






 本文介绍了如何优化C++代码的时间复杂度和系统复杂度,包括代码级和系统级的复杂度管理。在代码级优化中,通过提炼函数、优化条件表达、替换算法、以多态取代条件式、参数化方法等方式降低复杂度。在系统级优化中,关注模块级和组件间复杂度,强调模块化设计和减少依赖关系。
本文介绍了如何优化C++代码的时间复杂度和系统复杂度,包括代码级和系统级的复杂度管理。在代码级优化中,通过提炼函数、优化条件表达、替换算法、以多态取代条件式、参数化方法等方式降低复杂度。在系统级优化中,关注模块级和组件间复杂度,强调模块化设计和减少依赖关系。
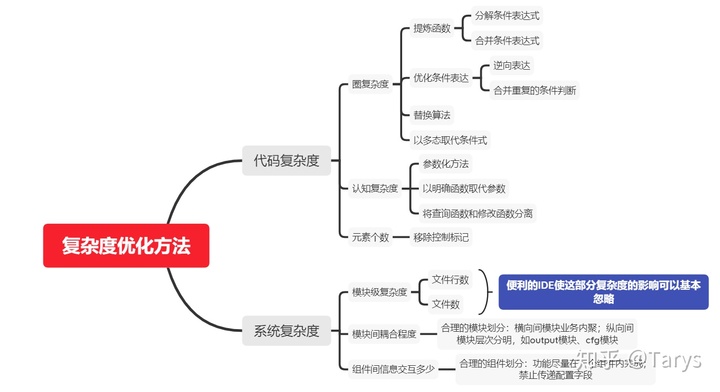
复杂度应该分成两个大类,一类是代码复杂度,关注的是函数内的情况,另一类是系统复杂度,关注系统规模的情况。
常见的衡量函数复杂度的指标主要是圈复杂度,偶尔也会包括函数嵌套深度,由于圈复杂度的优化方法基本能覆盖函数深度,这里函数深度就不单独列出了。
认知复杂度,是sonarqube工具里的一个概念,这个复杂度指标弥补了圈复杂度的一些不足,比如switch case,圈复杂度认为一个case则圈复杂度+1,这种复杂度的度量方式是违反人类的认知的。圈复杂度容易理解,一个条件+1,认知复杂度你可以简单的理解为从人类认知角度去衡量函数复杂程度的一种方法,详情可以看这个链接:
[工程质量] Cognitive Complexity 认知复杂度www.jianshu.com
元素个数,是简单设计四原则里面的最后一个原则所讲的,元素要尽可能少。
一、代码级复杂度
1.提炼函数
优化复杂度最重要的就是提炼函数了。解释一下,通过提炼函数,你用一个有表达力的名字替换了一堆条件和计算,当然能够降低复杂度了。我们来看个例子:
if(a > b)
max = a;
else
max = b;可以替换成
max = GET_MAX(a, b)这个方法叫做合并条件表达式。把一些if else合并了起来。
还有一种方法叫分解条件表达式,把if else后面执行的内容封装了起来。还是用上面的例子,可以替换成:
if(a > b)
DoSthA();
else
DoSthB();同样通过封装函数,降低了复杂度。
2.优化条件表达
有些条件正着写要写很多条件,反着写会很简单,这种改法叫逆向表达,我们看个例子:
if(a == 1 || a == 2 || a == 3)
DoSthA();
else
DoSthB();用逆向表达可以改成:
if(a != 4)//假如a只有1 2 3 4这四种取值
DoSthA();
else
DoSthB();有人可能会问,高性能编码规范里要求执行概率更高的代码片段放在前面,当性能与上述复杂度优化方法冲突时怎么选?这取决于这段代码执行的频繁程度,如果每秒执行10万次,要按高性能的要求写,如果每秒执行1千次,则可以选复杂度优化方法。相关文章可以看看这篇:
Tarys:高性能编码规范驳斥(四)zhuanlan.zhihu.com
3.替换算法
算法一般没太大可替换的空间,认知复杂度低的一般性能就会差。
常见的可以简单替换的一般是表驱动,表驱动是什么可以看之前的文章:
Tarys:C常用设计模式——状态模式zhuanlan.zhihu.com一般来说,如果想通过替换算法在复杂度方面有所优化,只能简化需求,在细节方面与需求方细抠,很多时候是能谈下来的,需求方不了解他们认为的简单需求会给开发带来多大的代价,当代价大到性能、质量很难承受的时候,有很大概率会妥协。
4.以多态取代条件式
这部分在C常用设计模式系列文章里讲的比较多了:
Tarys:C常用设计模式——策略模式zhuanlan.zhihu.com5.参数化方法、明确函数取代参数、将查询函数与修改函数分离
含义如题,以有意义的参数表达无意义的数字。文字总是比数字更有表达力。查询函数和修改函数混杂在一起让人更加困惑,可以提取出Get和Set函数。
6.移除控制标记
控制标记指的是会用于if条件的一些flag。比如一些循环里,想跳过某些情况,就可能会用flag,消除flag一般用continue或者break。不过这个仁者见仁智者见智,有些时候continue不一定比if(flag)更容易理解。实际上在认知复杂度里,continue和break都被认为会增加认知复杂度。
二、系统级复杂度
1.模块级复杂度
主要指文件行数和文件数。正如开头思维导图里所说,便利的IDE使这部分复杂度的影响可以基本忽略。
2.模块间复杂度
模块间的依赖关系越复杂,模块越难以理解。降低模块间复杂度的方法主要是模块化,包括横向分层,纵向模块业务内聚。分层,模块的属性是不同的,有的是用来串起整个流程的,有的是用来支撑其他模块的,有的是配置,有的是输出,层次分明的模块能简化模块之间的连接关系;业务内聚,相同业务的代码如果分布在两个模块里,必然会导致两个模块绑定在一起。
3.组件间复杂度
组件间复杂度,指的是接口的复杂程度、消息的个数。优化方法一般有:功能尽量在一个组件内完成,公共配置信息组件自己获取禁止传递等等。参见:
Tarys:接口消息导致的组件耦合问题zhuanlan.zhihu.com

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









