







简介:操作系统是管理计算机硬件资源和提供服务的基础学科。本系列实验包括进程调度、作业调度、内存空间分配和文件系统管理,旨在帮助学生通过实践深入理解操作系统的四大核心概念。每个实验都聚焦于操作系统的不同方面,如调度算法对系统性能的影响、内存管理方式及算法的应用,以及文件系统的组织和管理。实验报告详细分析和解释了每个实验的结果,从而巩固了理论知识并提升了实际操作能力。对于IT专业人员,如系统管理员和软件开发者,这些实践性知识是非常宝贵的。 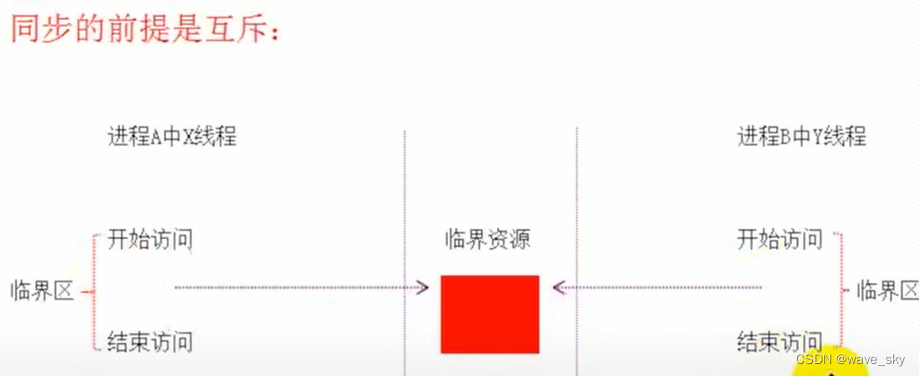
1. 操作系统基础与服务
在探讨操作系统的深层功能之前,首先要对其基础概念进行梳理,理解操作系统如何为应用提供服务是入门的第一步。本章将探讨操作系统的核心功能、提供的服务类型、以及如何管理计算机硬件资源。
1.1 操作系统的作用与结构
操作系统是计算机系统中的核心软件,它负责管理硬件资源,控制程序运行,并提供用户与计算机交互的界面。操作系统主要由内核、设备驱动程序、系统服务和用户界面四部分组成。内核是操作系统的心脏,负责管理CPU、内存和设备驱动程序。设备驱动程序为特定的硬件设备提供接口。系统服务包括文件系统管理、网络通信和安全机制等。用户界面则提供了用户与操作系统交互的方式。
1.2 操作系统提供的服务
操作系统提供了多种服务来简化用户和程序对计算机硬件的访问:
- 进程管理:操作系统负责创建、调度、同步和终止进程。
- 内存管理:负责内存的分配、回收以及访问控制。
- 文件系统管理:管理存储设备上的数据组织和访问。
- 设备管理:提供对硬件设备的抽象访问和资源分配。
在接下来的章节中,我们将深入探讨进程管理和服务,揭开操作系统服务的神秘面纱,并通过实验与实践加深理解。
2. 进程调度实验与算法
2.1 进程调度概述
2.1.1 进程与进程调度的概念
在现代操作系统中,进程是资源分配和独立运行的基本单位。一个进程是一段正在执行的程序,包括程序代码、其占用的资源以及执行状态。进程调度,又称为CPU调度,是操作系统中决定哪个进程获得CPU时间片从而执行任务的过程。其核心目的是提高系统资源的利用率,确保系统响应的及时性,以及满足特定的性能标准,如最大吞吐量和最小响应时间。
进程调度算法通常需要考虑的关键因素包括: - 公平性:确保所有进程都有机会获得CPU时间。 - 效率:最大化CPU利用率。 - 响应时间:最小化进程从提交到完成的时间。 - 周转时间:最小化从进程开始到进程结束的总时间。
2.1.2 进程调度的目标与策略
进程调度的目标因操作系统的目标而异,但在大多数情况下,我们希望调度器能够: - 确保所有进程公平地获得CPU时间。 - 提高吞吐量,即单位时间内完成进程的数量。 - 减少等待时间和响应时间,改善用户体验。 - 提高资源利用率,特别是CPU利用率。
为了实现这些目标,存在多种进程调度策略。这些策略可以大致分为三类: - 先来先服务(FCFS):按照请求的顺序执行。 - 短作业优先(SJF):执行预计运行时间最短的作业。 - 优先级调度:选择优先级最高的作业执行。 - 轮转调度(Round-Robin):采用时间片的方式轮流为每个进程分配CPU。
2.2 典型调度算法剖析
2.2.1 先来先服务(FCFS)
先来先服务(FCFS)是一种最简单的进程调度算法。在这个算法中,按照进程到达的顺序进行调度。FCFS算法的优点是易于理解和实现,但缺点是可能导致较短的进程被长时间等待(饥饿现象),并且平均等待时间和平均周转时间可能较长。
一个典型的FCFS调度示例是:
- 进程A到达,开始执行。
- 进程B到达,等待进程A执行完毕。
- 进程A执行完毕,进程B开始执行。
- 进程C到达,等待进程B执行完毕。
- 进程B执行完毕,进程C开始执行。
2.2.2 短作业优先(SJF)
