



 本文介绍了Go语言的BigCache缓存库,重点探讨了其加速并发访问的分片策略和避免高额GC开销的设计,如fnv64a哈希算法与ByteQueue字节队列。此外,还解析了BigCache的实现原理,包括shards数组、cacheShard对象及其内部结构,以及柔性删除机制。总结了BigCache的优点和缺点,适合对Go缓存库有研究需求的读者。
本文介绍了Go语言的BigCache缓存库,重点探讨了其加速并发访问的分片策略和避免高额GC开销的设计,如fnv64a哈希算法与ByteQueue字节队列。此外,还解析了BigCache的实现原理,包括shards数组、cacheShard对象及其内部结构,以及柔性删除机制。总结了BigCache的优点和缺点,适合对Go缓存库有研究需求的读者。
目录
- golang缓存库之BigCache
- golang缓存库之FastCache
- golang缓存库之FreeCache
- golang缓存库之GroupCache
- golang缓存库之Ristretto
- 缓存库的对比分析与适用场景
该系列文章本篇文章介绍golang缓存库,以及统一的对比分析;今天介绍的是第一个--bigCache
import (
"fmt"
"github.com/allegro/bigcache"
"time"
)
func main() {
cache, _ := bigcache.NewBigCache(bigcache.DefaultConfig(10 * time.Minute))
cache.Set("my-unique-key", []byte("value"))
entry, _ := cache.Get("my-unique-key")
fmt.Println(string(entry))
}
BigCache特性
bigCache有两个特性
- 加速并发访问
- 避免高额的GC开销
加速并发访问
1. 数据分片
数据分片太常见了,很多大并发场景下为了减小并发的压力都会采用这种方法,比如innoDB的内存管理(segment-extend-page-slot),kafka broker消息存储格式(topic-partition-segment-index+log),包括golang内置map结构(buckets-链表)以及并发map库concurrent-map(shard-map),freeCache其实也是(segment-slot-entry)。
bigCache为了解决并发的问题,采用 shard (分片数组), 每个分片一把锁。对于每一个缓存对象,根据它的key计算它的哈希值: hash(key) % N, N是分片数量。降低并发N个 goroutine 每次请求落在同一个分片的概率,减少数据竞争,同时锁粒度被大幅度减小,因为锁范围从全局缓存缩小到了单个shard中。
- 按位取模
x mod N = (x & (N − 1))
bigCache计算hash采用按位取模,按位与比取余效率更高,需要的指令更少。
但是用这种方式有个前提,数组大小必须是2的幂方,不然会导致有的下标永远不会被计算得到。比如假设数组大小为15(二进制为 1111),减1后为14(二进制为 1110),那么任何数字和 1110 按位与,都无法得到0~1110中第1位为1的数字,比如0001,0011等等。
func (c *BigCache) getShard(hashedKey uint64) (shard *cacheShard) {
return c.shards[hashedKey&c.shardMask]
}
//hashedkey&c.shardMask
0111
AND 1101 (mask)
= 0101
避免高额的GC开销
1. fnv64a hash算法
bigcache提供了一个默认的Hash的实现,采用fnv64a算法。这个算法的好处是采用位运算的方式在栈上进行运算,避免在堆上分配。
const (
// offset64 FNVa offset basis. See https://en.wikipedia.org/wiki/Fowler–Noll–Vo_hash_function#FNV-1a_hash
offset64 = 14695981039346656037
// prime64 FNVa prime value. See https://en.wikipedia.org/wiki/Fowler–Noll–Vo_hash_function#FNV-1a_hash
prime64 = 1099511628211
)
// Sum64 gets the string and returns its uint64 hash value.
