数据可以看到temp(温度),atemp(体感温度),humidity(湿度)、windspeed(风速)这四列也属于数值型数据,同样可以查看一下它们的分布。
fig, axes = plt.subplots(2, 2)
fig.set_size_inches(12,10)
sns.distplot(Bike_data['temp'],ax=axes[0,0])
sns.distplot(Bike_data['atemp'],ax=axes[0,1])
sns.distplot(Bike_data['humidity'],ax=axes[1,0])
sns.distplot(Bike_data['windspeed'],ax=axes[1,1])
axes[0,0].set(xlabel='temp',title='Distribution of temp',)
axes[0,1].set(xlabel='atemp',title='Distribution of atemp')
axes[1,0].set(xlabel='humidity',title='Distribution of humidity')
axes[1,1].set(xlabel='windspeed',title='Distribution of windspeed')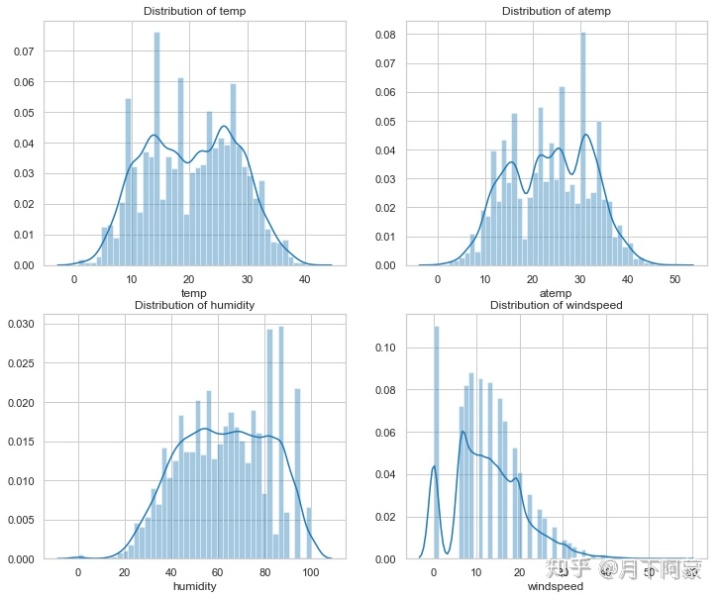
通过这个分布可以发现一些问题,比如风速为什么0的数据很多,而观察统计描述发现空缺值在1--6之间,从这里似乎可以推测,数据本身或许是有缺失值的,但是用0来填充了,但这些风速为0的数据会对预测产生干扰,希望使用随机森林根据相同的年份,月份,季节,温度,湿度等几个特征来填充一下风速的缺失值。
填充之前看一下非零数据的描述统计。
Bike_data[Bike_data['windspeed']!=0]['windspeed'].describe()输出
count 15068.000000
mean 14.556762
std 7.092624
min 6.003200
25% 8.998100
50% 12.998000
75% 19.001200
max 56.996900
Name: windspeed, dtype: float64使用随机森林填充风速
from sklearn.ensemble import RandomForestRegressor
Bike_data["windspeed_rfr"]=Bike_data["windspeed"]
# 将数据分成风速等于0和不等于两部分
dataWind0 = Bike_data[Bike_data["windspeed_rfr"]==0]
dataWindNot0 = Bike_data[Bike_data["windspeed_rfr"]!=0]
#选定模型
rfModel_wind = RandomForestRegressor(n_estimators=1000,random_state=42)
# 选定特征值
windColumns = ["season","weather","humidity","month","temp","year","atemp"]
# 将风速不等于0的数据作为训练集,fit到RandomForestRegressor之中
rfModel_wind.fit(dataWindNot0[windColumns], dataWindNot0["windspeed_rfr"])
#通过训练好的模型预测风速
wind0Values = rfModel_wind.predict(X= dataWind0[windColumns])
#将预测的风速填充到风速为零的数据中
dataWind0.loc[:,"windspeed_rfr"] = wind0Values
#连接两部分数据
Bike_data = dataWindNot0.append(dataWind0)
Bike_data.reset_index(inplace=True)
Bike_data.drop('index',inplace=True,axis=1)填充好再画图观察一下这四个特征值的密度分布
fig, axes = plt.subplots(2, 2)