短作业优先(SJF)调度算法选择执行时间最短的进程进行调度。这种策略可以最小化平均等待时间,但可能导致长作业饥饿。SJF分为两种:非抢占式和抢占式。非抢占式SJF在当前进程执行完毕后才考虑其他进程;而抢占式SJF则会在新到达的进程的预计执行时间比当前执行的进程短时,立即更换当前进程。
SJF示例:
- 进程A(运行时间5)到达。
- 进程B(运行时间3)到达,抢占A,开始执行。
- 进程C(运行时间8)到达。
- 进程D(运行时间2)到达。
- 进程B执行完毕(3),进程D开始执行,因为它是最短的。
- 进程D执行完毕(2),进程A开始执行。
- 进程A执行完毕(5),进程C开始执行。
2.2.3 优先级调度
优先级调度是一种更通用的调度策略,每个进程都有一个优先级,调度器根据优先级选择下一个执行的进程。优先级可以是静态的,也可以是动态的(根据等待时间或其他因素调整)。高优先级的进程优先执行,如果多个进程优先级相同,则使用FCFS或其他调度方法。
优先级调度的潜在问题包括优先级反转(低优先级进程持有高优先级进程所需的资源)和饥饿现象。
2.2.4 轮转调度(Round-Robin)
轮转调度(Round-Robin)调度算法适用于时间片概念,它将CPU时间分成固定长度的片断,称为时间片或时钟量子。每个进程被分配一个时间片,在这个时间片内运行。如果进程在时间片结束时还未完成,则它会被放回就绪队列的末尾,等待下一次调度。
轮转调度算法的性能取决于时间片的长度。时间片太短会导致过多的上下文切换,增加开销;时间片太长则会降低系统的响应性。
2.3 调度算法的实践应用
2.3.1 调度算法的模拟实现
为了更好地理解不同调度算法的工作原理,我们可以通过模拟实现这些算法。在模拟中,我们可以使用一个进程队列,为每个进程分配属性如到达时间、服务时间、优先级等,并通过特定的调度策略来选择下一个执行的进程。代码可以使用任何支持复杂数据结构的编程语言实现,例如C++或Python。
以Python为例,一个简单的FCFS调度器的伪代码如下:
class Process:
def __init__(self, name, arrival_time, burst_time):
self.name = name
self.arrival_time = arrival_time
self.burst_time = burst_time
self.wait_time = 0
self.turnaround_time = 0
def FCFS(process_list):
# 按到达时间排序进程
process_list.sort(key=lambda x: x.arrival_time)
time = 0
complete_process = []
for process in process_list:
if time < process.arrival_time:
time = process.arrival_time
time += process.burst_time
process.turnaround_time = time - process.arrival_time
process.wait_time = process.turnaround_time - process.burst_time
complete_process.append(process)
return complete_process
2.3.2 算法性能的对比分析
实现后,我们可以创建一系列进程和不同类型的调度器,以比较不同调度算法的性能。性能指标可能包括: - 平均等待时间 - 平均周转时间 - CPU利用率 - 各种算法下进程的响应时间
这些指标可以通过模拟运行不同算法时记录的数据来计算。表格可以用于展示不同算法下的性能数据对比。
| 指标 | FCFS | SJF | 优先级调度 | 轮转调度 |
