







 本文介绍了强化学习的基本概念,包括Agent与环境的交互框架、奖励机制、策略生成等核心内容。探讨了不同类型的奖励如何影响Agent的学习过程,并介绍了ε-Greddy及Softmax等策略选择方法。
本文介绍了强化学习的基本概念,包括Agent与环境的交互框架、奖励机制、策略生成等核心内容。探讨了不同类型的奖励如何影响Agent的学习过程,并介绍了ε-Greddy及Softmax等策略选择方法。
本文章收录在黑鲸智能系统知识库-黑鲸智能系统知识库成立于2021年,致力于建立一个完整的智能系统知识库体系。我们的工作:收集和整理世界范围内的学习资源,系统地建立一个内容全面、结构合理的知识库。
作者博客:途中的树
强化学习算法的思路非常简单,以游戏为例,如果在游戏中采取某种策略可以取得较高的得分,那么就进一步「强化」这种策略,以期继续取得较好的结果。这种策略与日常生活中的各种「绩效奖励」非常类似。我们平时也常常用这样的策略来提高自己的游戏水平。——AI百科
强化学习(RL)是机器学习的一个领域,涉及软件代理如何在环境中采取行动以最大化一些累积奖励的概念。该问题由于其一般性,在许多其他学科中得到研究,如博弈论,控制理论,运筹学,信息论,基于仿真的优化,多智能体系统,群智能,统计和遗传算法。。在运筹学和控制文献中,强化学习被称为近似动态规划或神经动态规划。——wiki
强化学习的结构
