






 本文介绍了在Python中处理字节编码时遇到的空字节问题,通过详细阐述踩坑过程和解决方案,包括:1) 强制类型转换失败;2) 使用中间人方法;3) 利用bytearray单字节读取。最终通过增加偏移量和改变循环逻辑成功地去除了空字节,实现了正确解码UTF-8文本。
本文介绍了在Python中处理字节编码时遇到的空字节问题,通过详细阐述踩坑过程和解决方案,包括:1) 强制类型转换失败;2) 使用中间人方法;3) 利用bytearray单字节读取。最终通过增加偏移量和改变循环逻辑成功地去除了空字节,实现了正确解码UTF-8文本。
一个网页中有不同的编码,其实就是网页中穿插着unicode无法映射的编码,使用requests爬虫会直接失败
一、 踩坑路程1
1. 强制类型转换
在requests中可以直接获取到网页源码的二进制数据,其实也就是尚未进行编码的字节,在Python中以十六进制的形式展现,格式就是下面这种
data="你好世界!"
print(data.encode("utf-8"))
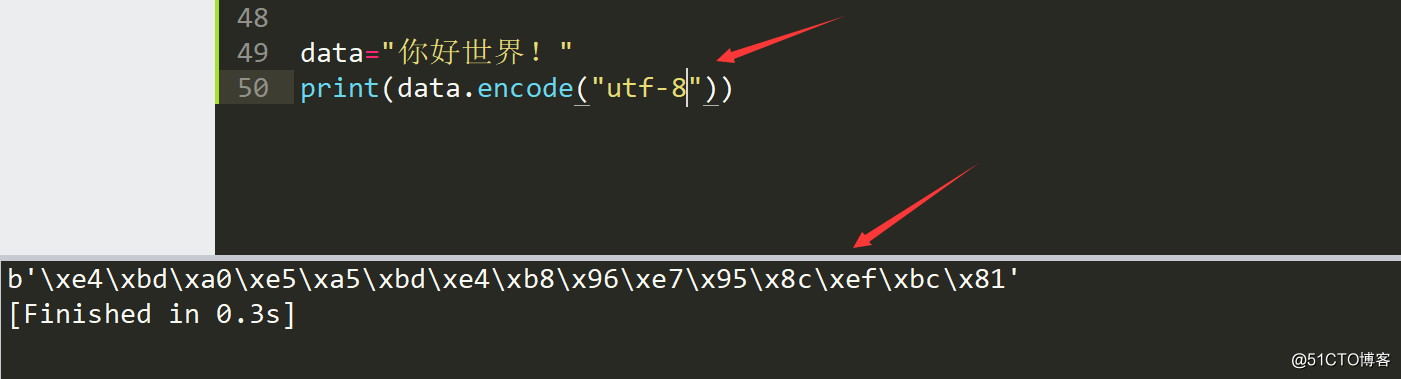
那么我们就有了思路,我们可不可以在它还是字节剔除掉乱码的部分,然后转换成字节,重新编码
data=b"\xe4\xbd\xa0"
# 转换成字符串
data=str(data)
print(data)
# 转换成字节
data=bytes(data,"utf-8")
print("字节形式:",data)
print("解码成UTF-8文本",data.decode("utf-8"))
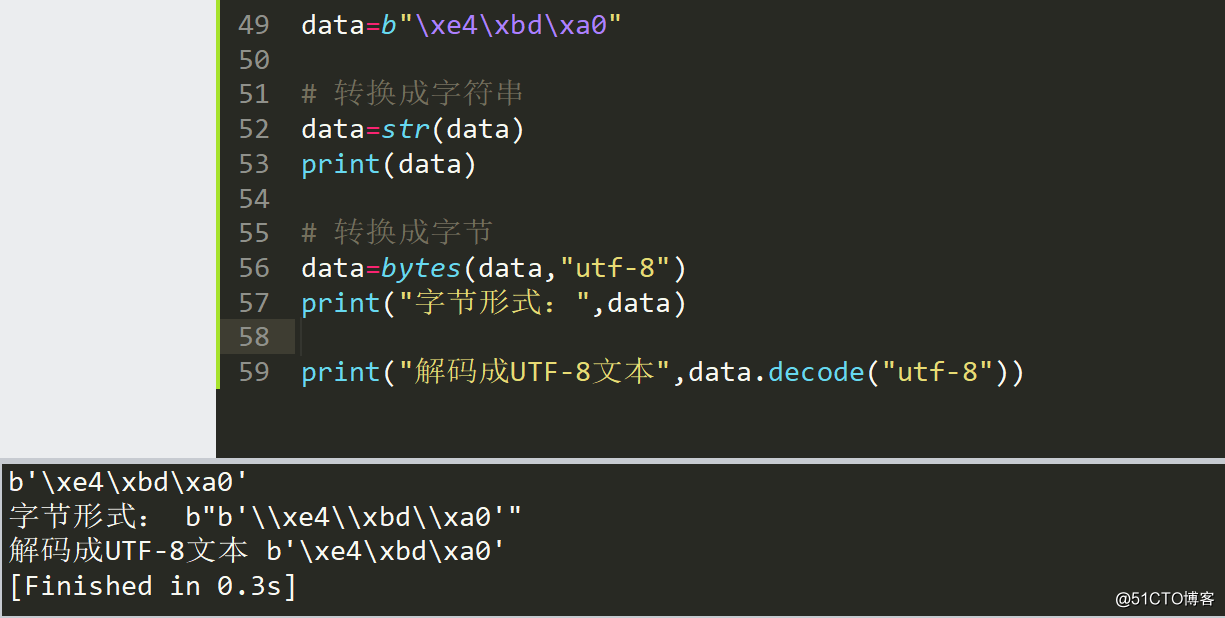
很明显失败了,在把他转换成字节的时候多了\,也就是把\xe4\xbd\xa0的字节转换成字节,也就变成了\\xe4\\xbd\\xa0,这种字节格式是明显无法解码成功的,最终就是解码成了\xe4\xbd\xa0