|------------|------|-------|------------|----------|
| 平均等待时间 | ... | ... | ... | ... |
| 平均周转时间 | ... | ... | ... | ... |
| CPU利用率 | ... | ... | ... | ... |
| 平均响应时间 | ... | ... | ... | ... |
通过对比,我们可以得出不同算法在不同情况下的适用性,以及它们各自的优缺点。这将有助于我们选择最合适的算法以适应特定的工作负载和性能要求。
3. 作业调度实验与策略
3.1 作业调度基础
3.1.1 长作业优先(LJF)策略
长作业优先(Longest Job First,LJF)策略是作业调度中较为简单的一种调度方式,该策略优先考虑运行时间最长的作业。其核心思想是充分利用系统资源,减少作业的平均等待时间。但长作业优先策略容易导致短作业长时间等待,可能导致系统吞吐量降低,且对于短作业不公平。
graph TD;
A[开始调度] -->|检查作业队列| B{队列中作业}
B -->|作业运行时间最长| C[选择最长作业]
B -->|其他作业先到| D[选择先到的作业]
C --> E[作业完成]
D --> E
3.1.2 短作业优先(SJF)策略
短作业优先(Shortest Job First,SJF)是一种追求平均等待时间最小化的策略。它选择队列中运行时间最短的作业来执行,从而保证了系统的响应时间最短,提高了作业的周转时间。这种策略适合于批处理系统,但在实际应用中可能存在饥饿问题,即短作业过多时,长作业可能长时间得不到执行。
graph TD;
A[开始调度] -->|检查作业队列| B{队列中作业}
B -->|作业运行时间最短| C[选择最短作业]
B -->|其他作业先到| D[选择先到的作业]
C --> E[作业完成]
D --> E
3.2 混合调度策略的探索
3.2.1 混合策略的设计与实现
为了兼顾长作业和短作业的利益,混合策略的设计显得尤为重要。混合策略通过结合LJF和SJF的优点,平衡系统对不同类型作业的响应。具体实现可以通过为作业设置优先级,动态调整作业队列顺序,或者通过预测作业执行时间来进行调度决策。混合调度策略在不同类型的系统和不同场景下有着广泛的应用。
graph TD;
A[开始调度] -->|收集作业信息| B{作业优先级}
B -->|根据策略设置优先级| C[计算作业权重]
C --> D{队列重新排序}
D -->|选择优先级最高作业| E[执行作业]
E --> F[作业完成]
F -->|有新作业| A
F -->|无新作业| G[保持空闲直到新作业到达]
3.2.2 混合策略的效果评估
混合策略的效果评估主要依赖于多个评价指标,如平均等待时间、平均响应时间、系统吞吐量等。通过模拟实验,可以比较不同调度策略在相同工作负载下的性能表现,从而评估混合策略的有效性。在实际应用中,还要考虑到操作系统调度器的设计复杂度和系统资源的开销。
| 指标 | SJF | LJF | 混合策略 |
|--------------|-------|-------|----------|
| 平均等待时间 | 低 | 高 | 中等 |
| 平均响应时间 | 中等 | 高 | 低 |
| 系统吞吐量 | 中等 | 中等 | 高 |
3.3 作业调度策略的选择与优化
3.3.1 策略选择的依据与考量
选择合适的作业调度策略需要考虑多个因素,包括作业类型、用户需求、系统目标等。比如,实时系统中可能更偏向于响应时间短的策略,而批处理系统可能更倾向于提高系统吞吐量。此外,系统的资源利用率、作业调度的公平性也是策略选择时需要考虑的重要方面。
graph TD;
A[选择调度策略] -->|分析作业类型| B[实时作业多?]
