







简介:本文档旨在提供关于构建高效、可维护且易于重用的Web API交互的深入指导。内容涵盖了GraphQL、REST、异步HTTP客户端技术、Python3编程和RPC等多种技术,同时着重讲解了requests库和aiohttp-client库的使用方法,以及如何通过API包装器提升代码的组织性和复用性。开发者通过学习这些知识点,将能够有效地开发和优化Web API服务,以应对各种编程挑战。 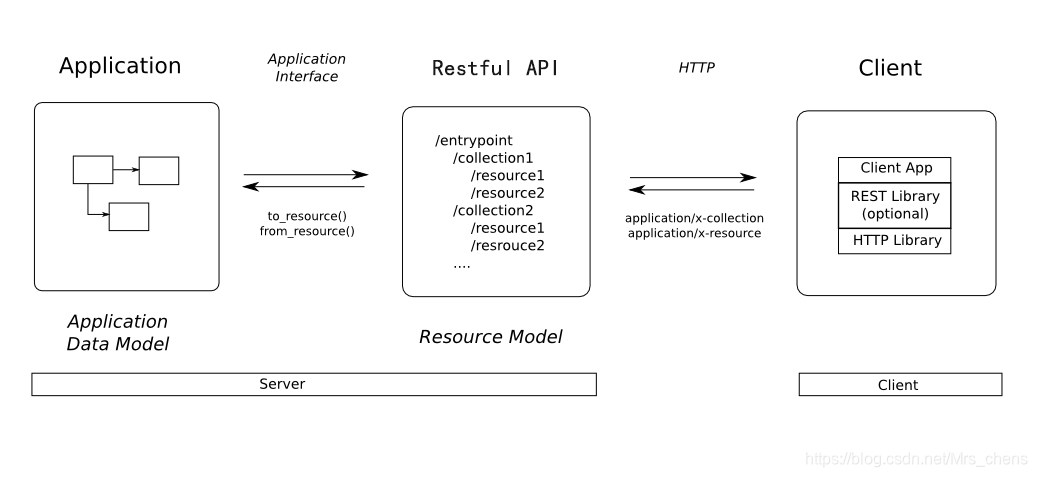
1. 创建高效可维护的API接口
1.1 接口设计的重要性
在如今的软件开发中,高效且可维护的API接口是连接前端与后端、服务与服务的重要纽带。好的API设计不仅能提升系统的交互效率,还能确保在维护和迭代过程中的可扩展性。设计一个成功的API接口需要深入理解业务需求,遵循最佳实践,并且考虑到了安全性、性能和可读性。
1.2 设计原则
设计API接口时应遵循一些核心原则,包括: - 简洁性 :尽量使用直观的URL路径和简洁的HTTP方法。 - 一致性 :确保整个API的设计风格一致,如使用相同的命名规则和响应格式。 - 可预测性 :统一的API设计模式可以减少用户的学习成本。 - 版本管理 :为API提供版本控制,以支持新旧系统间的平滑过渡。
1.3 开发流程
一个高效的API开发流程通常包括以下步骤: 1. 需求分析 :明确API的目标用户、使用场景和功能需求。 2. 设计阶段 :创建API的蓝图,包括资源定义、端点设计和协议选择。 3. 实现阶段 :编写代码实现设计好的API功能,遵循编程规范。 4. 文档编写 :编写API文档,方便开发者理解和使用。 5. 测试阶段 :通过单元测试、集成测试确保API的稳定性和性能。 6. 部署上线 :将API部署到服务器,进行性能监控和日志记录。 7. 持续维护 :根据用户反馈进行API的迭代优化和更新。
在后续章节中,我们将深入探讨如何使用GraphQL和REST架构风格设计和实现高效、可维护的API,以及如何通过异步HTTP客户端和Python3来优化API开发过程。
2. GraphQL查询语言的使用与效率
2.1 GraphQL的基本概念和特点
2.1.1 GraphQL的起源和发展
GraphQL是Facebook在2012年开发出的用于API的查询语言。在此之前,Facebook已经在使用REST API,但随着应用的复杂度和移动客户端的迅速发展,他们遇到了一些挑战,例如过度获取(over-fetching)和不足获取(under-fetching)的问题,客户端经常需要多个请求才能获取所需数据,这导致了低效率和性能瓶颈。
为了解决这些问题,GraphQL引入了一个查询语言,允许客户端指定他们所需要的数据结构,服务端则精确返回这一结构的数据,从而提高了性能,减少了网络传输的数据量,也降低了前后端的耦合度。
2.1.2 GraphQL的核心优势
GraphQL的核心优势在于其类型系统和查询语言,它允许开发者构建复杂的查询,可以精确地获取所需数据,而无需加载不必要的信息。这种按需获取数据的方式使得GraphQL非常适合构建高度交互的Web和移动应用。
另外,GraphQL还具有强大的类型系统。通过类型定义(type definition),开发者可以清晰地定义API的结构,并通过工具自动生成文档。此外,类型系统允许服务端执行更严格的验证,确保查询的正确性和安全性。
2.2 GraphQL的类型系统和查询
2.2.1 GraphQL的类型定义
类型定义是GraphQL的核心,通过定义数据模型和可能的操作来构建API。每一种类型(Type)都对应着一种数据结构,例如对象、枚举、接口等。类型系统还支持特性,比如联合(Unions)和接口(Interfaces),使得构建复杂的数据模型变得简单。
类型定义通常包含以下几个部分: - 对象类型(Object Type):定义了可以获取的字段和获取方式。 - 输入类型(Input Type):用于参数化查询,允许创建复杂的查询结构。 - 枚举类型(Enum Type):限制某个字段的值必须是枚举类型中定义的一个。 - 联合类型(Union Type):表示可以是多种对象类型中的任意一种。 - 接口类型(Interface Type):定义一组对象类型必须实现的字段。
下面是一个简单的类型定义示例:
type Book {
id: ID!
title: String!
author: Author!
}
type Author {
id: ID!
name: String!
books: [Book!]!
}
type Query {
