






 本文深入介绍了MySQL的全局事务标识符(GTID)和慢查询日志。GTID模式简化了主从复制和数据恢复,提供幂等性,并允许快速定位事务。在开启GTID后,每个独立的DDL、DCL事件和DML事务都有唯一的GTID号。慢日志则记录执行时间超过设定阈值的查询,有助于优化数据库性能。通过设置配置,可以启用GTID,监控并分析慢查询,进一步提升数据库效率。
本文深入介绍了MySQL的全局事务标识符(GTID)和慢查询日志。GTID模式简化了主从复制和数据恢复,提供幂等性,并允许快速定位事务。在开启GTID后,每个独立的DDL、DCL事件和DML事务都有唯一的GTID号。慢日志则记录执行时间超过设定阈值的查询,有助于优化数据库性能。通过设置配置,可以启用GTID,监控并分析慢查询,进一步提升数据库效率。
大家好,我是anyux。本文介绍MySQL的GTID和慢日志。

binlog的gtid记录模式管理
GTID简介
从5.7开始,建议将二进制日志模式改为GTID模式。GTID模式不仅用在主从复制中,在单机模式中也有。一旦开启了GTID,它的管理方式就发生了改变。
没有GTID时,二进制日志按事件来规划事务。要找到完整的事务,就需要找到Pos开始值,找到 End_log_pos结束值,然后导出到sql文件,再恢复数据。
开启GTID后,对于每一个独立的"事务",都会生一个GTID号码
需要注意的是,此处的"事务"与innodb的事务有些区别:
对于DDL、DCL,一个event就是一个事务,就会有一个GTID号
对于DML,就是从begin到commit就是一个事务,也会有一个GTID号

查看GTID文件
server-uuid=xxx:TID
GTID文件默认存储到数据目录下的auto.cnf文件中
重启服务后,会自动生成新的文件。但是不要随意删除、修改此文件
cd /data/mysql/data
cat auto.cnf

TID是一个自动增长的数字,从1开始增长
GTID的幂等性
如果使用开户GTID的日志去恢复数据,会查看当前系统是否有GTIDk号,有相同的会自动跳过,幂等性会影响二进制日志的对数据的恢复和主从复制
GTID开启和配置
在配置文件加入两条配置,配置修改后,重启数据库。
vim /etc/my.cnf
开启gtid模式
gtid-mode=on
强制gtid一致性
enforce-gtid-consistency=true
注意,GTID开启后,只对开启后的事务做记录,之前的事务,没有记录.

