







简介:OpenCV是一个包含图像处理和计算机视觉算法的跨平台库,特别在Java环境中的应用非常强大。本文将探讨如何利用OpenCV进行人脸检测、图像抠图、人脸库训练和人脸识别,详细介绍Haar级联分类器、图像裁剪和复制、机器学习算法以及多线程和GPU加速等技术。这些技术是构建人脸识别系统的关键,并在多个实际应用领域中得到应用。
1. OpenCV简介
OpenCV(Open Source Computer Vision Library)是一个开源的计算机视觉和机器学习软件库。它最初由英特尔公司开发,现在由Willow Garage提供支持,是计算机视觉领域中应用最广泛的库之一。本章将介绍OpenCV的基本概念、核心功能以及它的跨平台特性。
1.1 OpenCV的历史与发展
OpenCV起源于1999年,由加里·布拉德斯基(Gary Bradski)开发,最初旨在促进学术界与工业界之间的信息交流与合作。随着时间的推移,OpenCV不断发展壮大,逐渐吸引了全球众多开发者和研究者的贡献。它支持多种编程语言,包括C++、Python和Java,并且可以在Windows、Linux、Mac OS、iOS和Android等平台上运行。
1.2 OpenCV的核心功能
OpenCV提供了一系列计算机视觉处理的工具,包括但不限于:
- 图像处理 :图像的读取、保存、显示、转换以及基本的图像操作如滤波、形态学操作等。
- 视频分析 :视频的读取与处理、运动分析、对象跟踪等。
- 高级功能 :结构化机器学习、特征检测、物体识别、人体姿态估计等。
1.3 OpenCV的跨平台特性
OpenCV之所以受到广泛欢迎,其中一个重要原因就是它的跨平台特性。开发者可以在不同的操作系统上使用相同的API进行开发。为了适应不同的平台,OpenCV提供了一系列配置选项,允许编译器优化代码以适应特定平台的硬件和软件环境。
接下来的章节将会详细探讨OpenCV在人脸检测、图像处理、机器学习等领域的具体应用与实践,以及如何优化OpenCV的性能并将其应用于多样化的实际场景中。
2. Haar级联分类器人脸检测
2.1 Haar级联分类器基础
2.1.1 Haar特征的数学原理
Haar特征是通过对比图像中矩形区域的像素强度和来进行特征提取的一种方法。这些特征通常用于人脸检测,因为人脸的某些基本结构能够通过Haar特征得到很好的表征。比如,眼睛和鼻子周围区域的像素和通常与脸颊和额头区域的像素和存在明显差异。
数学上,Haar特征可以描述为一系列相邻矩形区域的像素和之差。这些矩形区域可以重叠,从而对图像进行滑动窗口式的搜索。一个基本的Haar特征可以由两个矩形组成,通过对两个矩形区域的像素值进行计算,得到一个单一的数值,这个数值可以表征图像的局部特征。
通过累积这些简单特征的组合,可以形成更复杂的特征,以表征更复杂的图像结构。例如,通过多个矩形的组合,可以构造出用于检测人脸轮廓或者眼睛区域的特征。特征选择的策略通常是通过机器学习的方法,如Adaboost算法,来自动选择对人脸检测最有判别力的特征集。
# 示例代码:计算Haar特征的简单实现
def calculate_haar_feature(image, rectangle1, rectangle2):
# rectangle1 和 rectangle2 是两个定义了位置和大小的矩形区域
intensity1 = sum(image[y:y+h, x:x+w].sum() for y in range(rectangle1[1], rectangle1[1]+rectangle1[3], rectangle1[3])
for x in range(rectangle1[0], rectangle1[0]+rectangle1[2], rectangle1[2]))
intensity2 = sum(image[y:y+h, x:x+w].sum() for y in range(rectangle2[1], rectangle2[1]+rectangle2[3], rectangle2[3])
for x in range(rectangle2[0], rectangle2[0]+rectangle2[2], rectangle2[2]))
return intensity1 - intensity2 # 特征值是两个区域强度的差值
在这段代码中,我们定义了一个计算Haar特征的简单函数。首先,我们需要传入图像矩阵以及两个矩形区域的定义,然后计算每个矩形区域内的像素和,最后返回两个矩形像素和的差值。