fig.set_size_inches(12,10)
sns.distplot(Bike_data['temp'],ax=axes[0,0])
sns.distplot(Bike_data['atemp'],ax=axes[0,1])
sns.distplot(Bike_data['humidity'],ax=axes[1,0])
sns.distplot(Bike_data['windspeed_rfr'],ax=axes[1,1])
axes[0,0].set(xlabel='temp',title='Distribution of temp',)
axes[0,1].set(xlabel='atemp',title='Distribution of atemp')
axes[1,0].set(xlabel='humidity',title='Distribution of humidity')
axes[1,1].set(xlabel='windseed',title='Distribution of windspeed')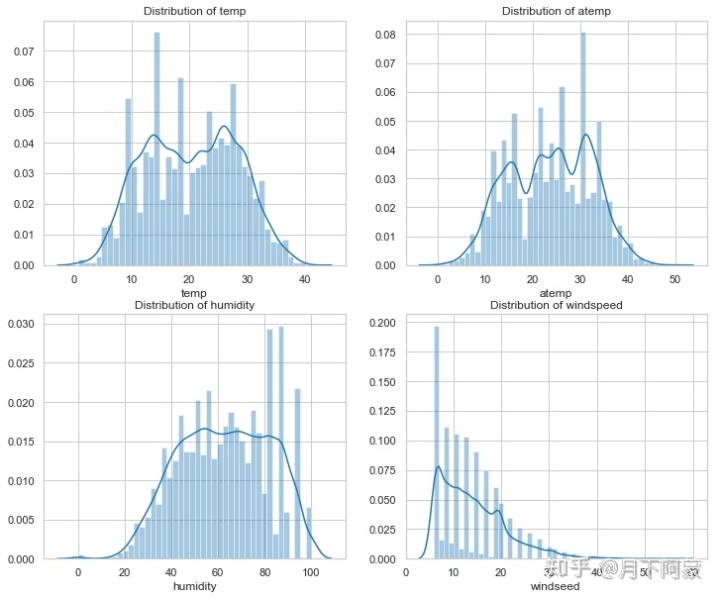
通过随机森林填充处理好了。
3.分析数据:
可视化并观察数据
3.1 整体观察
问题是希望预测每小时总租赁额,首先整体看一下租赁额相关的三个值和其他特征值的关系。
sns.pairplot(Bike_data ,x_vars=['holiday','workingday','weather','season',
'weekday','hour','windspeed_rfr','humidity','temp','atemp'] ,
y_vars=['casual','registered','count'] , plot_kws={'alpha': 0.1})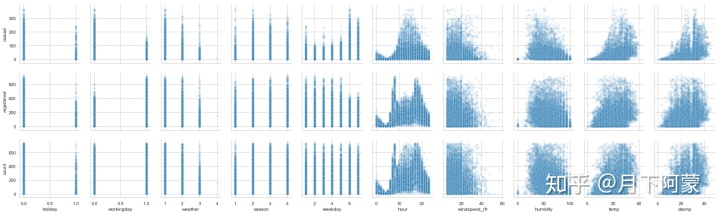
大致可以看出:
1.会员在工作日出行多,节假日出行少,临时用户则相反;
2.一季度出行人数总体偏少;
3.租赁数量随天气等级上升而减少;
4.小时数对租赁情况影响明显,会员呈现两个高峰,非会员呈现一个正态分布;
5.租赁数量随风速增大而减少;
6.温度、湿度对非会员影响比较大,对会员影响较小
下面查看各个特征与每小时租车总量(count)的相关性,由于上图可以看出特征值与租车数量基本是线性相关,所以求他们的线性相关系数
#相关性矩阵
corrDf = Bike_data.corr()
#ascending=False表示按降序排列
corrDf['count'].sort_values(ascending =False)输出
count 1.000000
registered 0.966209
casual 0.704764
hour 0.405437
temp 0.385954
atemp 0.381967
year 0.234959
month 0.164673
season 0.159801
windspeed_rfr 0.111783
windspeed 0.106074
weekday 0.022602
holiday 0.002978
workingday -0.020764
weather -0.127519
humidity -0.317028
Name: count, dtype: float64可以看出特征值对租赁数量的影响力度为,时段>温度>湿度>年份>月份>季节>天气等级>风速>星期几>是否工作日>是否假日,接下来再看一下共享单车整体使用情况。
3.2 逐项展示
3.2.1 时段对租赁数量的影响
因为时段对租赁数量的影响最大首先展示这一项数据
workingday_df=Bike_data[Bike_data['workingday']==1]
workingday_df = workingday_df.groupby(['hour'], as_index=True).agg({'casual':'mean',
'registered':'mean',
'count':'mean'})
nworkingday_df=Bike_data[Bike_data['workingday']==0]
nworkingday_df = nworkingday_df.groupby(['hour'], as_index=True).agg({'casual':'mean',