book(id: ID!): Book
allBooks: [Book!]!
}
2.2.2 构建高效查询的方法
为了构建高效的查询,开发者需要遵循一些最佳实践,比如避免深层嵌套查询,因为这会导致不必要的复杂性和潜在的性能问题。查询的深度和宽度都应该适度,以优化网络传输和响应时间。
举个例子,下面的查询是高效且结构良好的:
{
author(id: "123") {
name
books {
title
publishedYear
}
}
}
而以下查询由于过度嵌套,可能会导致性能问题:
{
author(id: "123") {
name
books {
title
publishedYear
author {
name
birthday
books {
title
publishedYear
author {
name
# ...
}
}
}
}
}
}
在构建高效查询时,应该尽可能扁平化查询结构,并使用批处理和缓存策略,这样可以在提高性能的同时减少服务器负载。
2.3 GraphQL的实现与性能优化
2.3.1 常见GraphQL框架的选择与应用
GraphQL可以应用于多种后端技术栈,包括但不限于Node.js、Python、Ruby等。对于Node.js,最流行的GraphQL框架之一是Apollo Server,它提供了与Express.js的无缝集成,并支持多种数据源。
对于Python开发者,Graphene是一个流行的库,它提供了与Django和SQLAlchemy等框架的集成方式。通过选择合适的框架,开发者可以快速启动并实现GraphQL API。
选择合适的GraphQL框架时,需要考虑以下因素: - 语言和框架支持 - 社区和文档 - 性能和资源消耗 - 第三方插件和扩展的可用性
2.3.2 优化GraphQL查询性能的策略
性能优化对于任何API都是至关重要的,对于GraphQL而言,优化策略可以分为几个方面: - 缓存机制 :由于GraphQL允许客户端自定义查询,这意味着对于相同的查询结果,服务端需要能够缓存结果,避免重复的计算。Apollo Server提供了强大的缓存策略,包括针对字段级别的缓存。 - 批处理查询 :批处理可以减少服务器和数据库的请求次数。通过将多个查询合并为一个请求,可以减少网络延迟和数据库负载。 - 延迟加载(Lazy Loading) :在需要的时候加载数据可以优化内存使用和提高响应速度。延迟加载可以在查询字段上设置,确保只有在真正需要数据时,才会进行加载。 - 限制查询深度和复杂度 :为了防止恶意使用,可以限制查询的深度和复杂性,以保护服务端不被过度消耗。
使用以下代码片段作为缓存机制的一个示例:
const { ApolloServer, gql } = require('apollo-server');
const server = new ApolloServer({
typeDefs,
resolvers,
cacheControl: {
defaultMaxAge: 500, // 默认缓存500秒
},
});
优化策略需要根据实际应用场景和数据结构进行定制,没有一成不变的规则。通过持续监控和评估,开发者可以找到最适合其API的优化方案。
3. REST架构风格与CRUD操作原则
REST(Representational State Transfer,表述性状态转移)架构风格是一种在分布式系统中,特别是网络中实现资源操作的一种架构风格。它最早由Roy Fielding在其博士论文中提出,旨在简化Web服务的设计。REST通过一组固有的约束来优化客户端和服务器之间的交互,以此提高系统的可伸缩性、简单性、可修改性和可维护性。
3.1 REST架构风格的介绍
3.1.1 REST的核心理念和原则
REST的核心理念是将网络中的每个“事物”抽象为资源,并通过HTTP协议提供的标准方法(如GET、POST、PUT、DELETE等)对资源进行操作。REST架构风格的约束条件包括:
- 无状态 :服务器不保存客户端状态,每次请求都包含全部信息,简化服务器设计,提升资源利用率。
- 统一接口 :通过一套标准的操作接口来处理资源,例如HTTP协议中的GET、POST、PUT和DELETE,使得整个系统高度解耦。
- 可缓存 :支持服务器对请求结果进行缓存,减少网络延迟和带宽消耗。
- 客户端-服务器分离 :将用户界面关注与数据存储分离,降低复杂性,提升可移植性和可维护性。
- 系统分层 :通过分层架构提供更高级别的抽象,允许各层独立演化,简化单个组件的设计。
3.1.2 REST与传统Web服务的区别