2.1.2 级联分类器的构建过程
级联分类器是一个基于多个弱分类器构建的强分类器,它在分类决策时逐级剔除大量的背景样本,从而显著提高了分类器的运算效率。在人脸检测中,级联分类器可以快速地排除掉不包含人脸的图像区域,提高检测的准确性和速度。
构建级联分类器的过程涉及到从大量的正负样本中学习得到一系列弱分类器,然后将这些弱分类器串联起来形成最终的强分类器。首先,需要收集包含人脸的正样本图像以及不包含人脸的负样本图像。通过Adaboost算法训练,可以得到一系列的弱分类器,每个分类器都对区分人脸和非人脸的样本有最小的错误率。在级联的过程中,每个后续的分类器都会在前一个分类器的基础上进行优化,进一步提高检测的准确度。
最终的级联分类器是由多个这样的弱分类器构成的,它们按照一定的阈值进行级联,当一个图像通过了前一个分类器的检验,才会继续通过下一个分类器,直到所有的分类器都通过,才判定该区域为包含人脸的区域。这样,大部分不包含人脸的区域会在早期阶段就被剔除,而只有可能包含人脸的区域才会进行更复杂的检测。
2.2 人脸检测实战演练
2.2.1 OpenCV中人脸检测的API使用
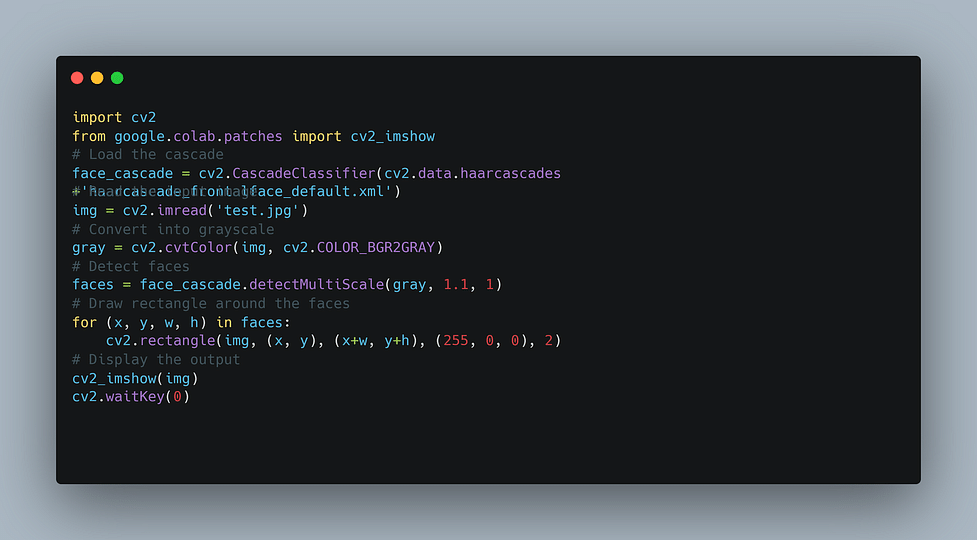
在OpenCV中,使用Haar级联分类器进行人脸检测主要涉及到了 CascadeClassifier 类。这个类提供了用于加载预训练的级联分类器模型,并进行人脸检测的接口。通常这些预训练的模型文件有着 .xml 的扩展名。在使用时,我们需要指定文件路径来初始化一个 CascadeClassifier 实例,并通过该实例的 detectMultiScale 方法来实现人脸的检测。
import cv2
# 初始化级联分类器
face_cascade = cv2.CascadeClassifier('path/to/haarcascade_frontalface_default.xml')
# 加载要检测的图像
image = cv2.imread('path/to/image.jpg')
# 执行人脸检测
gray_image = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) # 转换为灰度图
faces = face_cascade.detectMultiScale(gray_image, scaleFactor=1.1, minNeighbors=5, minSize=(30, 30))
# 绘制检测出的人脸矩形框
for (x, y, w, h) in faces:
cv2.rectangle(image, (x, y), (x+w, y+h), (255, 0, 0), 2)
# 显示结果
cv2.imshow('Face Detection', image)
cv2.waitKey(0)
cv2.destroyAllWindows()
在这段代码中,我们首先导入了 cv2 模块,并创建了 CascadeClassifier 对象,加载了Haar级联分类器模型。随后,我们读取了一张图像,并将其转换为灰度图,因为彩色图像不适用于Haar级联分类器。 detectMultiScale 方法会返回一个矩形列表,每个矩形代表了图像中检测到的人脸的位置和大小。我们遍历这个列表,在原图上绘制矩形框,并最终显示检测结果。
2.2.2 实际图像中的人脸检测案例分析
为了更好地理解上述代码是如何在实际图像中应用的,我们可以详细分析一个实际的人脸检测案例。首先,考虑一张包含多个人脸的图像。在应用 detectMultiScale 方法之前,我们需要对图像进行预处理,通常的预处理步骤包括将图像转换为灰度图,这有助于减少计算复杂度,并且对级联分类器的检测结果影响不大。
在得到检测结果后,每一帧图像中包含的人脸用一个矩形框标记出来。对于 detectMultiScale 方法,有多个参数需要调整,例如 scaleFactor 和 minNeighbors 。 scaleFactor 参数用于定义搜索窗口的大小变化比例,而 minNeighbors 参数则定义了每个候选窗口周围的邻居数量,以确保检测的准确性。调整这些参数可以针对不同的应用场景进行优化,以获得最佳的人脸检测性能。
graph LR
A[开始检测] -->|加载图像| B[转换为灰度图]
B --> C[应用 detectMultiScale]
C -->|参数调整| D[获取人脸位置]
D --> E[绘制人脸矩形框]
E --> F[显示结果]
