



 本文探讨了数据库分库分表在解决单机性能瓶颈和容量问题中的关键作用,回顾了数据库历史,介绍了拉伸存储、索引管理和一致性保障的策略,以及如何在电商、缓存、业务拆分和读写分离等场景中应用这些技术。
本文探讨了数据库分库分表在解决单机性能瓶颈和容量问题中的关键作用,回顾了数据库历史,介绍了拉伸存储、索引管理和一致性保障的策略,以及如何在电商、缓存、业务拆分和读写分离等场景中应用这些技术。
在服务器后端技术人员的成长路线上,分片(Sharding)思想的理解和把握是绕不过去的门槛,而数据库分库分表可能是讲述拆分思想最好的教材,大部分后端技术人员都会在成长过程中遇到数据库分库分表的问题。
单机数据库很容易出瓶颈,包含性能、容量等。一方面是存在放大效应。比如:业务强要求所有的请求在100ms返回,这100ms分配到数据库,可能留的时间也就1-2ms,任何数据库的波动,会被放大10-20倍反应到上层服务;另一方面是存在单点问题,数据库保持了最新且最准确的状态,这个状态增长是随业务增长同步的,且业务的增长会导致业务的复杂性,复杂性最后反应到数据库的存储里代表的就是增量。数据库需要应对随业务增长指数上升的数据增量,且数据库系统本身通过单点性,来保持状态的准确性,很容易遇到单机的性能问题。
而分库分表就是大多数互联网公司遇到数据库瓶颈后,解决瓶颈的近乎行业标准手段。
我们回顾数据库发展的历史,数据库是怎么发展起来的?它在先解决什么问题?为什么现在会有瓶颈的问题?
计算机的本质是满足可计算性的快速计算。而数据库系统的本质是,随着计算力扩大随之匹配的对数据的储存和管理能力。最早的编程是通过在纸带上打孔来完成计算步骤的编写,输出的也是纸带。数据库就是对一系列纸带的管理,还别说,那时候就有搜索的需求了。
1968年,IBM做出了第一现代意义上的数据库系统DBMS,除了没有SQL的支持,但是基本上已经是完善的现代数据库了,拥有现代数据库应有的存储、检索、状态一致等功能。
1970年后关系型数据库兴起,那时候搞关系型数据库的公司,就像现在专门做NewSQL的数据库那么的酷。Oracle 是关系型数据库最终的胜利者。如果去深挖这段历史,确实是IBM的员工在1974 年的时候提出了SQL的观点,但是在1979年,Oracle最终第一个做出了关系型数据库。
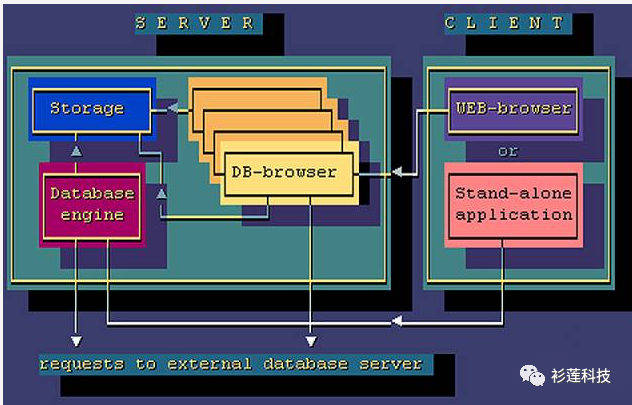
为什么现在会有数据库瓶颈的问题,在我看来就是,单机的到计算瓶颈了,计算的部分可以快速转向分布式、大规模的集群。而数据库存储做集群的方式很难。对于单机应用来说,数据库基本上没有瓶颈,对于互联网公司来说,流量在不停的拆分,保证单台机器的处理负载在可处理范围内,但是因为数据库本身是一个针对单机的系统,同时需要保证一致性状态,所以更容易到瓶颈。数据库系统原本就是一个支持索引、一致性和存储相对平衡的单机应用,一旦想要扩展分布,那就要做一些权衡。
在我看来,数据库分库分表就是拉伸存储,适度牺牲索引和一致性的一个折中方案。
拉伸储存,本质上就是通过减少需要计算的数据量,来换取计算速度的提升。所以拆分依据就是:如何让计算速度最快那就如何拆分。因此在实际企业业务中,贴子系统适合按日期分库分表、交易系统适合冷热数据分类、长期有效的商品系统适合按照Hash水平拆分。
缓存式的Web应用程序架构,在Web层和db层之间加一层cache层,主要目的:减少数据库读取负担,提高数据读取速度。cache存取的媒介是内存,可以考虑采用分布式的cache层,这样更容易破除内存容量的限制,同时增加了灵活性。
业务拆分,电商平台,包含了用户、商品、评价、订单等几大模块,最简单的做法就是在一个数据库中分别创建users、shops、comment、order四张表。但是,随着业务规模的增大,访问量的增大,我们不得不对业务进行拆分。每一个模块都使用单独的数据库来进行存储,不同的业务访问不同的数据库,将原本对一个数据库的依赖拆分为对4个数据库的依赖,这样的话就变成了4个数据库同时承担压力,系统的吞吐量自然就提高了。