问题似乎出现在了data=bytes(data,"utf-8")多了utf-8,去掉试试
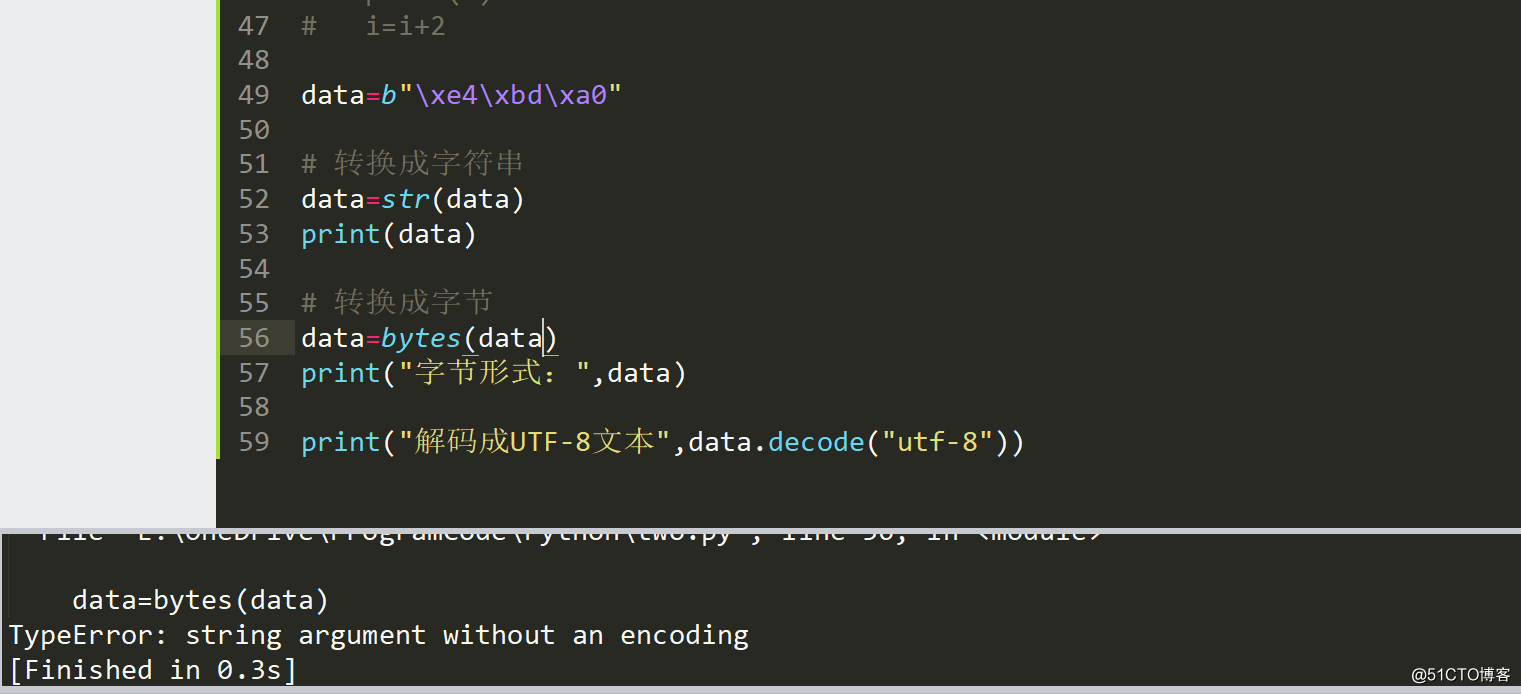
报错了,这个问题类似于c语言的指针,指向指针的指针
如果能直接转换的话,这个问题直接就能解决了,可是并不能
2. 中间人
既然我有了一个字符串类型的字节,虽然它是字符串类型的,但是它的内容是字节啊,所以我们可以建一个文本,以二进制的方式读写不就行了?
这里就不给代码了,和上面的类似,以二进制的方式读写,传入值必须是字节型的也就是bytes,可是我们不是无法转换来着吗?
3. bytearray单字节读取
这个命令可以对字节单个读取修改,我似乎离正确的答案越来越近了
data=b"\xe4\xbd\xa0"
data=bytearray(data)
print(hex(data[0]))
print(hex(data[1]))
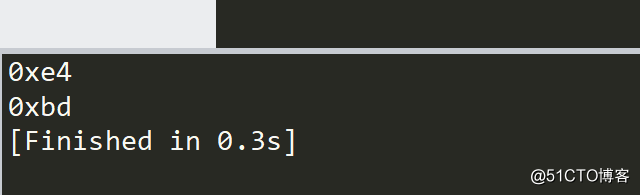
不过别高兴的太早,我封装了一个函数,按照其逻辑来说的话是很完美的,是应该能正确的,可是Python有Python的逻辑
def Binary(text,content):
# text是一个列表
# content是requests获取到的字节
content=bytearray(content)
data=bytearray()
sum=0
k=0
# 开始比对
for i in range(len(content)):
for j in range(len(text)):
# 防止超出范围
if i+j>=len(content):
break;
# 如果第一个相同那就比对后面的几个
if content[i+j]==text[j]:
sum=sum+1
# 如果全部相同,那么他就是相等的,让i往前移动len(text)-1个位置
if sum==len(text):
i=i+len(text)-1