F --> G[结束检测]
在实际案例中,通过调整 scaleFactor 和 minNeighbors 参数,可以有效地平衡检测速度和准确性。例如,在实时视频流中进行人脸检测时,我们可能倾向于提高速度,牺牲一些准确性。而在静态图像的人脸识别应用中,可以适当降低 minNeighbors 的值,以增加检测到的人脸数量,然后通过后续步骤进一步过滤掉误检的人脸。
在分析完这个案例后,我们能够了解到如何在实际图像中应用OpenCV进行人脸检测,以及如何根据实际需求调整参数以获得最佳效果。这为我们使用级联分类器进行更复杂的人脸识别应用打下了坚实的基础。
3. 图像裁剪与复制
在第三章中,我们将深入探讨图像处理的基本操作,特别是图像的裁剪与复制,以及一些进阶技巧,例如图像的旋转、缩放和色彩空间转换。这将有助于读者在进行图像分析和处理时具备更灵活的技能。
3.1 图像的基本操作
3.1.1 图像的裁剪技术
在图像处理中,裁剪是指从原始图像中选取一个子区域,并移除其余部分的操作。这一技术常用于提取图像的特定部分,以便进行进一步的分析或处理。
实现图像裁剪
在OpenCV中,可以使用 cv2.rectangle 函数辅助裁剪图像。下面是一个示例代码:
import cv2
# 加载图像
image = cv2.imread('example.jpg')
# 设置裁剪区域的坐标,从(350, 100)到(550, 400)
x, y, w, h = 350, 100, 200, 300
# 创建裁剪区域的矩形
roi = image[y:y+h, x:x+w]
# 显示原图
cv2.imshow('Original', image)
# 显示裁剪后的图像
cv2.imshow('Cropped', roi)
# 等待按键后退出
cv2.waitKey(0)
cv2.destroyAllWindows()
在该代码中,我们首先定义了裁剪区域的坐标和尺寸,然后根据这些坐标和尺寸对图像进行裁剪。 cv2.rectangle 函数用于绘制一个矩形区域,而 image[y:y+h, x:x+w] 则用于实际裁剪图像。
3.1.2 图像的复制与粘贴
图像的复制和粘贴技术涉及将一个图像或其部分复制到另一张图像上。这在图像拼接和合成中非常有用。
实现图像复制
在OpenCV中,我们可以使用NumPy的数组操作来完成图像的复制和粘贴。下面是一个示例:
import numpy as np
import cv2
# 加载源图像和目标图像
source_image = cv2.imread('source.jpg')
destination_image = cv2.imread('destination.jpg')
# 确定复制的源区域和目标区域
x, y, w, h = 100, 100, 200, 200 # 源图像中要复制的区域
x1, y1 = 50, 50 # 目标图像中要粘贴的位置
# 复制区域并粘贴到目标图像
destination_image[y1:y1+h, x1:x1+w] = source_image[y:y+h, x:x+w]
# 显示源图像和目标图像
cv2.imshow('Source', source_image)
cv2.imshow('Destination', destination_image)
# 等待按键后退出
cv2.waitKey(0)
cv2.destroyAllWindows()
在这段代码中,我们首先加载了源图像和目标图像。然后确定了从源图像中复制的区域和目标图像中粘贴的目标位置。通过简单的数组操作,我们将源图像的一部分复制到了目标图像的指定位置。
3.2 图像处理进阶技巧
3.2.1 图像的旋转与缩放
图像的旋转和缩放是图像处理中常见的操作,它们在图像预处理和视觉效果调整中占有重要地位。
实现图像旋转
图像旋转通常是指将图像绕中心点进行旋转。在OpenCV中,可以使用 cv2.getRotationMatrix2D 和 cv2.warpAffine 函数来实现图像的旋转。
import cv2
# 加载图像
image = cv2.imread('example.jpg')
# 获取旋转矩阵
angle = 45 # 旋转角度
rotation_matrix = cv2.getRotationMatrix2D((image.shape[1]/2, image.shape[0]/2), angle, 1)
# 旋转变换
rotated_image = cv2.warpAffine(image, rotation_matrix, (image.shape[1], image.shape[0]))