- 强化学习使用输出 Y ( X i , s α ) Y(X_i,s_\alpha) Y(Xi,sα)产生的效果对接下来的系统(如 机器人系统)产生的影响,计算系统 S S S内部参数的变化,目的是使奖励 r r r 最大化。下面是强化学习算法的基本框架
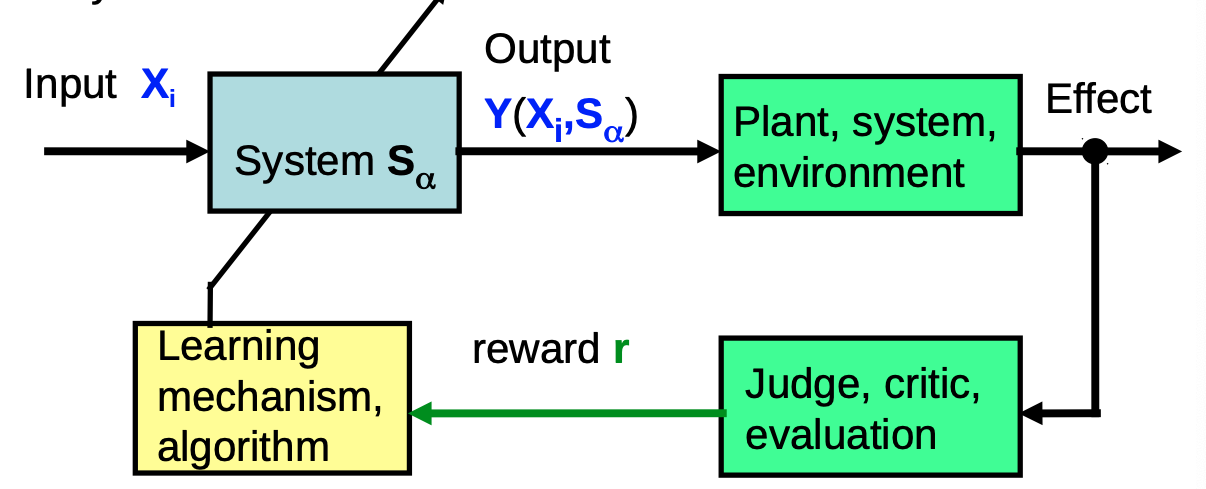
- 简化一下这个结构我们可以得到下图,其中系统 S α S_\alpha Sα 和学习机制组成了 Agent,评估系统和系统的外部环境组成了环境
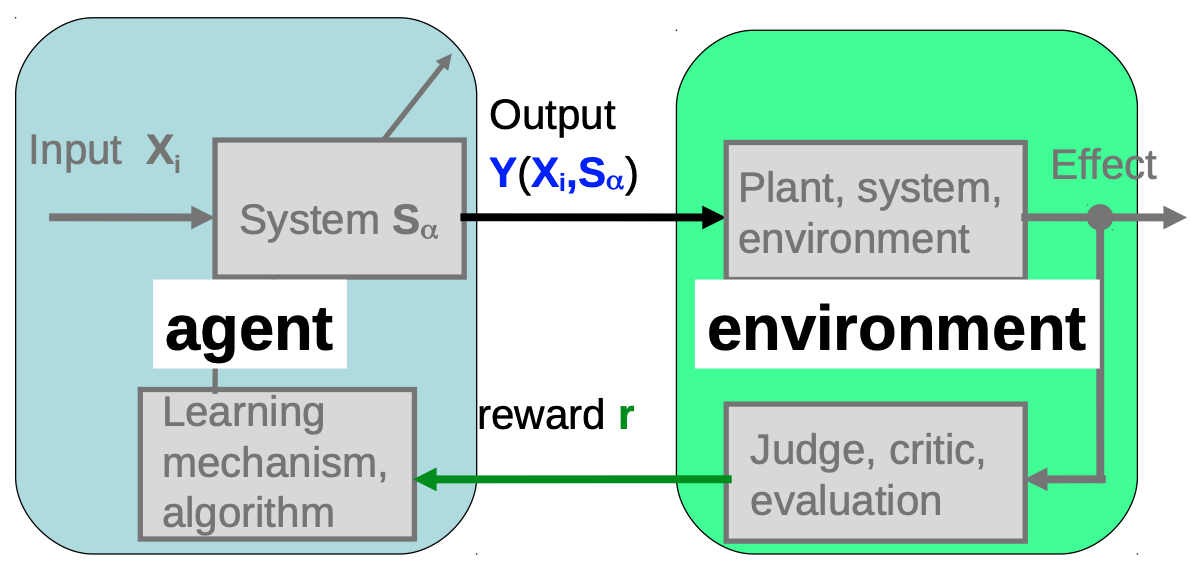
Agent - Environment 框架
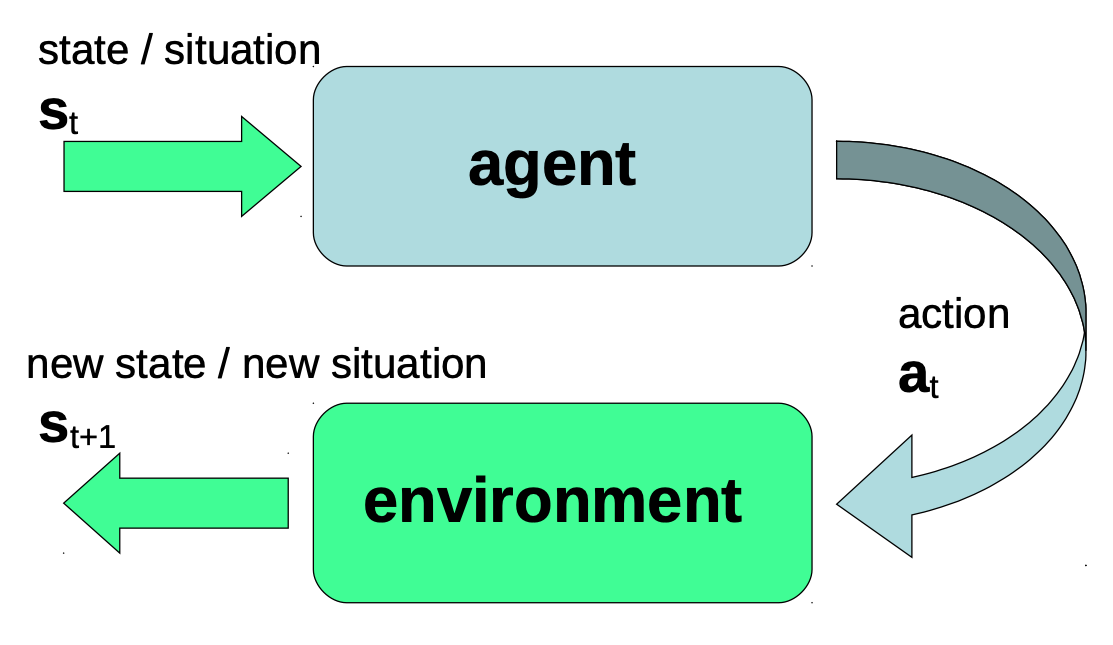
- 由此得到一个Agent - Environment 框架
- Agent: 在时间t 观测到状态(或情况) s s s, 并产生一个内部的行动 a t a_t at
- 参数: 一个内部(世界)模型和一个内部行为策略 π \pi π
- 环境所处的状态或情况 s t s_t st ( s s s 不一定是物理学、数学或工程学中严格的正式定义中的状态空间的表示。一个情况可以是真实状态的一个近似值。)
- 行动 a t a_t at: 从允许的、可能的行动的集合中选取的行动,这个集合通常取决于 s t s_t st