REST与传统的Web服务(如SOAP)在实现方式和设计哲学上存在显著不同。传统Web服务通常使用WS-*标准,是一种严格定义了消息格式和服务接口的方式。而REST则基于Web的现有架构,使用URL和HTTP方法来实现资源的CRUD操作,并且不强制要求复杂的传输协议。
在实现复杂度和互操作性方面,REST通常被认为是更为简洁和易于实现的选择。它不依赖于特定的传输协议,使得任何能够访问HTTP的客户端都可以无缝地与RESTful服务进行交互,无需额外的抽象层。
3.2 RESTful API的设计实践
3.2.1 RESTful API设计的最佳实践
为了充分利用REST架构风格的优势,设计RESTful API时应该遵循一些最佳实践:
- 使用HTTP动词 :根据HTTP标准使用GET、POST、PUT、DELETE等动词来表达资源状态的转换。
- 资源的名词化 :资源通过名词表示,如使用“/users”代替“/addUser”。
- 合理使用状态码 :充分利用HTTP状态码来表示操作的成功、失败及其它状态。
- 幂等性 :保证GET、PUT、DELETE等操作的幂等性,即操作的多次执行与单次执行结果一致。
- 版本控制 :若API会不断迭代更新,考虑使用版本号以保持向后兼容性。
- 超媒体驱动 :利用超媒体提供资源间导航,有助于构建自描述的消息,使API更易于使用。
3.2.2 资源和URL的设计规范
在设计RESTful API的URL时,需要注意以下规范:
- 清晰的资源路径 :资源路径应该语义化,如“/orders/1234”中的“orders”表示订单资源,而“1234”是订单资源的唯一标识符。
- 使用子资源表示关系 :如果需要表示资源间的关系,可以在URL中创建子路径,如“/users/1234/orders”。
- 避免在URL中使用动词 :动词应该由HTTP方法来表示,如使用GET /orders来获取订单列表,而不是使用一个如“/getOrders”的URL。
- 使用复数名词 :URL中的资源名称应该使用复数形式,如“/orders”而不是“/order”。
- 过滤、排序和分页 :如果需要,可以通过查询参数提供过滤、排序和分页功能,如“/orders?status=active&page=2”。
3.3 RESTful API的CRUD操作
RESTful API通过HTTP协议标准方法实现对资源的创建(Create)、读取(Read)、更新(Update)和删除(Delete)操作。
3.3.1 创建(Create)操作的实现
创建资源通常使用POST请求,并在请求体中提供资源的表示。服务器接收到POST请求后,会创建一个新资源并返回资源的URL。例如,创建一个新订单的请求可能如下:
POST /orders HTTP/1.1
Host: example.com
Content-Type: application/json
{
"customer_id": "5678",
"items": ["item1", "item2"],
"total_amount": 150.00
}
如果创建成功,服务器将返回HTTP 201状态码,并在响应头中提供新创建资源的URI。
3.3.2 读取(Read)操作的实现
读取操作使用GET请求来实现。GET请求用于从服务器检索资源,不会对资源造成任何改变。例如,检索一个特定订单的请求如下:
GET /orders/1234 HTTP/1.1
Host: example.com
如果资源存在,服务器将返回HTTP 200状态码,并在响应体中返回该资源的表示。
3.3.3 更新(Update)操作的实现
更新操作通常通过PUT或PATCH请求来完成。PUT请求通常要求客户端提供资源的全部表示,而PATCH请求则只需要提供需要更新的部分。更新成功后,服务器返回HTTP 200或204状态码以表示操作成功。例如,更新订单信息的请求如下:
PUT /orders/1234 HTTP/1.1
Host: example.com
Content-Type: application/json
{
"status": "shipped"
}
3.3.4 删除(Delete)操作的实现
删除操作使用DELETE请求来实现。客户端发送DELETE请求到服务器后,服务器删除指定资源,并返回HTTP 200或204状态码表示删除成功。例如,删除一个订单的请求如下:
DELETE /orders/1234 HTTP/1.1
Host: example.com
在实际应用中,开发者需要注意合理使用资源的创建、读取、更新和删除操作,以确保API的高效性和系统的稳定性。通过RESTful API的CRUD操作,开发者可以构建出结构清晰、易于理解和维护的Web服务。