# 显示原图和旋转后的图像
cv2.imshow('Original', image)
cv2.imshow('Rotated', rotated_image)
# 等待按键后退出
cv2.waitKey(0)
cv2.destroyAllWindows()
在这段代码中,我们首先获取了图像的尺寸,然后指定了旋转角度和旋转矩阵,最后应用了旋转变换到图像上。
实现图像缩放
图像缩放是调整图像大小的过程。在OpenCV中,可以使用 cv2.resize 函数来实现缩放。
import cv2
# 加载图像
image = cv2.imread('example.jpg')
# 设置缩放比例
scale_factor = 0.5
# 缩放图像
resized_image = cv2.resize(image, None, fx=scale_factor, fy=scale_factor, interpolation=cv2.INTER_AREA)
# 显示原图和缩放后的图像
cv2.imshow('Original', image)
cv2.imshow('Resized', resized_image)
# 等待按键后退出
cv2.waitKey(0)
cv2.destroyAllWindows()
在这段代码中,我们通过 scale_factor 定义了缩放的比例,然后使用 cv2.resize 函数实现了图像的缩放。 fx 和 fy 参数分别代表水平和垂直方向上的缩放因子。
3.2.2 图像的色彩空间转换
色彩空间转换是图像处理中的一个重要部分,不同的色彩空间在不同的应用场合下有不同的优势。例如,从RGB色彩空间转换到HSV色彩空间,可以帮助更好地处理颜色信息。
实现色彩空间转换
在OpenCV中,可以使用 cv2.cvtColor 函数来实现色彩空间的转换。
import cv2
# 加载图像
image = cv2.imread('example.jpg')
# 将图像从BGR色彩空间转换到HSV色彩空间
hsv_image = cv2.cvtColor(image, cv2.COLOR_BGR2HSV)
# 显示原图和转换后的图像
cv2.imshow('Original', image)
cv2.imshow('HSV', hsv_image)
# 等待按键后退出
cv2.waitKey(0)
cv2.destroyAllWindows()
在这段代码中,我们首先加载了图像,然后使用 cv2.cvtColor 函数将图像从BGR色彩空间转换到HSV色彩空间。最后,展示了转换前后的图像。
在本节中,我们详细讨论了图像裁剪、复制、旋转、缩放以及色彩空间转换的基本操作。通过这些技术,我们可以对图像进行更深入的处理,为后续的分析和应用打下坚实的基础。
4. 机器学习算法和人脸库训练
4.1 机器学习在人脸检测中的应用
4.1.1 机器学习算法概述
在当今的智能系统中,机器学习已经成为实现复杂功能的关键技术之一,尤其在人脸检测及识别领域,机器学习方法能够显著提升算法的准确性和鲁棒性。机器学习算法主要分为监督学习、无监督学习、半监督学习和强化学习等几类。在人脸检测中,我们通常使用的是监督学习算法,特别是分类器,比如支持向量机(SVM)、随机森林、深度神经网络(DNN)等。
支持向量机(SVM)通过在特征空间中找到一个最优的超平面,以实现对数据的有效分类。随机森林是一种集成学习方法,通过构建多个决策树并进行集成投票,以达到提高分类准确率的目的。深度神经网络尤其卷积神经网络(CNN)则通过模拟人脑处理信息的方式,对图像数据进行高度抽象和特征提取,从而达到识别和分类的目的。
4.1.2 训练数据集的准备与预处理
在使用机器学习方法进行人脸检测之前,必须准备充分且质量高的训练数据集。这些数据集通常需要经过预处理,以保证它们适合于训练。数据预处理包括数据清洗、数据增强、数据规范化等步骤。
数据清洗主要是去除数据集中的无关或错误样本,以减少噪声和提高数据质量。数据增强通过对现有数据进行旋转、缩放、裁剪、颜色变换等操作,人为地扩充训练集的规模和多样性,从而使模型更具泛化能力。数据规范化则涉及将图片转换成统一的尺寸、标准化像素值范围等,确保输入到模型中的数据格式一致,有助于模型的收敛。
4.2 人脸库训练过程详解
4.2.1 训练集与测试集的划分