- 处于状态 s t s_t st的环境: 收到来自Agent的行动 a t a_t at,并产生新的状态/情况 s t + 1 s_{t+1} st+1反馈
- 奖励
- 环境从时间t到t+1的过渡变化中,为Agent产生一个反馈(奖励或惩罚)
- 该反馈是环境对行动、状态和一个未知的、取决于内部环境的奖励系统产生的奖励
- r t + 1 r_{t+1} rt+1是在从时间段 t t t过渡到 t + 1 t+1 t+1后产生的奖励信号
- 新的状态 S t + 1 S_{t+1} St+1和奖励都是以离散的时间为基础产生的。
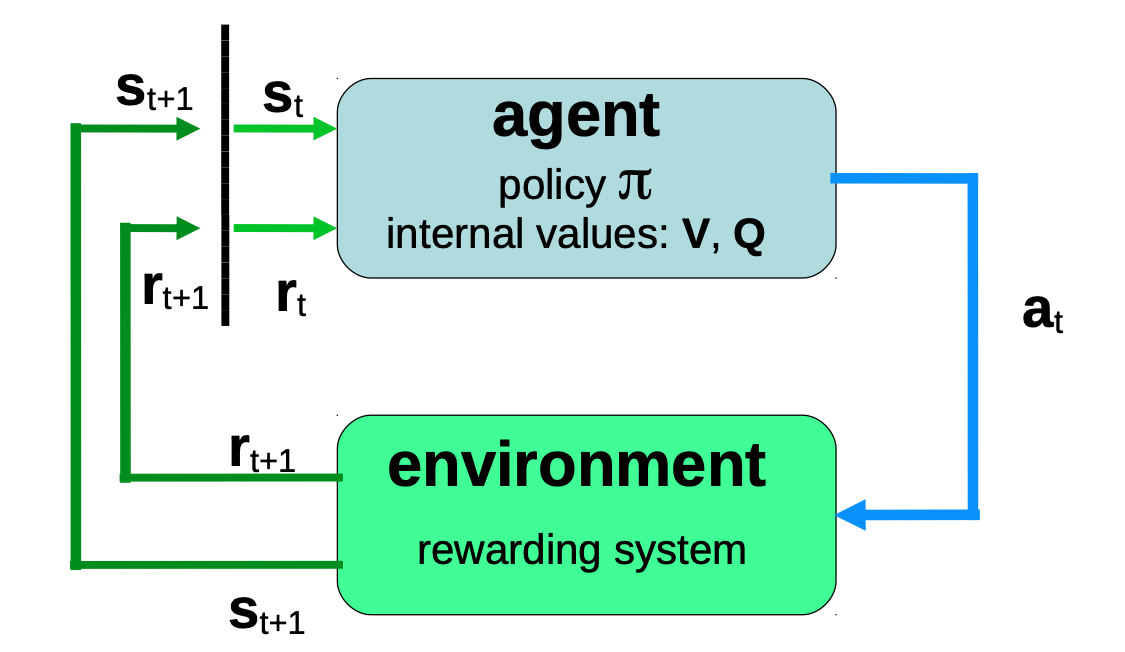
强化学习系统的组成
- Agent
- 包含一个策略 π \pi π 和一组内部变量。
- 环境
- 接收行动 a a a,产生状态 s s s和奖励 r r r,包含一个奖励系统,可能是随机的
- 状态空间/情况空间 S S S
- 多维空间, s t , s t + 1 s_t,s_{t+1} st,st+1<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1087
1087

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









