






Spark执行模型可以分为三部分:创建逻辑计划,将其翻译为物理计划,在集群上执行task。
可以在http://<driver-node>:4040上查看关于Spark Jobs的信息。对于已经完成的Spark应用,可以在http://<server-url>:18080上查看信息。
下面来浏览一下这三个阶段。 逻辑执行计划
第一阶段,逻辑执行计划被创建。这个计划展示了哪些steps被执行。回顾一下,当对一个Dataset执行一个转换操作,会有一个新的Dataset被创建。这时,新的Dataset会指向其父Dataset,最终形成一个有向无环图(DAG)。 物理执行计划
行动操作会触发逻辑DAG图向物理执行计划的转换。Spark Catalyst query optimizer会为DataFrames创建物理执行计划,如下图所示:
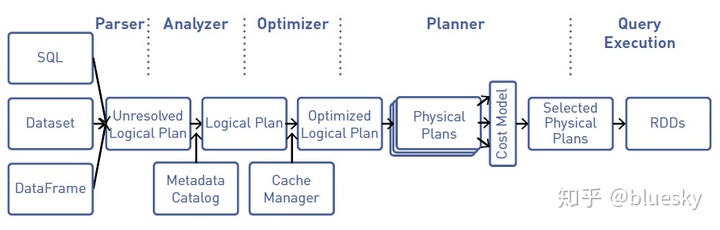
物理执行计划标识执行计划的资源,例如内存分区和计算任务。
查看逻辑执行计划和物理执行计划
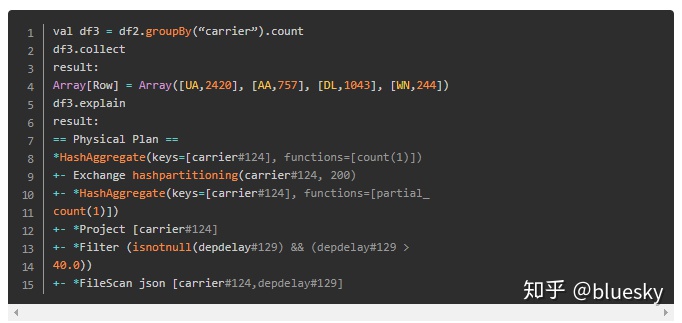
可以调用explain(true)方法查看逻辑和物理执行计划。如下例所示:
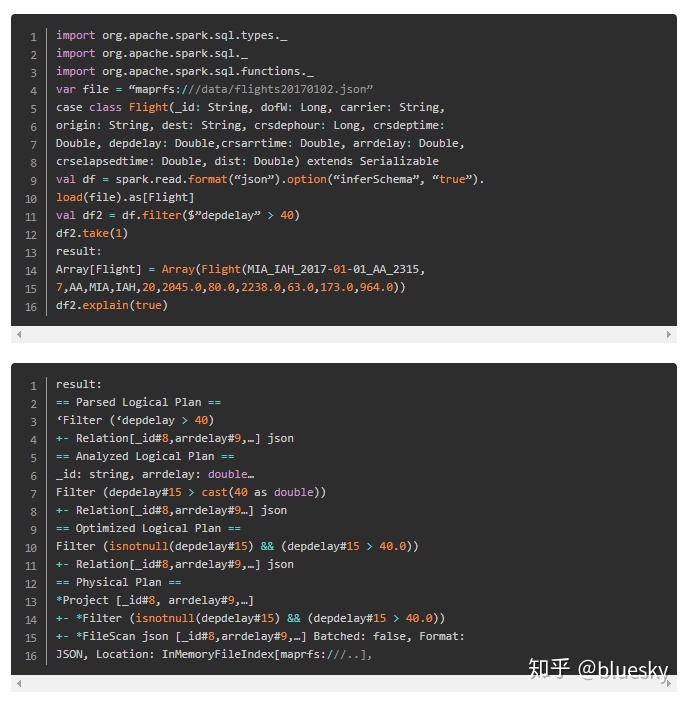
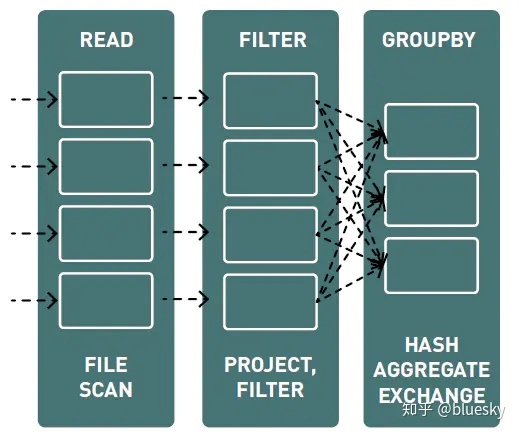
物理计划由FileScan、Filter、Project、HashAggregate、Exchange以及HashAggregate组成。Exchange是由groupBy转换导致的shuffle。Spark在每次shuffle之前对Exchange的数据进行hash aggregation。在shuffle后会针对之前的子aggragation进行一次hash aggregation。