4. 异步HTTP客户端在Python3中的应用
4.1 异步编程的基本概念
4.1.1 同步与异步编程的对比
在同步编程模型中,代码的执行顺序和语句的顺序是一致的。每个操作必须等待前一个操作完成后才能开始。这种模型易于理解和实现,但在进行I/O操作或网络请求时会导致CPU资源的浪费,因为等待I/O操作完成的时间内CPU可能处于空闲状态。
异步编程则允许在等待一个长时间运行的任务(如I/O操作)时继续执行其他任务,从而提高程序的效率。在异步模型中,程序可以在一个操作等待时继续执行其他操作,而不是阻塞等待。这种方式特别适合于I/O密集型的应用程序,如网络服务和Web应用。
4.1.2 异步编程的优势与适用场景
异步编程的优势主要体现在以下几个方面:
- 提高效率:能够充分利用系统资源,特别是在高并发场景下,异步编程可以显著提升系统处理请求的能力。
- 减少延迟:通过异步操作,应用程序可以在等待I/O操作时处理其他任务,从而减少响应时间。
- 降低资源消耗:相比传统同步模型,异步模型中由于减少了线程的创建与销毁,可以降低资源消耗。
异步编程适用于I/O密集型操作,例如网络请求、数据库操作、文件系统操作等,这些操作通常涉及到等待外部资源的响应。对于CPU密集型操作,由于异步编程需要频繁的上下文切换,可能不是最佳选择。
4.2 异步HTTP客户端库的介绍
4.2.1 异步HTTP客户端库的选择
在Python3中,有几个流行的异步HTTP客户端库可供选择,包括但不限于 aiohttp , httpx , 和 requests-async 。这些库都支持异步IO库如 asyncio ,但每个库都有其独特的特点和优势。
aiohttp 是一个强大的库,支持HTTP客户端/服务器的异步框架。它的灵活性和性能使其成为一个受欢迎的选择。
httpx 是一个现代的HTTP客户端,它为异步和同步操作提供了一个统一的API,并且还支持HTTP/2和async/await。
requests-async 是基于著名的同步HTTP库 requests 的异步版本,它的API与 requests 相似,因此对于那些熟悉 requests 的开发者来说更容易上手。
4.2.2 异步HTTP客户端的基本使用方法
下面是一个使用 aiohttp 库发送异步HTTP GET请求的简单示例:
import aiohttp
import asyncio
async def fetch_data(session, url):
async with session.get(url) as response:
return await response.text()
async def main():
async with aiohttp.ClientSession() as session:
html = await fetch_data(session, 'http://python.org')
print(html)
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
在这个例子中, fetch_data 函数是一个异步函数,它接受一个会话和一个URL作为参数,并执行一个异步的GET请求。使用 async with 语句可以保证会话的正确关闭。 main 函数创建了一个 aiohttp.ClientSession 实例,并用 fetch_data 来获取指定URL的内容。 loop.run_until_complete(main()) 启动异步事件循环并运行 main 函数直到完成。
4.3 实际项目中的应用技巧
4.3.1 异步HTTP请求的批量处理
在实际项目中,我们常常需要处理大量的HTTP请求。例如,一个数据聚合服务需要从多个不同的源获取数据。如果使用同步方法,会严重影响性能。此时,异步请求可以帮助我们并行地获取数据,提高整体的效率。
import aiohttp
import asyncio
async def fetch(session, url):
async with session.get(url) as response:
return await response.text()
async def fetch_all(urls):
tasks = []
async with aiohttp.ClientSession() as session:
for url in urls:
task = asyncio.create_task(fetch(session, url))
tasks.append(task)