'registered':'mean',
'count':'mean'})
fig, axes = plt.subplots(1, 2,sharey = True)
workingday_df.plot(figsize=(15,5),title = 'The average number of rentals initiated
per hour in the working day',ax=axes[0])
nworkingday_df.plot(figsize=(15,5),title = 'The average number of rentals initiated
per hour in the nonworkdays',ax=axes[1])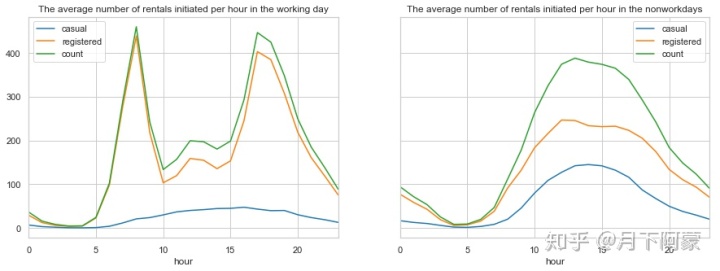
通过对比可以看到:
1.工作日对于会员用户上下班时间是两个用车高峰,而中午也会有一个小高峰,猜测可能是外出午餐的人;
2.而对临时用户起伏比较平缓,高峰期在17点左右;
3.并且会员用户的用车数量远超过临时用户。
4.对非工作日而言租赁数量随时间呈现一个正态分布,高峰在14点左右,低谷在4点左右,且分布比较均匀。
3.2.2 温度对租赁数量的影响
先观察温度的走势
#数据按小时统计展示起来太麻烦,希望能够按天汇总取一天的气温中位数
temp_df = Bike_data.groupby(['date','weekday'], as_index=False).agg({'year':'mean',
'month':'mean',
'temp':'median'})
#由于测试数据集中没有租赁信息,会导致折线图有断裂,所以将缺失的数据丢弃
temp_df.dropna ( axis = 0 , how ='any', inplace = True )
#预计按天统计的波动仍然很大,再按月取日平均值
temp_month = temp_df.groupby(['year','month'], as_index=False).agg({'weekday':'min',
'temp':'median'})
#将按天求和统计数据的日期转换成datetime格式
temp_df['date']=pd.to_datetime(temp_df['date'])
#将按月统计数据设置一列时间序列
temp_month.rename(columns={'weekday':'day'},inplace=True)
temp_month['date']=pd.to_datetime(temp_month[['year','month','day']])
#设置画框尺寸
fig = plt.figure(figsize=(18,6))
ax = fig.add_subplot(1,1,1)
#使用折线图展示总体租赁情况(count)随时间的走势
plt.plot(temp_df['date'] , temp_df['temp'] , linewidth=1.3 , label='Daily average')
ax.set_title('Change trend of average temperature per day in two years')
plt.plot(temp_month['date'] , temp_month['temp'] , marker='o', linewidth=1.3 ,
label='Monthly average')
ax.legend()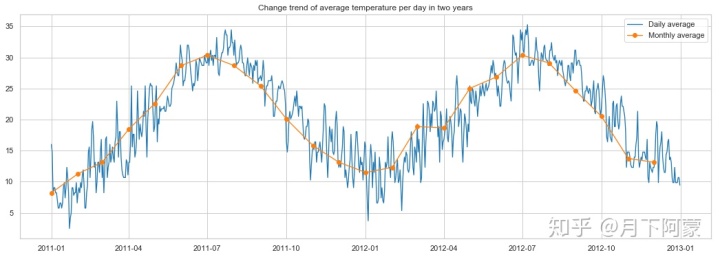
可以看出每年的气温趋势相同随月份变化,在7月份气温最高,1月份气温最低,再看一下每小时平均租赁数量随温度变化的趋势
#按温度取租赁额平均值
temp_rentals = Bike_data.groupby(['temp'], as_index=True).agg({'casual':'mean',
'registered':'mean',
'count':'mean'})
temp_rentals .plot(title = 'The average number of rentals initiated