B -->|是| C[考虑响应时间]
B -->|否| D[考虑吞吐量]
C --> E[实时系统策略]
D --> F[批处理系统策略]
E -->|评估性能| G[响应时间评估]
F -->|评估性能| H[吞吐量评估]
G -->|对比| I[确定策略]
H -->|对比| I
3.3.2 针对特定环境的调度优化
针对特定环境进行调度优化,意味着调度策略需要进行定制化的设计。例如,在云计算环境中,资源动态伸缩的特性要求调度策略能够适应不断变化的工作负载和资源状态。在嵌入式系统中,考虑到系统资源有限,调度策略可能需要更为简洁高效。优化过程涉及算法调整、性能测试、反馈调整等多个步骤。
| 步骤 | 描述 |
|------------|--------------------------------------------------------------|
| 算法调整 | 根据工作负载特性调整调度参数,如时间片大小、优先级权重等 |
| 性能测试 | 使用基准测试或实际作业负载测试策略的性能 |
| 反馈调整 | 根据测试结果收集反馈信息,调整策略,重复测试直到达到优化目标 |
通过以上分析,我们可以看到,作业调度策略的选择与优化是一个复杂且动态调整的过程。在实际操作中,需要根据系统特性和作业特性灵活应用和调整调度策略。
4. 内存空间分配实验与管理方式
4.1 内存管理基础
4.1.1 内存分配的需求与挑战
内存管理是操作系统的核心功能之一,负责为运行的程序分配足够的内存空间,并确保这些空间得到高效利用。在现代计算机系统中,内存分配需求主要来自于执行的多个进程对内存资源的共享和竞争。为了有效管理内存资源,操作系统必须解决如下挑战:
- 内存碎片问题 :随着程序运行和退出,内存中会留下许多小的未使用空间,无法有效利用。
- 内存保护 :不同的进程需要被隔离,以免相互影响,操作系统需要确保它们不能访问对方的内存空间。
- 虚拟内存管理 :由于物理内存的限制,需要借助硬盘空间实现更大的地址空间。
为了克服这些挑战,操作系统引入了多种内存管理策略,包括分页、分段以及更高级的混合方法。
4.1.2 基本的内存管理方法
基础内存管理通常采用静态和动态分配两种方法:
- 静态内存分配 :内存空间在程序编译时就已经固定分配好,一般用于嵌入式系统或静态链接的程序。优点是简单、快速,缺点是不够灵活。
- 动态内存分配 :程序运行时根据需要申请和释放内存空间。动态分配使得内存使用更加灵活,但管理起来更为复杂,容易产生内存碎片和泄漏问题。
4.2 分页与分段机制
4.2.1 页式内存管理
页式内存管理将物理内存分割成固定大小的块,称为“页”,同样地,虚拟内存也被分割成等大小的页。当进程需要运行时,其对应的虚拟页会被映射到物理页上,实现虚拟地址到物理地址的转换。
页式内存管理的优点是能够有效减少外部碎片,提高内存的利用率。然而,每个进程必须连续的虚拟地址空间可能仍然导致内部碎片。
4.2.2 段式内存管理
与页式内存管理不同,段式内存管理将内存按逻辑上相关联的部分进行分割,每个段是一个连续的地址空间,可以包含代码、数据或堆栈等。进程可以由多个段组成,每个段对应不同的功能模块。
段式管理提供了较好的模块化,便于程序的保护和共享。但段的大小不一导致内存碎片问题和外部碎片的产生。
4.3 混合内存管理策略
4.3.1 段页式内存管理原理
混合内存管理策略中最常见的就是段页式管理,它结合了分页和分段的各自优势。在这种策略中,首先将程序划分为逻辑上相关的段,然后在每个段内实现分页机制。每个段的页大小可以不同,这有助于减少外部碎片和提高内存利用率。
4.3.2 混合策略的实现与分析
要实现段页式内存管理,操作系统需要维护两张表:段表和页表。段表记录了每个段的信息和对应页表的地址,而页表则记录了页与物理内存的映射关系。
这里提供一个简化的段页式内存管理实现的概念代码:
// 段表项结构定义
struct SegmentTableEntry {
int base; // 段内起始地址
int limit; // 段长度
struct PageTable* pageTable; // 页表指针