else:
data.append(content[i])
sum=0
return data
为什么会失败?因为Python的for循环 i无法更改,就像是下面
a=10
for i in range(a):
print(i)
i=i+2
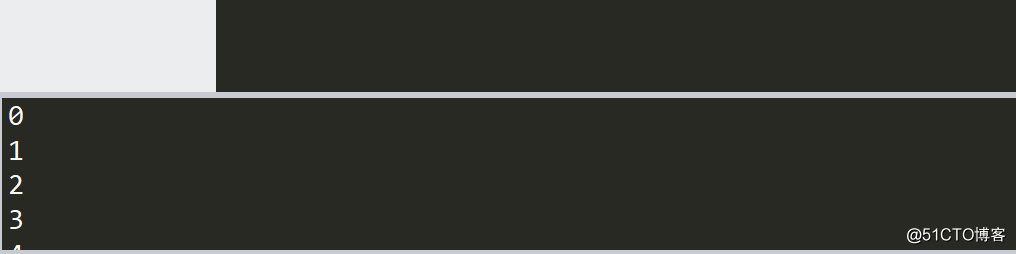
这个明显不符合我们的预期啊,该死的i依然的我行我素,好了既然我们知道错误在什么地方了,下一步就该解决了,离解决方法是越来越近了
二、 终于成功了
1. 增加一个偏移量
def Binary(text,content):
# text是一个列表
# content是requests获取到的字节
content=bytearray(content)
data=bytearray()
sum=0
k=0
# 开始比对,减少次数,避免溢出
for i in range(len(content)-len(text)):
for j in range(len(text)):
# 如果第一个相同那就比对后面的几个
if content[i+j]==text[j]:
sum=sum+1
# 如果全部相同,那么他就是相等的,让i往前移动len(text)-1个位置
if sum==len(text):
k=len(text)-1
else:
data.append(content[i+k])
sum=0
return data
# 获取网页
r=requests.get("https://www.biquge.com.cn/book/7787/192921.html")
# 需要剔除的字节
text=[239,191,189]
# 调用函数
content=Binary(text,r.content)
content=bytes(content)
# 把字节解码成Utf-8的文本
print(content.decode("utf-8"))