per hour changes with the temperature')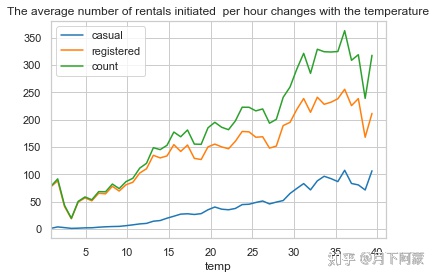
可观察到随气温上升租车数量总体呈现上升趋势,但在气温超过35时开始下降,在气温4度时达到最低点。
3.2.3 湿度对租赁数量的影响
先观察湿度的走势
humidity_df = Bike_data.groupby('date', as_index=False).agg({'humidity':'mean'})
humidity_df['date']=pd.to_datetime(humidity_df['date'])
#将日期设置为时间索引
humidity_df=humidity_df.set_index('date')
humidity_month = Bike_data.groupby(['year','month'], as_index=False).agg({'weekday':'min',
'humidity':'mean'})
humidity_month.rename(columns={'weekday':'day'},inplace=True)
humidity_month['date']=pd.to_datetime(humidity_month[['year','month','day']])
fig = plt.figure(figsize=(18,6))
ax = fig.add_subplot(1,1,1)
plt.plot(humidity_df.index , humidity_df['humidity'] , linewidth=1.3,label='Daily average')
plt.plot(humidity_month['date'], humidity_month['humidity'] ,marker='o',
linewidth=1.3,label='Monthly average')
ax.legend()
ax.set_title('Change trend of average humidity per day in two years')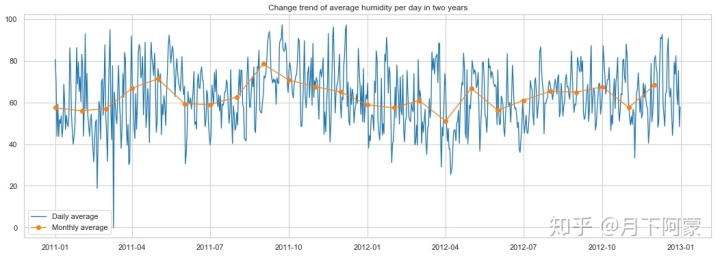
观察一下租赁人数随湿度变化趋势,按湿度对租赁数量取平均值。
humidity_rentals = Bike_data.groupby(['humidity'], as_index=True).agg({'casual':'mean',
'registered':'mean',
'count':'mean'})
humidity_rentals .plot (title = 'Average number of rentals initiated
per hour in different humidity')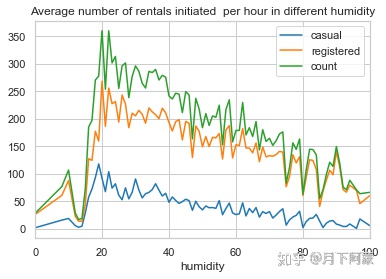
可以观察到在湿度20左右租赁数量迅速达到高峰值,此后缓慢递减。
3.2.4 年份、月份对租赁数量的影响
先观察两年时间里,总租车数量随时间变化的趋势
#数据按小时统计展示起来太麻烦,希望能够按天汇总
count_df = Bike_data.groupby(['date','weekday'], as_index=False).agg({'year':'mean',
'month':'mean',
'casual':'sum',
'registered':'sum',
'count':'sum'})
#由于测试数据集中没有租赁信息,会导致折线图有断裂,所以将缺失的数据丢弃
count_df.dropna ( axis = 0 , how ='any', inplace = True )
#预计按天统计的波动仍然很大,再按月取日平均值
count_month = count_df.groupby(['year','month'], as_index=False).agg({'weekday':'min',
'casual':'mean',
'registered':'mean',
'count':'mean'})
#将按天求和统计数据的日期转换成datetime格式
count_df['date']=pd.to_datetime(count_df['date'])