为了评估训练出的人脸检测模型的实际性能,需要将数据集划分为训练集和测试集。训练集用于训练模型,而测试集则用于验证模型的泛化能力。一个常用的数据集划分比例是80%作为训练集,20%作为测试集。在某些情况下,还可能需要验证集来调整模型的超参数。
划分过程中需确保训练集和测试集中的人脸数据分布尽可能一致,避免数据不平衡导致的性能评估偏差。通常使用随机划分的方法来达到这一目标。对于有标注数据的场景,还可以采用交叉验证等策略来进一步确保模型的评估结果更接近实际情况。
4.2.2 训练过程中的参数调优
在训练过程中,不同的机器学习算法有不同的超参数需要调整。例如,在使用SVM时,核函数的类型及其参数、惩罚因子等都需要仔细选择。在随机森林算法中,树的数量、树的深度、分裂节点所需的最小样本数等都需经过优化。对于DNN,学习率、批大小、迭代次数等参数则是调优的关键点。
参数调优通常采用网格搜索(Grid Search)、随机搜索(Random Search)或贝叶斯优化等方法。网格搜索穷举地尝试所有参数组合,虽然全面但计算量大;随机搜索在参数空间中随机选取组合进行尝试,效率较高,但可能遗漏最优解;贝叶斯优化则基于先验概率模型来选择参数组合,通常能找到更好的超参数配置,且计算效率较高。
实际代码实现与解析
为了演示如何准备训练数据集,并使用机器学习库训练人脸检测模型,以下是一个使用Python和scikit-learn库训练简单SVM分类器的示例代码。
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn import svm
from sklearn.metrics import classification_report, accuracy_score
# 加载数据集(这里以鸢尾花数据集作为示例,实际应用中应替换为人脸数据集)
iris = datasets.load_iris()
X = iris.data
y = iris.target
# 划分数据集为训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 数据规范化
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
# 创建SVM分类器
clf = svm.SVC(kernel='linear') # 选择线性核
# 训练模型
clf.fit(X_train, y_train)
# 预测测试集结果
y_pred = clf.predict(X_test)
# 输出结果
print(classification_report(y_test, y_pred))
print(f"Accuracy: {accuracy_score(y_test, y_pred)}")
在上述代码中,我们首先导入了必要的库,然后加载了数据集。随后,我们使用 train_test_split 函数将数据集分为训练集和测试集,并使用 StandardScaler 对数据进行了规范化。接着,我们实例化了一个线性核的SVM分类器,并用训练集数据训练它。最后,我们在测试集上进行预测,并输出了分类结果报告和准确率。
通过这个例子,我们可以看到,使用机器学习库进行模型训练和预测的基本流程。在实际应用中,只需更换合适的数据集和调整模型参数,即可适应不同场景的人脸检测任务。
在本节中,我们详细讨论了机器学习算法在人脸检测中的应用,并对训练数据集的准备与预处理、训练集与测试集的划分、训练过程中的参数调优进行了深入的分析。接下来,我们将进一步深入探讨如何进行人脸库训练过程的详解,包括更复杂的模型训练和参数调优等议题。
5. Java接口和图像处理功能
5.1 Java与OpenCV的交互
5.1.1 Java接口的安装与配置
在开始用Java编写图像处理程序之前,必须确保已经安装并配置好了Java开发环境和OpenCV的Java接口。这一小节我们将介绍如何在Windows系统上安装并配置OpenCV的Java接口。
首先,下载OpenCV的Java库(opencvJavaXXX.zip),其中XXX代表版本号。接着,解压这个文件到一个指定的文件夹中。之后,需要将 opencv-XXX.jar 文件添加到Java项目的构建路径中。这一步可以通过IDE(如IntelliJ IDEA或Eclipse)完成,也可以使用命令行手动添加。
在命令行中,进入到解压后的文件夹,执行以下命令来添加到构建路径:
javac -cp opencv-XXX.jar YourJavaClass.java
java -cp opencv-XXX.jar;. YourJavaClass