func (f fnv64a) Sum64(key string) uint64 {
var hash uint64 = offset64
for i := 0; i len(key); i++ {
hash ^= uint64(key[i])
hash *= prime64
}
return hash
}
2. ByteQueue字节队列
针对GoGC的特性所做的针对性优化
var map[string]interface{}
Go中实现缓存最简单最常见的方式是使用一个map来存储元素,比如concurrent-map,但是如果使用map,GC(垃圾回收器)会在标记阶段访问map中的每一个元素,当map非常大时这会对程序性能带来非常大的开销。不过如果你使用的map的key和value中都不包含指针,那么GC会忽略这个map。
bigCache针对Golang GC的特性所做的针对性优化,具体做法是每个Shard维护一个全局ByteQueue字节队列和一个map
func initNewShard(config Config, callback onRemoveCallback, clock clock) *cacheShard {
return &cacheShard{
hashmap: make(map[uint64]uint32, config.initialShardSize()),
entries: *queue.NewBytesQueue(config.initialShardSize()*config.MaxEntrySize, config.maximumShardSize(), config.Verbose),
//...其他成员
}
}
将value存储统一成[]byte二进制格式,调用set的时候将序列化后的[]byte追加到ByteQueue中,同时map中存储该序列化后数据在全局[]byte中的头部下标。
使用全局的[]byte的好处就是只会给GC增加了一个额外对象,由于字节切片除了自身对象并不包含其他指针数据,所以GC对于整个对象的标记时间是O(1)。
BigCache实现原理
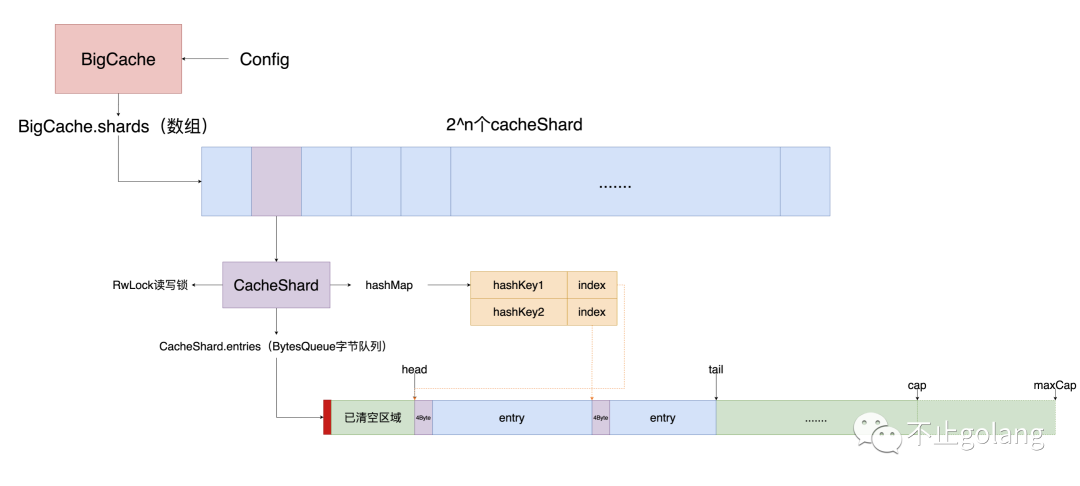
BigCache的内存结构层级相对简单,只有两层,分别是BigCache里的数据分片数组shards(大小为2^n次方),shards中每个item为一个CacheShard对象(实际加锁并发访问数据的对象),每个对象维护一个读写锁,hashMap,ByteQueue字节队列
shards数组
对shards数组的访问是不需要加锁的,因为该数组在初始化时创建,后续大小就不会变了,即后续对数组的访问只有读
func newBigCache(config Config, clock clock) (*BigCache, error) {
if config.Hasher == nil {
config.Hasher = newDefaultHasher() //默认fnv64a
}
cache := &BigCache{
shards: make([]*cacheShard, config.Shards), //分片数组
lifeWindow: uint64(config.LifeWindow.Seconds()), //过期软删除
clock: clock, //默认系统时钟,用户对齐计算currentTimestamp,与lifeWindow一起,判断是否过期删除
hash: config.Hasher,//默认fnv64a
shardMask: uint64(config.Shards - 1),//用于位运算计算hash到哪个shard
close: make(chan struct{}), //调用方调用cache.close()方法时作清理操作,比如指定cleanWindow时会开启后台cleanUp线程
//...
}
//...
return cache, nil
}
cacheShard对象
是真正会出现并发操作的对象,所以需要一个读写锁
func initNewShard(config Config, callback onRemoveCallback, clock clock) *cacheShard {
return &cacheShard{
entries: *queue.NewBytesQueue(config.initialShardSize()*config.MaxEntrySize, config.maximumShardSize(), config.Verbose),
hashmap: make(map[uint64]uint32, config.initialShardSize()),
lock: sync.RWMutex,
entryBuffer: make([]byte, config.MaxEntrySize+headersSizeInBytes),
//...