#将按月统计数据设置一列时间序列
count_month.rename(columns={'weekday':'day'},inplace=True)
count_month['date']=pd.to_datetime(count_month[['year','month','day']])
#设置画框尺寸
fig = plt.figure(figsize=(18,6))
ax = fig.add_subplot(1,1,1)
#使用折线图展示总体租赁情况(count)随时间的走势
plt.plot(count_df['date'] , count_df['count'] , linewidth=1.3 , label='Daily average')
ax.set_title('Change trend of average number of rentals initiated per day in two years')
plt.plot(count_month['date'] , count_month['count'] , marker='o',
linewidth=1.3 , label='Monthly average')
ax.legend()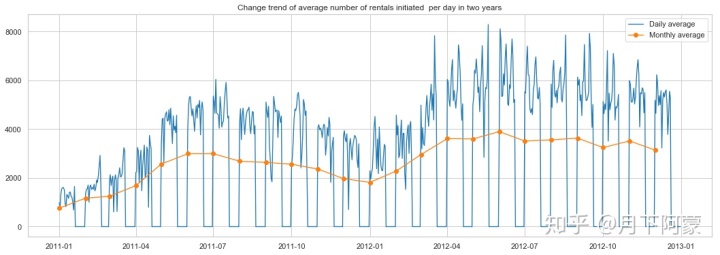
可以看出:
1.共享单车的租赁情况2012年整体是比2011年有增涨的;
2.租赁情况随月份波动明显;
3.数据在2011年9到12月,2012年3到9月间波动剧烈;
3.有很多局部波谷值。
3.2.5 季节对出行人数的影响
上图中的数据存在很多局部低谷,所以将租赁数量按季节取中位数展示,同时观察季节的温度变化
day_df=Bike_data.groupby('date').agg({'year':'mean','season':'mean',
'casual':'sum', 'registered':'sum'
,'count':'sum','temp':'mean',
'atemp':'mean'})
season_df = day_df.groupby(['year','season'], as_index=True).agg({'casual':'mean',
'registered':'mean',
'count':'mean'})
temp_df = day_df.groupby(['year','season'], as_index=True).agg({'temp':'mean',
'atemp':'mean'})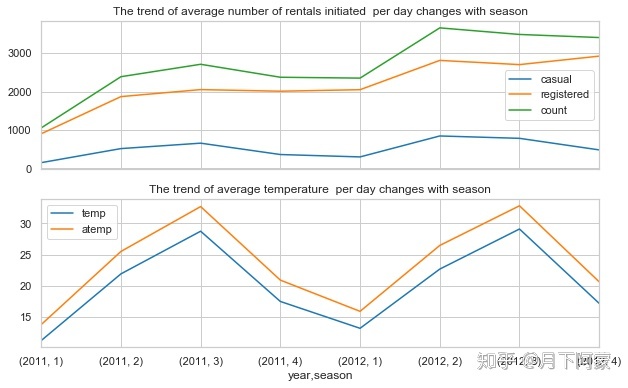
可以看出无论是临时用户还是会员用户用车的数量都在秋季迎来高峰,而春季度用户数量最低
3.2.6 天气情况对出行情况的影响
考虑到不同天气的天数不同,例如非常糟糕的天气(4)会很少出现,查看一下不同天气等级的数据条数,再对租赁数量按天气等级取每小时平均值。
count_weather = Bike_data.groupby('weather')
count_weather[['casual','registered','count']].count()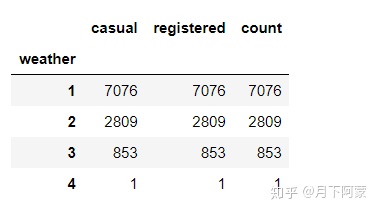
weather_df = Bike_data.groupby('weather', as_index=True).agg({'casual':'mean',
'registered':'mean'})
weather_df.plot.bar(stacked=True,title = 'Average number of rentals initiated
per hour in different weather')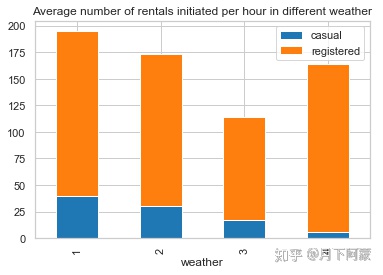
观察到天气等级4的时候出行人数并不少,尤其是会员出行人数甚至比天气等级2的平均值还高,这有点不太符合我们的一般认知,可以从另一个角度再看看。
由于在已知租赁情况的数据中,天气等级4的数据只有一条,所以我想把天气等级4的数据打印出来观察一下
Bike_data[Bike_data['weather']==4]
因为在上下班高峰期,可能是一个异常数据
