




 本文介绍了Python数据分析库pandas中的Series数据结构,包括如何生成Series、使用索引、进行NumPy运算以及处理缺失数据。Series作为定长的有序字典,允许通过索引选择和操作数据,还能自动对齐不同索引的数据,在数据分析中发挥重要作用。
本文介绍了Python数据分析库pandas中的Series数据结构,包括如何生成Series、使用索引、进行NumPy运算以及处理缺失数据。Series作为定长的有序字典,允许通过索引选择和操作数据,还能自动对齐不同索引的数据,在数据分析中发挥重要作用。
预告:后边一段时间,我会分享一系列关于Python数据分析的内容,为大家展示一个数据分析师需要掌握什么知识,具备什么样的技能,感兴趣的可以先关注下。
要使用强大的Python数据分析模块pandas,我们首先要熟悉它的两个主要的数据结构:Series(序列)和DataFrame(数据框),或许它们无法解决所有的问题,但它们为大多数应用提供了一种可靠的、易于使用的基础。
1.生成Series(序列)
Series是一种类似于一维数组的对象,它由一组数据以及一组与之相关的数据标签组成。
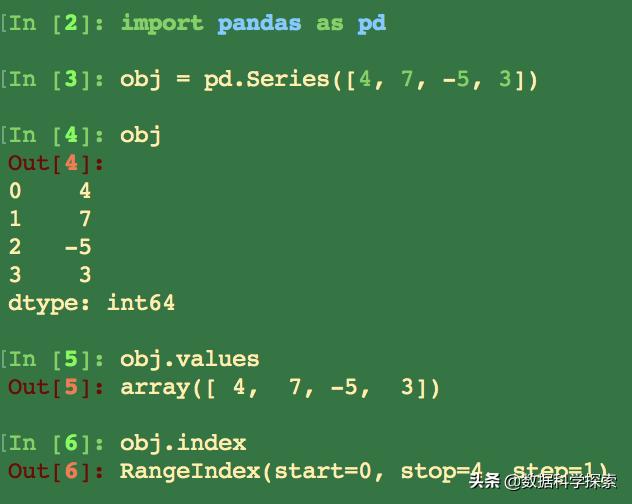
仅由一组数据即可产生最简单的Series,其字符串表现形式为:索引在左边,值在右边。
如果我们没有为数据指定索引,那么它会自动创建一个0到N-1(N为数据的长度)的整数型索引。
我们可以通过Series的values和index属性获取其数组表示形式和索引对象:
2.通常,我们希望所创建的Series带有以各可以对各个数据点进行标记的索引:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1265
1265

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