}
}
1. 每个CacheShard维护一个读写锁,hashMap, entries字节队列
- entries: 字节队列,提供peek,get, pop,push操作
- hashmap: 维护64位hashKey对应在entries(字节队列)的头部索引
- lock: 读写锁,控制并发访问
- entryBuffer: 全局临时变量,set的时候需创建key,value等信息的entry的[]byte临时空间,用户填充数据,这样可以防止每次set的时候都为每个value执行make([]byte,size)的操作
2. 柔性删除
bigCache主动删除与过期删除只会删除该hashmap对应hashKey的索引映射,并不会清除字节队列里已填充的字节数据,顶多是把存在ByteQueue里对应位置的buffer中的hashKey置为0(后面会讲解)
byteQueue队列
避免高频GC最大工程
func NewBytesQueue(initialCapacity int, maxCapacity int, verbose bool) *BytesQueue {
return &BytesQueue{
array: make([]byte, initialCapacity),
capacity: initialCapacity,
maxCapacity: maxCapacity,
headerBuffer: make([]byte, headerEntrySize),
tail: leftMarginIndex,
head: leftMarginIndex,
rightMargin: leftMarginIndex,
initialCapacity: initialCapacity,
//...
}
}
1. 成员变量说明,整体思想有点像RingBuffer
- array: 负责数据存储的buffer,以entry的内存组织结构管理每个set操作的数据,
headerSize + entry (timestamp(8byte=64位) + hashKey(8byte=64位) + keySize(2byte=16位) + key buffer + value bufer) - 空间大小: capacity:(预分配的初始空间大小),maxCapacity(最大空间大小)
- 索引标记: 通过维护索引实现byteQueue的peek,pop,push,reset操作
- leftMargin: 固定变量=1,也就是1byte位置,byteQueue不是从array索引0开始的,而是从1开始的(之所以这么定义是
peek(index)获取某个索引起点开始的entry的时候,如果index=0会认为是无数据,所以区分开) - tail: 尾索引,byteQueue进行push操作的时候只会在tail之后作append操作,tail到capacity之间的空间成为
availableSpaceAfterTail可用空间 - head:头索引,head之前是可用空间,之后是有数据的空间,当tailavailableSpaceBeforeHead可用空间
- rightMargin: 一般=tail,其作用是当空间不够需要扩容时,需将原来oldArray[:rightMargin]的空间数据拷贝到新字节数组中
- leftMargin: 固定变量=1,也就是1byte位置,byteQueue不是从array索引0开始的,而是从1开始的(之所以这么定义是
- headerBuffer:跟CacheShard的entryBuffer一样都是临时变量,只是它是4byte的headersize的临时变量
2. ByteQueue图解操作流程

头部红色1byte区域是不会被使用的,从1开始;初始化时,head,tail,rightMargin=leftMargin

当我们set两次不同的key,value的时候,cacheShard会在byteQueue中执行两次push操作,同时将每次操作的字节头索引映射存储在hashMap中,从上图我们可以看到
- 一次set操作在字节队列的内存空间中会存储header+entry,其中header=4byte负责记录entry的大小blobSize,方便我们从header开始读取4字节后blobSize大小的缓冲区数据
- entry包括2部分(元数据+真正数据)
- 元数据为
18byte=8byte(timestamp时间戳)+8byte(hashKey散列后的key,也就是cacheShard中hashMap的键)+2byte(keySize键大小) - 真正数据则是key与value的[]byte序列化后的数据
- 元数据为
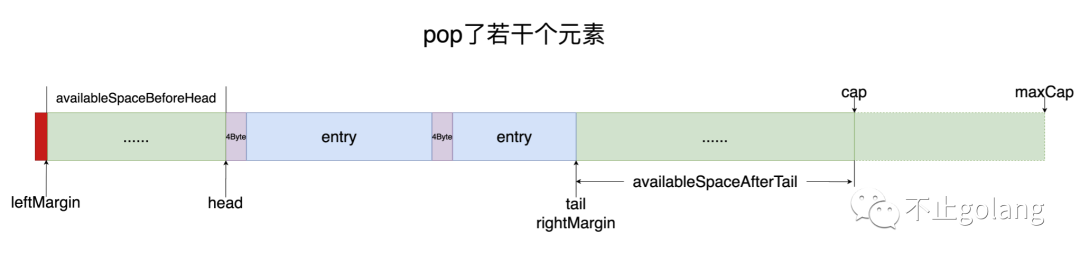
bigCache有主动删除与过期删除机制,主动删除是柔性删除(只删除hashMap索引映射),上图展示的过期删除,当空间不足时,bigCache会采用LRU的形式删除头部位置的数据,将head后移,此时availableSpaceBeforeHead,availableSpaceAfterTail都是可利用的空间