在这里, YourJavaClass 是你的Java类文件名。注意,在Windows上,路径分隔符是分号(;),而在Linux或macOS上是冒号(:)。
在IDE中,你通常需要在项目的库设置中添加 opencv-XXX.jar 作为外部库。在IntelliJ IDEA中,你可以通过File -> Project Structure -> Libraries来添加新的库,选择本地的jar文件进行添加。
5.1.2 Java代码中调用OpenCV函数的方法
一旦完成了OpenCV Java库的安装和配置,就可以开始使用Java编写代码来调用OpenCV的函数了。OpenCV的Java接口在很大程度上保留了C++接口的命名和结构,因此对于熟悉C++接口的开发者来说,迁移成本相对较低。
以下是一个简单的Java示例,展示了如何加载一张图片并显示它:
import org.opencv.core.Core;
import org.opencv.core.Mat;
import org.opencv.imgcodecs.Imgcodecs;
import org.opencv.videoio.VideoCapture;
import org.opencv.videoio.Videoio;
public class ImageLoadShow {
static {
System.loadLibrary(Core.NATIVE_LIBRARY_NAME);
}
public static void main(String[] args) {
// 读取图片文件
Mat image = Imgcodecs.imread("path_to_image.jpg");
// 检查图片是否正确加载
if (image.empty()) {
System.out.println("无法加载图片");
return;
}
// 创建一个窗口
String windowName = "显示图片";
namedWindow(windowName, Videoio.Qt CAMERA阀门);
// 显示图片
imshow(windowName, image);
// 等待任意键盘按键
waitKey(0);
// 销毁所有窗口
destroyAllWindows();
}
}
在这段代码中,我们使用了 System.loadLibrary 来加载OpenCV本地库,然后使用 Imgcodecs.imread 方法加载了一张图片。接下来,我们通过 namedWindow 和 imshow 方法创建了一个显示窗口并展示了图片。 waitKey 函数用来等待用户按键操作,最后 destroyAllWindows 函数用来关闭所有打开的窗口。
5.2 Java中的高级图像处理技术
5.2.1 高级图像滤波与边缘检测
OpenCV提供了大量高级的图像处理函数,使得在Java中实现复杂的图像操作变得简单。比如,在进行边缘检测时,可以使用Canny边缘检测器,而对图像进行滤波可以使用高斯滤波、中值滤波等多种方法。
下面代码演示了如何在Java中使用OpenCV实现图像的Canny边缘检测和高斯滤波:
// Canny边缘检测
Mat edges = new Mat();
Imgproc.Canny(image, edges, 100, 200);
// 显示边缘检测结果
imshow("Canny边缘检测", edges);
// 高斯滤波
Mat blurred = new Mat();
Imgproc.GaussianBlur(image, blurred, new Size(5, 5), 0);
// 显示滤波后图像
imshow("高斯滤波", blurred);
在这段代码中, Canny 方法用于提取图像中的边缘,其中100和200为高阈值和低阈值。 GaussianBlur 方法用于对图像进行高斯模糊处理,其中 Size(5, 5) 为高斯核的大小,0表示核的标准差。
5.2.2 图像的特征提取与分析
图像特征提取是计算机视觉中的一个重要环节,它能帮助我们从图像中提取有用的信息。OpenCV提供了多种特征提取算法,如SIFT、SURF、ORB等。
下面代码演示了如何在Java中使用OpenCV的ORB特征检测算法提取和绘制关键点:
// 初始化ORB检测器
ORB orb = ORB.create();
// 寻找关键点和描述符
MatOfKeyPoint keypoints = new MatOfKeyPoint();