查看GTID信息
创建数据库并查看开启GTID后,二进制日志的记录信息
show master status;create database gtid charset utf8mb4;show master status;
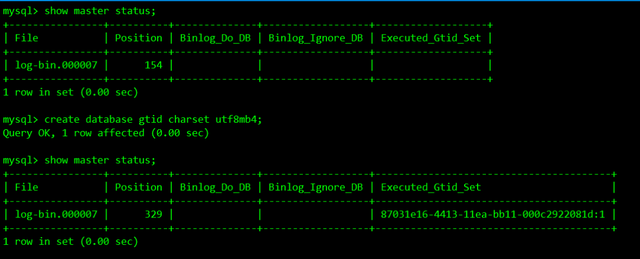
通过上图可以看出,Executed_Gtid_Set列出现了新的记录值,这表明GTID记录已被写入到二进制日志中
use gitd;
创建数据表
create table gtid_01(id int);
查看GITD信息
show master status;
插入数据
insert into gtid_01(1);
查看GITD信息
show master status;
提交事务
commit;
查看GITD信息
show master status;
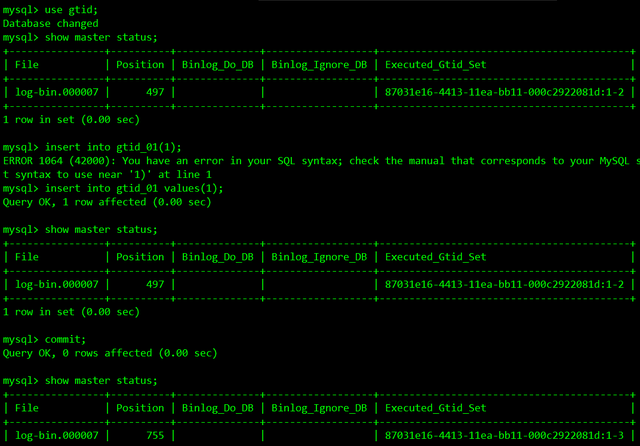
上图看到,对于建表建库语句,每次执行都会有一个GTID号被创建,对于DML语句,只有在commit提交事务后,才会创建新的事务号
查看二进制日志详细信息
show binlog events in 'log-bin.000007';
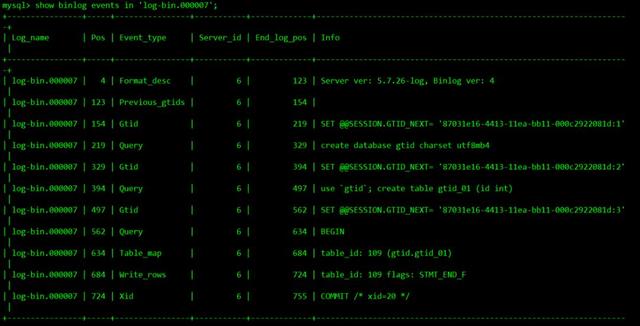
在上图的Info列中,可以看到如下内容
SET @@SESSION.GTID_NEXT= '87031e16-4413-11ea-bb11-000c2922081d:1'结尾的":1"就是GTID号,有了这个号,就可以很快实现数据恢复。能发现这里的1到3号,就对应的上面的建库、建表、插入操作
删除数据库
drop database gtid;基于GTID的数据恢复
导出二进制日志到sql文件
参数include-gtids,表明已经开启gtid模式参数skip-gtids,在导出时,忽略原有的gtid信息,恢复时生成最新的gtid信息参数exclude-gtids 排序指定的gtid对于不连续的gtid,排除多个gtid方式为
--exclude-gtids='87031e16-4413-11ea-bb11-000c2922081d:1','87031e16-4413-11ea-bb11-000c2922081d:3',
cd /data/mysqlmysqlbinlog --skip-gtids --include-gtids='87031e16-4413-11ea-bb11-000c2922081d:1-3' log-bin.000007 >/tmp/gtid.sql
设置临时会话状态
注意,恢复数据,暂停数据库记录二进制日志。原因是,恢复数据的过程不需要再次被记录
set sql_log_bin=0;
恢复数据
source /tmp/gtid.sql;
设置临时会话状态
set sql_log_bin=1;
查看数据
use gtid;select * from gtid_01;
慢日志(slow-log)
记录运行较慢的日志,优化过程中常用的工具日志
修改日志文件后,需要重启数据库服务
vim /etc/my.cnf
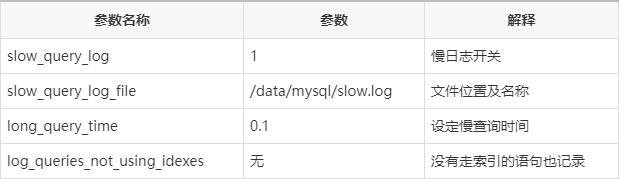
慢日志开关
slow_query_log=1
慢日志存储位置
slow_query_log_file=/data/mysql/slow.log
慢查询阀值
long_query_time=0.1
记录未走索引的日志
log_queries_not_using_indexes
查询慢语句阀值
select @@long_query_time;
模拟慢查询