3.2.7 风速对出行情况的影响
先来看下两年时间风速的变化趋势
windspeed_df = Bike_data.groupby('date', as_index=False).agg({'windspeed_rfr':'mean'})
windspeed_df['date']=pd.to_datetime(windspeed_df['date'])
#将日期设置为时间索引
windspeed_df=windspeed_df.set_index('date')
windspeed_month = Bike_data.groupby(['year','month'], as_index=False).agg({'weekday':'min',
'windspeed_rfr':'mean'})
windspeed_month.rename(columns={'weekday':'day'},inplace=True)
windspeed_month['date']=pd.to_datetime(windspeed_month[['year','month','day']])
fig = plt.figure(figsize=(18,6))
ax = fig.add_subplot(1,1,1)
plt.plot(windspeed_df.index , windspeed_df['windspeed_rfr'] , linewidth=1.3,label='Daily average')
plt.plot(windspeed_month['date'], windspeed_month['windspeed_rfr'] ,
marker='o', linewidth=1.3,label='Monthly average')
ax.legend()
ax.set_title('Change trend of average number of windspeed per day in two years')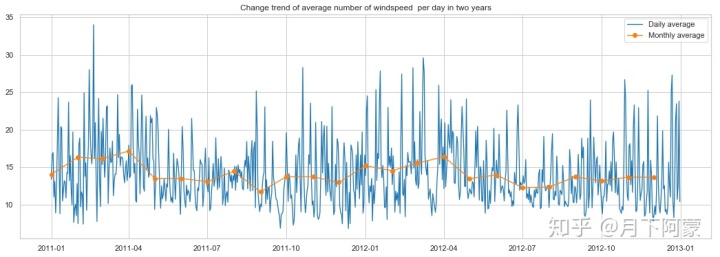
可以看出风速在2011年9月份和2011年12月到2012年3月份间波动和大,观察一下租赁人数随风速变化趋势,考虑到风速特别大的时候很少,如果取平均值会出现异常,所以按风速对租赁数量取最大值。
windspeed_rentals = Bike_data.groupby(['windspeed'], as_index=True).agg({'casual':'max',
'registered':'max',
'count':'max'})
windspeed_rentals .plot(title = 'Max number of rentals initiated per hour in different win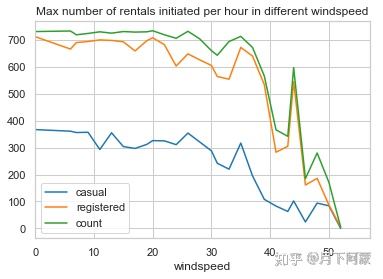
可以看到租赁数量随风速越大租赁数量越少,在风速超过30的时候明显减少,但风速在风速40左右却有一次反弹,应该是和天气情况一样存在异常的数据,打印异常数据观察一下
df2=Bike_data[Bike_data['windspeed']>40]
df2=df2[df2['count']>400]
df2
也是一个下班高峰的异常值
3.2.8 日期对出行的影响
考虑到相同日期是否工作日,星期几,以及所属年份等信息是一样的,把租赁数据按天求和,其它日期类数据取平均值
day_df = Bike_data.groupby(['date'], as_index=False).agg({'casual':'sum','registered':'sum',
'count':'sum', 'workingday':'mean',
'weekday':'mean','holiday':'mean',
'year':'mean'})
day_df.head()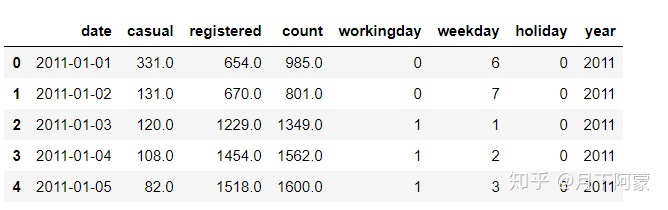
number_pei=day_df[['casual','registered']].mean()
number_pei输出
casual 829.447368
registered 3480.372807