return await asyncio.gather(*tasks)
urls = ['http://example.com', 'http://python.org', 'http://google.com']
results = asyncio.run(fetch_all(urls))
在这个批量处理的示例中,我们首先定义了一个 fetch 函数用于获取单个URL的内容。然后定义了一个 fetch_all 函数用于处理一个URL列表,创建了一个会话,并为每个URL创建了一个任务,最后使用 asyncio.gather 等待所有任务完成并返回结果。
4.3.2 异步IO在高并发场景的应用
在高并发场景下,异步IO可以帮助我们处理大量的并发连接,而不会耗尽系统资源。例如,在一个网络服务器中,我们可以使用异步编程来处理成千上万的客户端连接。
下面是一个使用 aiohttp 库创建一个简单的异步HTTP服务器的例子,它能够处理多个并发请求:
from aiohttp import web
async def handle(request):
name = request.match_info.get('name', "Anonymous")
text = "Hello, " + name
return web.Response(text=text)
async def wshandler(request):
ws = web.WebSocketResponse()
await ws.prepare(request)
async for msg in ws:
if msg.type == web.MsgType.text:
await ws.send_str("Hello, %s" % msg.data)
elif msg.type == web.MsgType.binary:
await ws.send_bytes(msg.data)
return ws
app = web.Application()
app.add_routes([web.get('/', handle), web.get('/ws', wshandler)])
web.run_app(app)
在这个例子中,我们创建了一个web应用,它有两个路由处理函数:一个是 handle 函数用于处理HTTP GET请求,另一个是 wshandler 函数用于处理WebSocket连接。这个web服务器能够处理大量的并发连接,并且由于使用了异步IO,不会因为连接数量的增加而出现性能问题。
5. Python3在API开发中的优势
Python是一种动态类型的高级编程语言,因其易于学习和使用,它在API开发领域中非常流行。Python 3作为该语言的最新主要版本,引入了一系列新特性和改进,这些优势为API开发带来了更多可能性。本章将探讨Python 3的特性和生态系统、在Web框架和API开发方面的应用,以及如何利用其高级特性优化API设计。
5.1 Python3语言特性与生态系统
Python 3的发布标志着该语言的一次重大升级。它解决了先前版本中的许多问题,并引入了现代化的语言特性。这些特性提高了Python在现代开发环境中的适用性,特别是在Web开发和API实现方面。
5.1.1 Python3的新特性和改进
Python 3相较于Python 2带来了很多新特性和改进,这包括但不限于:
- 字符串格式化更新 :从
%和str.format()升级到f-string,提供更简洁和直观的方式来格式化字符串。 - 异步编程 :通过
async和await关键字,Python 3.5及以上版本为异步编程提供了内置支持。 - 改进的类型注解 :允许开发者为函数和变量指定类型,增强了代码的可读性和健壮性。
- 增强的内存管理 :改善了垃圾回收机制,提高了内存使用效率。
5.1.2 Python在Web开发中的广泛应用
Python在Web开发中拥有广泛的生态系统,主要得益于像Django和Flask这样的高级Web框架。这些框架提供了丰富的内置功能,使得开发者能够快速搭建和部署Web应用。Django的“一站式”特性提供了模型、视图、模板和管理工具等完整的Web开发套件。而Flask则因其轻量级和灵活性受到众多开发者的喜爱,特别是对于微服务架构而言。
5.2 Python3的Web框架与API开发
Python 3的Web框架为API开发提供了坚实的基础。这些框架根据不同的项目需求提供了不同的功能和优势。
5.2.1 Django与Flask框架的API开发对比
Django和Flask虽然都是Web开发框架,但它们在API开发方面有着不同的优势。