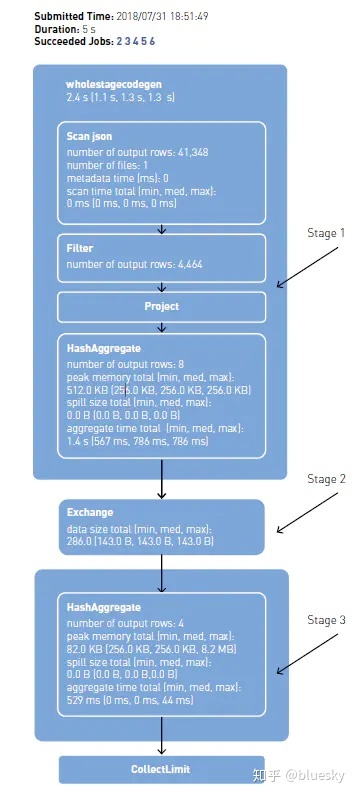
在集群上执行tasks
第三阶段,tasks在集群上被调度执行。scheduler将根据转换操作将DAG图划分为stage。窄依赖转换操作(没有数据移动的转换)将被分组到一个单一的stage中。
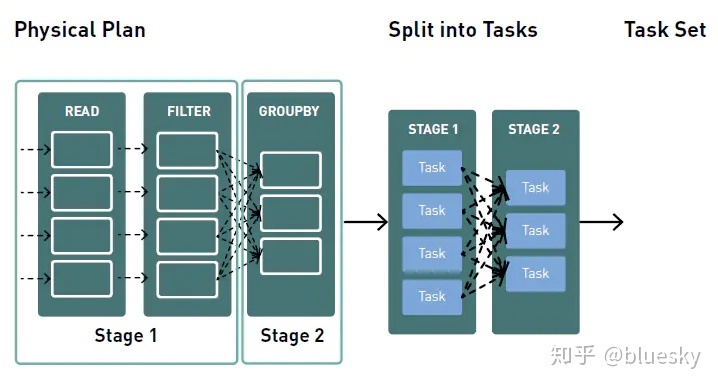
以下是关于执行组成的一些总结:
- Task:单台机器上运行的执行单元。
- Stage:基于partitions的一组task,执行并行计算。
- Job:具有一个或多个stages。
- Pipelining:当数据集转换操作时没有数据移动时,将Datasets折叠为单一stage。
- DAG:数据集操作时的逻辑视图。
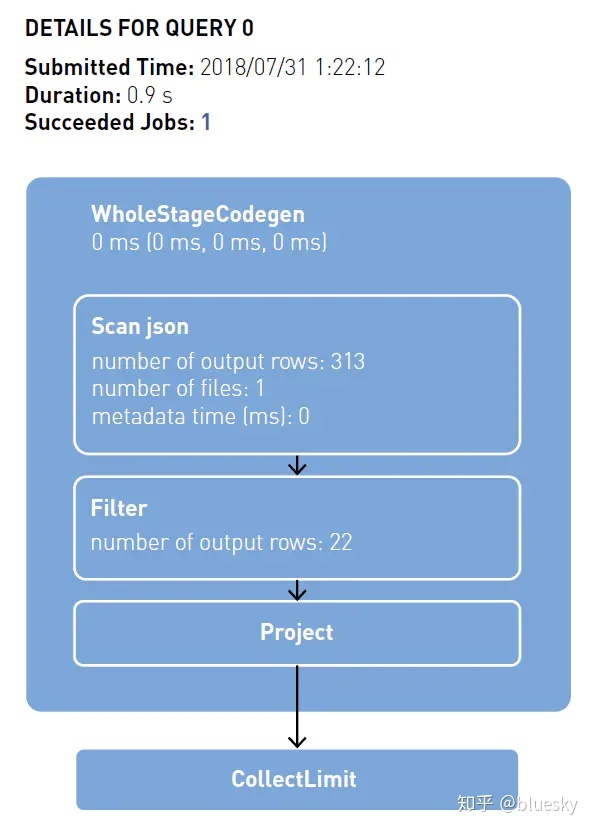
Tasks的数量取决于partitions:在第一个阶段读取文件时,有2个partitions;shuffle过后,partitions的数量为200.可以通过rdd.partitions.size方法查看Dataset的partition数量。
转自:
1.整体运行流程
使用下列代码对SparkSQL流程进行分析,让大家明白LogicalPlan的几种状态,理解SparkSQL整体执行流程
// sc is an existing SparkContext.
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
// this is used to implicitly convert an RDD to a DataFrame.
import sqlContext.implicits._
// Define the schema using a case class.