Mat descriptors = new Mat();
orb.detectAndCompute(image, new Mat(), keypoints, descriptors);
// 显示关键点
Mat imageWithKeypoints = image.clone();
Features2d.drawKeypoints(image, keypoints, imageWithKeypoints);
// 显示带关键点的图像
imshow("ORB特征检测", imageWithKeypoints);
在这段代码中, ORB.create 创建了一个ORB检测器对象, detectAndCompute 方法则用于检测图像中的关键点并计算它们的描述符。 drawKeypoints 方法用于将检测到的关键点绘制在原图像上,最后通过 imshow 显示出来。
以上内容是对Java接口和图像处理功能章节的深入探讨,为IT从业者提供了使用Java进行图像处理的相关知识和技能。通过安装和配置OpenCV的Java接口,我们能利用Java语言的强大功能来调用OpenCV的功能,实现复杂的图像处理算法,为后续的项目开发打下坚实的基础。
6. 人脸库管理与特征存储
6.1 人脸库的建立与维护
6.1.1 人脸图像的存储结构
人脸库是人脸识别系统的基础,它负责存储和管理大量的特征数据。在构建人脸库时,关键在于如何高效地存储和索引这些数据。对于人脸图像的存储结构,最常见的方式是利用数据库管理系统(DBMS)或者文件系统。
在使用数据库时,可以为每个人创建一个独立的数据记录,并存储其相关信息,例如姓名、唯一标识(如ID)、特征向量以及附加信息如注册时间、最后访问时间等。数据库提供了数据的高效存储、快速检索、事务管理等优势。
在文件系统中,可以将人脸图像文件存储在具有逻辑结构的文件夹中。例如,可以根据日期、地点或其它分组标准创建子文件夹。尽管文件系统不如数据库系统那样具有强大的查询能力,但它简单易用,易于实现。
6.1.2 人脸库的更新与优化策略
随着数据量的增长,人脸库的更新和优化变得至关重要。主要策略包括定期清理无效记录、优化索引结构和实现数据压缩。定期清理无效记录可以减少不必要的数据存储,保持人脸库的清洁和有效性。优化索引结构可以提高查询速度和减少检索时间。数据压缩不仅节省存储空间,也有助于降低数据传输的成本。
6.2 特征信息的存储与管理
6.2.1 特征提取方法的选择与应用
特征提取是人脸库管理中至关重要的一环,它决定了最终识别的准确度。常见的特征提取方法包括Eigenfaces、Fisherfaces、Local Binary Patterns Histograms (LBPH)等。Eigenfaces方法通过主成分分析(PCA)来提取人脸的主要特征,适用于处理大量数据。Fisherfaces方法基于线性判别分析(LDA),在保持类别区分性的同时减少了特征维度,适用于需要分类功能的场景。LBPH方法则侧重于局部特征的提取,适合于光照和表情变化较大的情况。
在实际应用中,选择哪一种特征提取方法取决于具体需求和数据特点。在一些情况下,甚至会将多种方法结合起来,以达到更优的识别效果。
6.2.2 特征数据的压缩与索引技术
特征数据的压缩是减少存储空间需求的重要手段,同时也能在一定程度上提高处理速度。例如,可以利用PCA方法提取主要成分以降维,或者使用特征选择算法去除冗余特征。此外,特征数据的索引技术对于快速检索至关重要。常用的索引方法包括KD树、球树(Ball Tree)以及哈希技术。
索引技术不仅可以加速相似特征的查找过程,还可以通过近似最近邻搜索(ANN)来进一步提高检索效率。例如,KD树是一种二叉树结构,可以快速缩小搜索范围,而球树则是对KD树的一种扩展,它在多维数据空间中更为有效。
实际操作示例
实施特征数据压缩
假设我们已经通过LBPH方法提取了一组人脸特征,现在我们将展示如何使用Python实现特征数据的压缩。我们将利用PCA降维技术来减少特征的维数。
from sklearn.decomposition import PCA
import numpy as np
# 假设face_features是一个包含多张人脸特征的数据集,每一行代表一个样本的特征向量
n_components = 100 # 我们将特征降维到100维
pca = PCA(n_components=n_components)
compressed_face_features = pca.fit_transform(face_features)