主从复制,读写分离当数据库的写压力增加,cache层(如Memcached)只能缓解数据库的读取压力。读写集中在一个数据库上让数据库不堪重负。使用主从复制技术(master-slave模式)来达到读写分离,以提高读写性能和读库的可扩展性。读写分离就是只在主服务器上写,只在从服务器上读,基本原理是让主数据库处理事务性查询,而从数据库处理select查询,数据库复制被用于把事务性查询(增删改)导致的改变更新同步到集群中的从数据库。
分表分库,在cache层的高速缓存,数据库的主从复制,读写分离的基础上,这时数据库主库的写压力开始出现瓶颈,而数据量的持续猛增,由于MyISAM使用表锁,在高并发下会出现严重的锁问题,大量的高并发应用开始使用InnoDB引擎代替MyISAM。采用Master-Slave复制模式的数据库架构,只能对数据库的读进行扩展,而对数据的写操作还是集中在Master上。这时需要对数据库的吞吐能力进一步地扩展,以满足高并发访问与海量数据存储的需求。
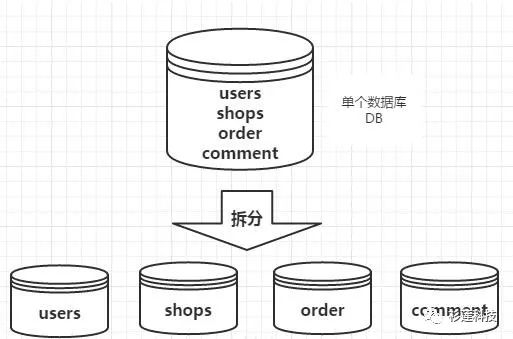
对于访问极为频繁且数据量巨大的单表来说,首先要做的是减少单表的记录条数,以便减少数据查询所需的时间,提高数据库的吞吐,这就是所谓的分表。在分表之前,首先需要选择适当的分表策略,使得数据能够较为均衡地分布到多张表中,并且不影响正常的查询。
分表能够解决单表数据量过大带来的查询效率下降的问题,但是却无法给数据库的并发处理能力带来质的提升。面对高并发的读写访问,当数据库master服务器无法承载写操作压力时,不管如何扩展Slave服务器都是没有意义的,对数据库进行拆分,从而提高数据库写入能力,即分库。
数据库经过业务拆分及分库分表,虽然查询性能和并发处理能力提高了。但是原本跨表的事务上升为分布式事务;由于记录被切分到不同的库和不同的表中,难以进行多表关联查询,并且不能不指定路由字段对数据进行查询。且分库分表后需要进一步对系统进行扩容(路由策略变更)将变得非常不方便,需要重新进行数据迁移。
如何保障索引的高效性?
一定要理解,索引和存储是相关隔离的两件事,而对于数据库来说,强行提升了储存,而索引就是需要付出的代价。
当存储分布之后,单机的索引是无法满足对索引的要求,而SQL是对索引更上一层的封装,会有一定程度的限制,比如:分库分表最多能满足两个维度的拆分,Join表这种操作就变得异常困难。如何解决呢?方法就是,简单索引逻辑靠中间件构建虚拟索引,复杂索引靠其他方式构建外置索引。
所有的分库分表的中间件的工作,无非是在数据源和业务应用之间封装一层虚拟的满足基本需要的索引。业务应用发送请求到中间件,中间件起到一部分索引的作用,判定需要到哪个库,哪个表来执行,这其实就是单机数据库,选择表过程的外置。中间件还有一个作用是,对涉及逻辑表的部分,进行一部分SQL逻辑改写,来最终判定到某些部分执行。
对于更复杂的查询要求,应用方需要单独构建另外的索引,即把索引单独拆出来做成一个系统,来满足检索需要。作为代价来说,外置的索引会比内置的索引相对慢些,这是在系统架构上需要注意的地方。但是作为大原则,尽量把计算逻辑放置在索引外进行。
如何保障一致性?
通过柔性分布式事务的方式来实现最终一致性,方式就是外置检查,某一动作失败时,往前回滚,不一定完全回滚数据状态,回滚到不影响发生其它业务逻辑的业务状态。比如下单、减库存,如果创建订单失败,那就需要释放库存,倒序回置状态。

















 2369
2369

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