// Note: Case classes in Scala 2.10 can support only up to 22 fields. To work around this limit,
// you can use custom classes that implement the Product interface.
case class Person(name: String, age: Int)
// Create an RDD of Person objects and register it as a table.
val people = sc.textFile("/examples/src/main/resources/people.txt").map(_.split(",")).map(p => Person(p(0), p(1).trim.toInt)).toDF()
people.registerTempTable("people")
// SQL statements can be run by using the sql methods provided by sqlContext.
val teenagers = sqlContext.sql("SELECT name, age FROM people WHERE age >= 13 AND age <= 19")(1)查看teenagers的Schema信息
scala> teenagers.printSchema
root
|-- name: string (nullable = true)
|-- age: integer (nullable = false)(2)查看运行流程
scala> teenagers.queryExecution
res3: org.apache.spark.sql.SQLContext#QueryExecution =
== Parsed Logical Plan ==
'Project [unresolvedalias('name),unresolvedalias('age)]
'Filter (('age >= 13) && ('age <= 19))
'UnresolvedRelation [people], None
== Analyzed Logical Plan ==
name: string, age: int
Project [name#0,age#1]
Filter ((age#1 >= 13) && (age#1 <= 19))
Subquery people
LogicalRDD [name#0,age#1], MapPartitionsRDD[4] at rddToDataFrameHolder at <console>:22
== Optimized Logical Plan ==
Filter ((age#1 >= 13) && (age#1 <= 19))
LogicalRDD [name#0,age#1], MapPartitionsRDD[4] at rddToDataFrameHolder at <console>:22
== Physical Plan ==
Filter ((age#1 >= 13) && (age#1 <= 19))
Scan PhysicalRDD[name#0,age#1]
Code Generation: trueQueryExecution中表示的是整体Spark SQL运行流程,从上面的输出结果可以看到,一个SQL语句要执行需要经过下列步骤:
== (1)Parsed Logical Plan ==
'Project [unresolvedalias('name),unresolvedalias('age)]
'Filter (('age >= 13) && ('age <= 19))
'UnresolvedRelation [people], None
== (2)Analyzed Logical Plan ==
name: string, age: int
Project [name#0,age#1]
Filter ((age#1 >= 13) && (age#1 <= 19))
Subquery people
LogicalRDD [name#0,age#1], MapPartitionsRDD[4] at rddToDataFrameHolder at <console>:22
== (3)Optimized Logical Plan ==
Filter ((age#1 >= 13) && (age#1 <= 19))
LogicalRDD [name#0,age#1], MapPartitionsRDD[4] at rddToDataFrameHolder at <console>:22
== (4)Physical Plan ==
Filter ((age#1 >= 13) && (age#1 <= 19))
Scan PhysicalRDD[name#0,age#1]
//启动动态字节码生成技术(bytecode generation,CG),提升查询效率
Code Generation: true2.全表查询运行流程
执行语句:
val all= sqlContext.sql("SELECT * FROM people")运行流程:
scala> all.queryExecution
res9: org.apache.spark.sql.SQLContext#QueryExecution =
//注意*号被解析为unresolvedalias(*)
== Parsed Logical Plan ==
'Project [unresolvedalias(*)]
'UnresolvedRelation [people], None
== Analyzed Logical Plan ==
//unresolvedalias(*)被analyzed为Schema中所有的字段
//UnresolvedRelation [people]被analyzed为Subquery people
name: string, age: int
Project [name#0,age#1]
Subquery people
LogicalRDD [name#0,age#1], MapPartitionsRDD[4] at rddToDataFrameHolder at <console>:22
== Optimized Logical Plan ==
LogicalRDD [name#0,age#1], MapPartitionsRDD[4] at rddToDataFrameHolder at <console>:22
== Physical Plan ==
Scan PhysicalRDD[name#0,age#1]
Code Generation: true3. filter查询运行流程
执行语句:
scala> val filterQuery= sqlContext.sql("SELECT * FROM people WHERE age >= 13 AND age <= 19")
filterQuery: org.apache.spark.sql.DataFrame = [name: string, age: int]执行流程:
scala> filterQuery.queryExecution
res0: org.apache.spark.sql.SQLContext#QueryExecution =
== Parsed Logical Plan ==
'Project [unresolvedalias(*)]
'Filter (('age >= 13) && ('age <= 19))
'UnresolvedRelation [people], None
== Analyzed Logical Plan ==
name: string, age: int
Project [name#0,age#1]
//多出了Filter,后同
Filter ((age#1 >= 13) && (age#1 <= 19))
Subquery people
LogicalRDD [name#0,age#1], MapPartitionsRDD[4] at rddToDataFrameHolder at <console>:20