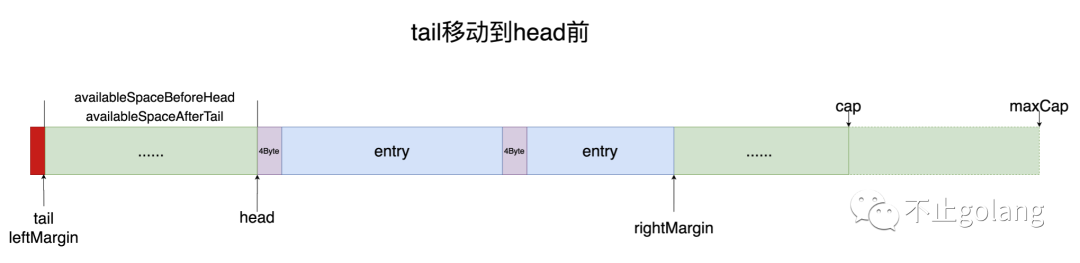
上图展示的是当tail不断往后移动最后空间不够的时候,tail会移动到head前面,此时tail到head之间的空间一样可用,就是一个RingBuffer
3. set操作
func (s *cacheShard) set(key string, hashedKey uint64, entry []byte) error {
currentTimestamp := uint64(s.clock.epoch()) //系统时钟
s.lock.Lock()
// 查找是否已经存在了对应的缓存对象,如果存在,将它的值置为空
if previousIndex := s.hashmap[hashedKey]; previousIndex != 0 {
if previousEntry, err := s.entries.Get(int(previousIndex)); err == nil {
resetKeyFromEntry(previousEntry) //将元数据中的hashKey置为0
}
}
// 触发是否要移除最老的缓存对象
if oldestEntry, err := s.entries.Peek(); err == nil {
s.onEvict(oldestEntry, currentTimestamp, s.removeOldestEntry) //判断是否过期,过期则删除hashMap索引映射
}
// 将对象放入到一个字节数组中,如果已有的临时变量entryBuffer空间可以放得下此对象,则重用,否则新建一个更大的字节数组
w := wrapEntry(currentTimestamp, hashedKey, key, entry, &s.entryBuffer)
for {
// 无锁操作,尝试放入到字节队列中,成功则加入到map中
if index, err := s.entries.Push(w); err == nil {
s.hashmap[hashedKey] = uint32(index)
s.lock.Unlock()
return nil
}
// 如果空间不足,移除最老的元素,删除hashMap索引
if s.removeOldestEntry(NoSpace) != nil {
s.lock.Unlock()
return fmt.Errorf("entry is bigger than max shard size")
}
}
}
func wrapEntry(timestamp uint64, hash uint64, key string, entry []byte, buffer *[]byte) []byte {
keyLength := len(key)
blobLength := len(entry) + headersSizeInBytes + keyLength //headersSizeInBytes=18byte
if blobLength > len(*buffer) {
*buffer = make([]byte, blobLength) //不够,创建更大的数组,指向的还是entryBuffer临时变量
}
blob := *buffer
//小端序
binary.LittleEndian.PutUint64(blob, timestamp) //64位=8byte的时间戳
binary.LittleEndian.PutUint64(blob[timestampSizeInBytes:], hash) //64位=8byte的hashKey
binary.LittleEndian.PutUint16(blob[timestampSizeInBytes+hashSizeInBytes:], uint16(keyLength)) //16位=2byte的key大小
copy(blob[headersSizeInBytes:], key) //key buffer
copy(blob[headersSizeInBytes+keyLength:], entry) // value buffer
return blob[:blobLength]
}
总个结
优点
- 高并发访问:分片,临时变量,无锁push
- GC避免:无堆分配的fnv64a hash算法,ByteQueue字节队列
缺陷
- 柔性删除机制会导致byteQueue出现很多内存空洞,而bigCache并没有有效重用起来,当我们对同个key频繁更新的时候,此时造成的空洞只有等待清理最老的元素的时候清理到空洞位置才能把这些空洞"删除掉"
- 不能作复杂删除操作,所有的缓存对象的lifewindow都是一样的,比如30分钟、两小时,依赖过期删除,无法set的时候指定expireTime过期时间。
所以,如果你真的使用bigcache, 需要注意它的这些特性,根据场景进行选择,后面会介绍其他缓存库,统一比较分析

















 2159
2159

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