};
// 页表项结构定义
struct PageTableEntry {
int frameNumber; // 物理帧号
bool present; // 是否在内存中
// 其他控制位
};
// 模拟内存访问过程
void accessMemory(int segmentNumber, int offset) {
// 检查段表项有效性
struct SegmentTableEntry* segment = segmentTable[segmentNumber];
if (segment == NULL || offset > segment.limit) {
// 报错处理
return;
}
// 通过页表进行物理地址映射
struct PageTableEntry* page = segment.pageTable[offset / pageSize];
if (!page.present) {
// 页面未在内存,进行页面置换等处理
}
// 计算物理地址并访问
int physicalAddress = (page.frameNumber * pageSize) + (offset % pageSize);
// 执行内存访问操作...
}
在实际操作系统中,段页式内存管理的实现要复杂得多,包括内存分配策略、地址转换、页面置换算法等。通过代码可以看出,通过段页式管理,可以实现细粒度的内存分配和管理,这有助于提高系统的整体性能和稳定性。
接下来,我们将通过表格和流程图形式,更进一步地分析段页式内存管理的工作原理和优势。
混合内存管理的优势分析
| 特性 | 页式内存管理 | 段式内存管理 | 段页式内存管理 | |-----------------|--------------|--------------|----------------| | 内存碎片 | 较少 | 较多 | 较少 | | 管理复杂性 | 中等 | 较高 | 较高 | | 程序保护 | 支持 | 支持 | 支持 | | 程序共享 | 支持 | 支持 | 支持 | | 内存利用率 | 高 | 中等 | 高 | | 地址映射效率 | 高 | 中等 | 中等 |
通过以上表格可以看出,段页式内存管理结合了页式管理和段式管理的优点,在减少碎片、提供程序保护和共享的同时,仍然保持了高效的地址映射。
下面的mermaid流程图,展示了段页式内存管理在地址转换过程中的操作步骤:
graph TD;
A[开始访问内存] --> B{检查段表};
B -->|有效| C[访问对应页表];
B -->|无效| X[返回错误];
C -->|存在映射| D[计算物理地址];
C -->|不存在映射| Y[进行页面置换];
D --> E[访问实际物理内存];
Y --> D;
E --> F[结束访问];
段页式内存管理提供了灵活和高效的内存管理方式,虽然其复杂度较高,但通过现代操作系统的优化,这些开销得到了有效的缓解。随着计算机技术的发展,内存管理方式也在不断地演进和优化,以适应更大规模和更复杂的应用需求。
5. 文件系统实验与管理
在现代操作系统中,文件系统是管理数据持久性存储的核心组件,其设计和实现对系统的整体性能有着决定性的影响。本章节将探讨文件系统的基本概念、结构以及管理机制,并着重实验实践操作,以及对磁盘空间管理与系统优化的分析与探讨。
5.1 文件系统概念与结构
文件系统是操作系统中用于管理、存储和检索文件的部分,它定义了文件存储的方式,并提供了文件访问、共享以及保护的方法。理解文件系统的概念和结构,对于系统管理员和开发人员来说至关重要。
5.1.1 文件系统的基本组成
文件系统主要由以下部分组成:
- 文件 : 数据的集合,是存储在磁盘上的一系列记录。
- 目录 : 文件系统的组织结构,包含文件和子目录的索引。
- 元数据 : 关于文件和目录的属性信息,如大小、创建时间、权限等。
- 索引节点(inode) : 在Unix/Linux系统中,文件属性与文件数据块的索引信息分离存储,这种结构称为索引节点。