- Django REST framework :在Django之上构建的框架,非常适合构建RESTful Web服务。它提供了强大的序列化工具、灵活的路由系统和开箱即用的权限控制等功能。
- Flask与Flask-RESTful :Flask是一个轻量级的框架,通过Flask-RESTful扩展,它可以非常快速地创建RESTful服务。由于其轻量级特性,Flask特别适合于创建微服务或小型API。
5.2.2 Python3异步框架的API开发实践
异步框架如FastAPI和Starlette为API开发带来了新的可能性。这些框架基于Python 3.5+的异步特性,能够处理大量的并发连接,非常适合高负载的API服务。
- FastAPI :利用Python的类型注解,它能够提供自动的API文档(Swagger UI)和数据验证功能,简化了API开发流程。
- Starlette :是一个轻量级的异步框架,提供了许多用于构建Web服务和API的组件。它也可以作为基础框架来构建更复杂的异步Web应用程序。
5.3 Python3的高级特性在API中的应用
Python 3提供了高级特性,这些特性使得API开发更加高效和可维护。
5.3.1 装饰器模式在API开发中的运用
装饰器模式是Python中的一个强大特性,允许开发者在不修改原有函数定义的情况下,为函数添加额外的行为。在API开发中,装饰器被广泛用于权限检查、日志记录和性能分析等场景。
from functools import wraps
import logging
def log_function_data(func):
@wraps(func)
def wrapper(*args, **kwargs):
logging.info(f"Calling function '{func.__name__}' with args: {args} and kwargs: {kwargs}")
result = func(*args, **kwargs)
logging.info(f"Function '{func.__name__}' returned: {result}")
return result
return wrapper
@log_function_data
def add(x, y):
return x + y
add(4, 5)
在上面的代码示例中, log_function_data 装饰器负责记录函数调用的时间和参数。应用这个装饰器到 add 函数上将自动为这个函数添加日志记录的功能。
5.3.2 元编程技巧在API设计中的应用
元编程是Python的另一个高级特性,它允许程序在运行时访问或修改其自身的结构或行为。在API设计中,使用元编程可以实现更灵活的数据模型和业务逻辑。
例如,可以使用属性装饰器 @property 来创建计算属性,这种属性不是存储在对象中,而是根据其他属性动态计算得出的值。
class Product:
def __init__(self, price, tax):
self._price = price
self._tax = tax
@property
def price(self):
return self._price
@property
def tax(self):
return self._tax
@property
def total_price(self):
return self.price + self.price * self.tax
product = Product(100, 0.2)
print(product.total_price) # 输出120
在这个例子中, total_price 是一个计算属性,它会在每次访问时根据 price 和 tax 属性计算得出。这种方式使得API设计更加简洁和直观。
Python 3的特性和生态系统的丰富性,使其在API开发中具有明显优势。随着技术的不断进步,Python 3也在不断地进化,为开发者提供了更多的工具和库来构建高效、安全、易于维护的API服务。
简介:本文档旨在提供关于构建高效、可维护且易于重用的Web API交互的深入指导。内容涵盖了GraphQL、REST、异步HTTP客户端技术、Python3编程和RPC等多种技术,同时着重讲解了requests库和aiohttp-client库的使用方法,以及如何通过API包装器提升代码的组织性和复用性。开发者通过学习这些知识点,将能够有效地开发和优化Web API服务,以应对各种编程挑战。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