dtype: float64plt.axes(aspect='equal')
plt.pie(number_pei, labels=['casual','registered'], autopct='%1.1f%%',
pctdistance=0.6 , labeldistance=1.05 , radius=1 )
plt.title('Casual or registered in the total lease')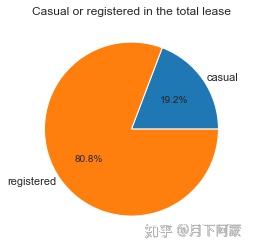
1)工作日:
由于工作日和休息日的天数差别,对工作日和非工作日租赁数量取了平均值,对一周中每天的租赁数量求和
workingday_df=day_df.groupby(['workingday'], as_index=True).agg({'casual':'mean',
'registered':'mean'})
workingday_df_0 = workingday_df.loc[0]
workingday_df_1 = workingday_df.loc[1]
# plt.axes(aspect='equal')
fig = plt.figure(figsize=(8,6))
plt.subplots_adjust(hspace=0.5, wspace=0.2) #设置子图表间隔
grid = plt.GridSpec(2, 2, wspace=0.5, hspace=0.5) #设置子图表坐标轴 对齐
plt.subplot2grid((2,2),(1,0), rowspan=2)
width = 0.3 # 设置条宽
p1 = plt.bar(workingday_df.index,workingday_df['casual'], width)
p2 = plt.bar(workingday_df.index,workingday_df['registered'],
width,bottom=workingday_df['casual'])
plt.title('Average number of rentals initiated per day')
plt.xticks([0,1], ('nonworking day', 'working day'),rotation=20)
plt.legend((p1[0], p2[0]), ('casual', 'registered'))
plt.subplot2grid((2,2),(0,0))
plt.pie(workingday_df_0, labels=['casual','registered'], autopct='%1.1f%%',
pctdistance=0.6 , labeldistance=1.35 , radius=1.3)
plt.axis('equal')
plt.title('nonworking day')
plt.subplot2grid((2,2),(0,1))
plt.pie(workingday_df_1, labels=['casual','registered'], autopct='%1.1f%%',
pctdistance=0.6 , labeldistance=1.35 , radius=1.3)
plt.title('working day')
plt.axis('equal')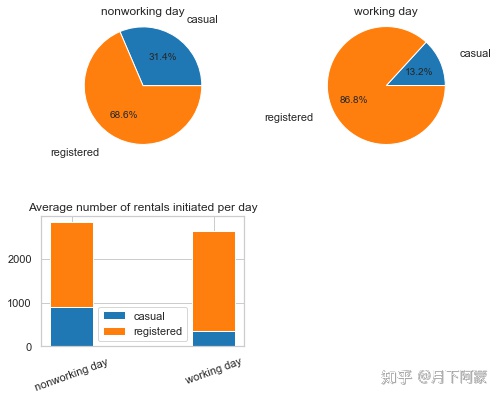
weekday_df= day_df.groupby(['weekday'], as_index=True).agg({'casual':'mean', 'registered':'mean'})
weekday_df.plot.bar(stacked=True , title = 'Average number of rentals initiated
per day by weekday')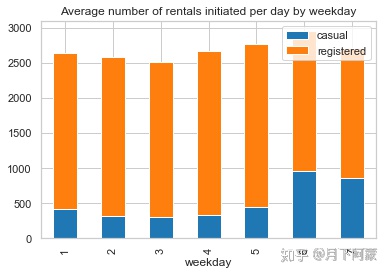
通过上面两个图可以看出:
1.工作日会员用户出行数量较多,临时用户出行数量较少;
2.周末会员用户租赁数量降低,临时用户租赁数量增加。
2)节假日
由于节假日在一年中数量占比非常少,先来看一每年的节假日下有几天,