2. 让其轮空
在我们需要的时候不让data添加字节
def Binary(text,content):
# text是一个列表
# content是requests获取到的字节
content=bytearray(content)
data=bytearray()
sum=0
k=0
# 开始比对
for i in range(len(content)):
if k<=0:
for j in range(len(text)):
# 防止索引超出范围
if i+j>=len(content):
break
# 如果第一个相同那就比对后面的几个
if content[i+j]==text[j]:
sum=sum+1
# 如果全部相同,赋值给k
if sum==len(text):
k=sum
sum=0
# 利用k让for轮空
if k>0:
k=k-1
continue
data.append(content[i])
sum=0
return data
# 获取网页
r=requests.get("https://www.biquge.com.cn/book/7787/192921.html")
text=[239,191,189]
content=Binary(text,r.content)
content=bytes(content)
# 把字节解码成Utf-8的文本
print(content.decode("utf-8"))

3. 更为简练的写法
原来可以直接像是列表一样删除其索引,data.remove不能用,不知道为什么
def Binary(text,content):
# text是一个列表
# content是requests获取到的字节
content=bytearray(content)
data=bytearray()
sum=0
k=[]
# 开始比对
for i in range(len(content)-len(text)):
for j in range(len(text)):
if content[i+j]==text[j]:
sum=sum+1
if sum==len(text):
for j in range(len(text)):
k.append(i+j)
sum=0
for i in range(len(k)):
del content[k[0]]
return content
r=requests.get("https://www.biquge.com.cn/book/7787/192921.html")
text=[239,191,189]
content=Binary(text,r.content)
print(content.decode("utf-8"))

三、 总结
建议使用三种写法,更解决,前面可以加一个判断,使其del content[0]不会出现问题
def Binary(text,content):
# text是一个列表
# content是requests获取到的字节
content=bytearray(content)
data=bytearray()
sum=0
k=[]
# 开始比对
for i in range(len(content)-len(text)):
for j in range(len(text)):
if content[i+j]==text[j]:
sum=sum+1
if sum==len(text):
for j in range(len(text)):
k.append(i+j)
sum=0
# 如果不等那就代表着没有找到,返回原来的字节值就行
if len(k)!=len(text):
return content
for i in range(len(k)):
# content.pop(k[0])
del content[k[0]]
return content
r=requests.get("https://www.baidu.com")
text=[239,191,189]
content=Binary(text,r.content)
print(content.decode("utf-8"))

花了好长的时间,终于解决好了,可谓是一顿操作猛如虎,最后只解决一个字符问题,大写的尴尬
有能力的大佬可以多收集一些“锟斤拷”形成一个库,这样在用requests爬取网页时再也不怕网页出现不该出现的编码了
最后提供一个练习素材:里面含有一个“锟斤拷”
地址:蓝奏云下载地址

















 313
313

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