5.1.2 文件与目录的操作原理
文件操作通常包括创建、读取、写入、删除、移动和重命名等。而目录操作则主要涉及创建、删除、移动和重命名目录,以及创建和删除文件。在操作文件和目录时,操作系统使用文件描述符(在某些系统中为文件句柄)来追踪文件的状态和位置。
文件系统的关键组件和功能
| 组件 | 功能 | |------------|--------------------------------------------------------------| | 文件 | 存储数据的逻辑单元 | | 目录 | 文件系统的组织结构 | | 元数据 | 文件和目录的属性信息 | | 索引节点 | 文件属性与数据存储位置的映射 | | 文件描述符 | 用于跟踪打开的文件的状态和位置 |
5.2 文件管理机制实践
文件管理机制实验的目的是通过实际操作来加深对文件系统结构和功能的理解。
5.2.1 文件操作的实验步骤与方法
实验可以使用各种操作系统和工具进行。以下是常见的Linux环境下进行文件操作的基本步骤:
- 创建文件 :
bash touch filename.txt - 写入文件 :
bash echo "Hello, File System!" > filename.txt - 读取文件 :
bash cat filename.txt - 复制文件 :
bash cp filename.txt filename_copy.txt - 移动和重命名文件 :
bash mv filename_copy.txt new_folder/ mv new_folder/filename_copy.txt renamed_file.txt - 删除文件 :
bash rm filename.txt
5.2.2 目录结构的设计与实现
设计目录结构时,需要考虑数据的组织和安全访问控制。以下是一个简单的设计示例:
mkdir project_folder
cd project_folder
mkdir src include lib bin
chmod 755 src include lib bin
在上述步骤中,我们创建了一个项目文件夹 project_folder ,并在此文件夹内部创建了 src (源代码目录)、 include (头文件目录)、 lib (库文件目录)和 bin (可执行文件目录)。通过 chmod 命令,我们为这些目录设置了适当的权限。
5.3 磁盘空间管理与优化
磁盘空间管理是文件系统管理的重要方面。它涉及如何高效地分配、使用和回收磁盘空间,以确保系统性能。
5.3.1 磁盘空间的分配策略
磁盘空间的分配策略包括:
- 连续分配 : 简单但易导致外部碎片。
- 链接分配 : 每个文件由磁盘上的若干块组成,块之间通过指针链接。
- 索引分配 : 通过文件的索引节点管理数据块,适用于大型文件系统。
5.3.2 系统性能的分析与优化
对文件系统性能的分析通常包括以下方面:
- 磁盘使用情况 :
df命令可以显示磁盘空间的使用情况。 - 文件系统的I/O性能 : 使用
iostat、iotop等工具监控磁盘的读写性能。 - 文件系统碎片整理 : 对于非连续分配的文件系统,需要定期进行碎片整理。
df -h # 查看磁盘使用情况
iostat -xz 1 # 持续监控磁盘I/O性能
通过对以上方面的监控和分析,可以进行相应的优化操作,如调整文件系统的挂载选项、优化文件分配策略或进行磁盘碎片整理等。
简介:操作系统是管理计算机硬件资源和提供服务的基础学科。本系列实验包括进程调度、作业调度、内存空间分配和文件系统管理,旨在帮助学生通过实践深入理解操作系统的四大核心概念。每个实验都聚焦于操作系统的不同方面,如调度算法对系统性能的影响、内存管理方式及算法的应用,以及文件系统的组织和管理。实验报告详细分析和解释了每个实验的结果,从而巩固了理论知识并提升了实际操作能力。对于IT专业人员,如系统管理员和软件开发者,这些实践性知识是非常宝贵的。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