use test;select num,k1 from t100w where num !=0 order by k1 limit 10;select num,k1 from t100w where num !=10 order by k1 limit 100;select num,k1 from t100w where num >1000 order by k1 limit 100;select num,k1 from t100w where num >10000 order by k1 limit 10000;select num,k1 from t100w where num !=1000 order by k1 limit 100;select num,k1 from t100w where num !=10 order by k1 limit 10000;select * from t100w where num !=10 order by k1 limit 100,300;select * from t100w where num !=0 order by k1 limit 100,3000;select * from t100w where num >1 order by k1 limit 10000,30000;select * from t100w where k1="s" order by k1 limit 10000,30000;select * from t100w where k1="s" order by k1 limit 1000,3000;select num,k1 from t100w where k1="s" order by k1 limit 1000,3000;select num,k1 from t100w where k1="s" order by k1 limit 10000,30000;select num,k1 from t100w where k1="0" order by k1 limit 10000,30000;select num,k1 from t100w where k1 like "%1%" order by k1 limit 10000,30000;select num,k1 from t100w where k1 like "%2%" order by k1 limit 10000,30000;
查看慢日志
慢日志是一个文件文件,可以使用vim等工具打开
cd /data/mysqlvim slow.log
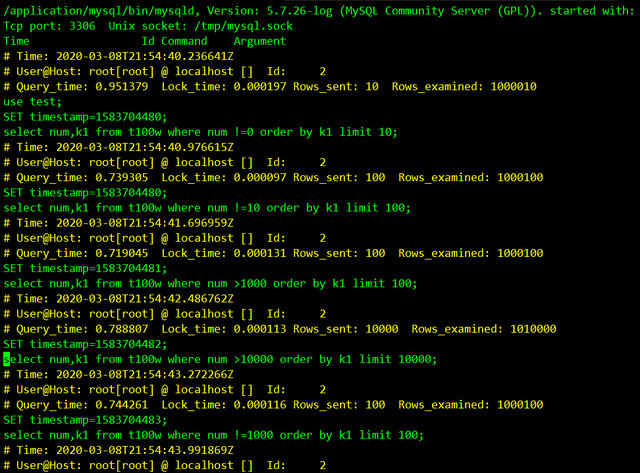
上图为slow.log慢日志的内容,上面显示的sql语句都是运行时间超阀值或是没走索引语句
Query_time表示查询消耗时间,单位是秒。这些sql语句是按sql执行的时间顺序来记录的,没有一对于消耗时间排序。需要使用到工具,辅助查看
分析慢日志
mysqldumpslow是mysql自带的慢日志处理工具,其中s参数表示排序,c表示次数,t 10表示前10位
mysqldumpslow -s c -t 10 /data/mysql/slow.log
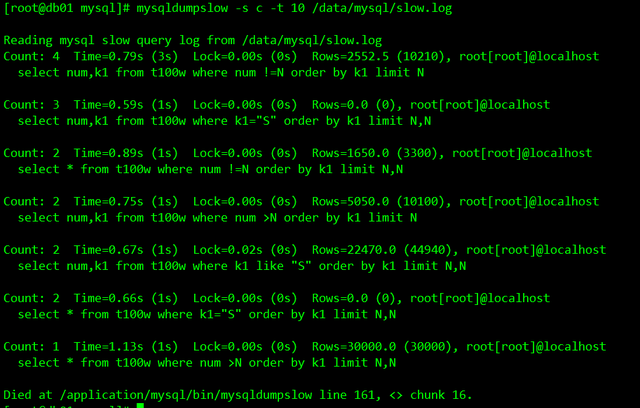
上图将sql语句排序输出
找到上面语句耗时最多的进行分析,比如下面的语句
select num,k1 from t100w where num !=N order by k1 limit N;可以将N替换为相应的数字,进行查看,明显使用!=号是不会走索引的
对于这个语句,通过执行计划分析,查看索引使用情况,在此基础上进行创建索引。或者与开发人员沟通,优化sql语句

欢迎在评论区一起讨论,质疑。文章都是手打原创,每天最浅显的介绍运维、数据库相关的技术,喜欢我的文章就关注一波吧,可以看到最新更新和之前的文章。

















 796
796

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