holiday_coun=day_df.groupby('year', as_index=True).agg({'holiday':'sum'})
holiday_coun
假期的天数占一年天数的份额十分少,所以对假期和非假期取日平均值
holiday_df = day_df.groupby('holiday', as_index=True).agg({'casual':'mean', 'registered':'mean'})
holiday_df.plot.bar(stacked=True , title = 'Average number of rentals initiated
per day by holiday or not')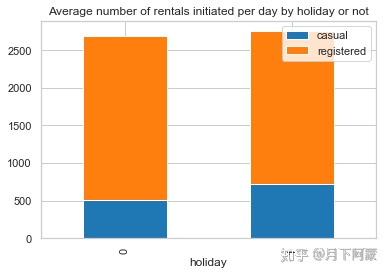
4. 选择特征值
根据前面的观察,决定将时段(hour)、温度(temp)、湿度(humidity)、年份(year)、月份(month)、季节(season)、天气等级(weather)、风速(windspeed_rfr)、星期几(weekday)、是否工作日(workingday)、是否假日(holiday),11项作为特征值
由于CART决策树使用二分类,所以将多类别型数据使用one-hot转化成多个二分型类别
dummies_month = pd.get_dummies(Bike_data['month'], prefix= 'month')
dummies_season=pd.get_dummies(Bike_data['season'],prefix='season')
dummies_weather=pd.get_dummies(Bike_data['weather'],prefix='weather')
dummies_year=pd.get_dummies(Bike_data['year'],prefix='year')
#把5个新的DF和原来的表连接起来
Bike_data=pd.concat([Bike_data,dummies_month,dummies_season,dummies_weather,dummies_year],axis=1)分离训练集和测试集
dataTrain = Bike_data[pd.notnull(Bike_data['count'])]
dataTest= Bike_data[~pd.notnull(Bike_data['count'])].sort_values(by=['datetime'])
datetimecol = dataTest['datetime']
yLabels=dataTrain['count']
yLabels_log=np.log(yLabels)把不要的列丢弃
dropFeatures = ['casual' , 'count' , 'datetime' , 'date' , 'registered' ,
'windspeed' , 'atemp' , 'month','season','weather', 'year' ]
dataTrain = dataTrain.drop(dropFeatures , axis=1)
dataTest = dataTest.drop(dropFeatures , axis=1)5. 选择模型、训练模型
rfModel = RandomForestRegressor(n_estimators=1000 , random_state = 42)
rfModel.fit(dataTrain , yLabels_log)
preds = rfModel.predict( X = dataTrain)6. 预测测试集数据
predsTest= rfModel.predict(X = dataTest)
submission=pd.DataFrame({'datetime':datetimecol , 'count':[max(0,x) for x in np.exp(predsTest)]})
submission.to_csv('bike_predictions.csv',index=False)预测完成。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