# compressed_face_features 就是压缩后的特征数据
实施KD树索引
接下来,我们将通过KD树来为压缩后的特征数据建立索引,以便快速检索。
from scipy.spatial import KDTree
# 使用压缩后的特征数据构建KD树
tree = KDTree(compressed_face_features)
# 假设我们要查找最近邻的特征向量
query = compressed_face_features[0] # 查询向量
distances, indices = tree.query([query], k=5) # 查找最近的5个邻居
# indices[0] 包含最近邻的索引,distances[0] 包含对应的欧几里得距离
通过以上步骤,我们可以高效地管理特征数据,完成对人脸库的维护和优化工作。
7. 人脸识别与特征匹配
人脸识别技术是一项通过计算机技术,识别和验证人脸的技术。它广泛应用于安全验证、身份认证、智能监控等领域。人脸识别的过程包括图像采集、图像预处理、特征提取、特征匹配等环节。
7.1 人脸识别技术的原理
7.1.1 人脸识别流程的概述
人脸识别通常包括以下几个步骤:
- 图像采集:使用摄像头等设备获取人脸图像。
- 图像预处理:对采集的图像进行灰度化、直方图均衡化等处理,以便于后续的特征提取。
- 特征提取:从预处理后的图像中提取人脸特征,如眼睛、鼻子、嘴巴等的位置,以及这些特征的形状和相对位置等信息。
- 特征匹配:将提取的特征与已知的人脸特征进行比较,以实现人脸的识别。
7.1.2 特征匹配算法的原理与实现
特征匹配是人脸识别的关键步骤,它决定了识别的准确性。特征匹配算法主要包括以下几种:
- 欧氏距离:计算两个特征点之间的欧氏距离,距离越小,匹配度越高。
- 余弦相似度:计算两个特征向量的夹角的余弦值,余弦值越大,匹配度越高。
- Hausdorff距离:计算两个点集之间的Hausdorff距离,距离越小,匹配度越高。
以下是使用Python实现欧氏距离特征匹配的一个简单示例:
import numpy as np
# 定义欧氏距离函数
def euclidean_distance(a, b):
return np.sqrt(np.sum((a - b) ** 2))
# 假设我们有两个特征点
feature1 = np.array([1, 2, 3])
feature2 = np.array([1.1, 2.1, 3])
# 计算两个特征点之间的欧氏距离
distance = euclidean_distance(feature1, feature2)
print(f'Euclidean Distance: {distance}')
在实际应用中,我们需要处理的是特征向量而非单个特征点,因此需要对距离计算公式进行适当扩展。
7.2 实际应用中的挑战与解决方案
7.2.1 环境变化对识别的影响
实际应用中,环境的变化如光照、表情、遮挡等,都会对人脸识别产生影响。为了提高识别的准确性,我们通常需要对特征提取和匹配算法进行优化。
- 光照变化:可以使用图像预处理技术如直方图均衡化、局部二值化等,来减少光照变化对特征提取的影响。
- 表情变化:可以通过提取具有鲁棒性的特征,如Gabor特征、深度学习提取的特征等,来减少表情变化的影响。
- 遮挡问题:可以使用部分人脸识别技术,或者使用深度学习进行人脸部件的识别和匹配。
7.2.2 实时处理与识别速度优化
人脸识别系统通常需要在实时处理的情况下保证识别的准确性,这对算法的效率提出了很高的要求。为了提高识别速度,我们可以采取以下策略:
- 算法优化:使用高效的数据结构和算法,比如使用k-d树或者近邻搜索算法提高特征匹配的速度。
- 硬件加速:使用GPU或其他专用硬件进行并行计算,以提高处理速度。
- 模型压缩:通过模型剪枝、量化等技术减少模型大小,降低计算量。
通过以上优化,人脸识别系统可以在保证识别准确性的同时,实现快速实时处理。
简介:OpenCV是一个包含图像处理和计算机视觉算法的跨平台库,特别在Java环境中的应用非常强大。本文将探讨如何利用OpenCV进行人脸检测、图像抠图、人脸库训练和人脸识别,详细介绍Haar级联分类器、图像裁剪和复制、机器学习算法以及多线程和GPU加速等技术。这些技术是构建人脸识别系统的关键,并在多个实际应用领域中得到应用。

















 849
849

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