== Optimized Logical Plan ==
Filter ((age#1 >= 13) && (age#1 <= 19))
LogicalRDD [name#0,age#1], MapPartitionsRDD[4] at rddToDataFrameHolder at <console>:20
== Physical Plan ==
Filter ((age#1 >= 13) && (age#1 <= 19))
Scan PhysicalRDD[name#0,age#1]
Code Generation: true4. join查询运行流程
执行语句:
val joinQuery= sqlContext.sql("SELECT * FROM people a, people b where a.age=b.age")查看整体执行流程
scala> joinQuery.queryExecution
res0: org.apache.spark.sql.SQLContext#QueryExecution =
//注意Filter
//Join Inner
== Parsed Logical Plan ==
'Project [unresolvedalias(*)]
'Filter ('a.age = 'b.age)
'Join Inner, None
'UnresolvedRelation [people], Some(a)
'UnresolvedRelation [people], Some(b)
== Analyzed Logical Plan ==
name: string, age: int, name: string, age: int
Project [name#0,age#1,name#2,age#3]
Filter (age#1 = age#3)
Join Inner, None
Subquery a
Subquery people
LogicalRDD [name#0,age#1], MapPartitionsRDD[4] at rddToDataFrameHolder at <console>:22
Subquery b
Subquery people
LogicalRDD [name#2,age#3], MapPartitionsRDD[4] at rddToDataFrameHolder at <console>:22
== Optimized Logical Plan ==
Project [name#0,age#1,name#2,age#3]
Join Inner, Some((age#1 = age#3))
LogicalRDD [name#0,age#1], MapPartitionsRDD[4]...
//查看其Physical Plan
scala> joinQuery.queryExecution.sparkPlan
res16: org.apache.spark.sql.execution.SparkPlan =
TungstenProject [name#0,age#1,name#2,age#3]
SortMergeJoin [age#1], [age#3]
Scan PhysicalRDD[name#0,age#1]
Scan PhysicalRDD[name#2,age#3]前面的例子与下面的例子等同,只不过其运行方式略有不同,执行语句:
scala> val innerQuery= sqlContext.sql("SELECT * FROM people a inner join people b on a.age=b.age")
innerQuery: org.apache.spark.sql.DataFrame = [name: string, age: int, name: string, age: int]查看整体执行流程:
scala> innerQuery.queryExecution
res2: org.apache.spark.sql.SQLContext#QueryExecution =
//注意Join Inner
//另外这里面没有Filter
== Parsed Logical Plan ==
'Project [unresolvedalias(*)]
'Join Inner, Some(('a.age = 'b.age))
'UnresolvedRelation [people], Some(a)
'UnresolvedRelation [people], Some(b)
== Analyzed Logical Plan ==
name: string, age: int, name: string, age: int
Project [name#0,age#1,name#4,age#5]
Join Inner, Some((age#1 = age#5))
Subquery a
Subquery people
LogicalRDD [name#0,age#1], MapPartitionsRDD[4] at rddToDataFrameHolder at <console>:22
Subquery b
Subquery people
LogicalRDD [name#4,age#5], MapPartitionsRDD[4] at rddToDataFrameHolder at <console>:22
//注意Optimized Logical Plan与Analyzed Logical Plan
//并没有进行特别的优化,突出这一点是为了比较后面的子查询
//其Analyzed和Optimized间的区别
== Optimized Logical Plan ==
Project [name#0,age#1,name#4,age#5]
Join Inner, Some((age#1 = age#5))
LogicalRDD [name#0,age#1], MapPartitionsRDD[4] at rddToDataFrameHolder ...
//查看其Physical Plan
scala> innerQuery.queryExecution.sparkPlan
res14: org.apache.spark.sql.execution.SparkPlan =
TungstenProject [name#0,age#1,name#6,age#7]
SortMergeJoin [age#1], [age#7]
Scan PhysicalRDD[name#0,age#1]
Scan PhysicalRDD[name#6,age#7]5. 子查询运行流程
执行语句:
scala> val subQuery=sqlContext.sql("SELECT * FROM (SELECT * FROM people WHERE age >= 13)a where a.age <= 19")
subQuery: org.apache.spark.sql.DataFrame = [name: string, age: int]查看整体执行流程:
scala> subQuery.queryExecution
res4: org.apache.spark.sql.SQLContext#QueryExecution =
== Parsed Logical Plan ==
'Project [unresolvedalias(*)]
'Filter ('a.age <= 19)
'Subquery a
'Project [unresolvedalias(*)]
'Filter ('age >= 13)
'UnresolvedRelation [people], None
== Analyzed Logical Plan ==
name: string, age: int
Project [name#0,age#1]
Filter (age#1 <= 19)
Subquery a
Project [name#0,age#1]
Filter (age#1 >= 13)
Subquery people
LogicalRDD [name#0,age#1], MapPartitionsRDD[4] at rddToDataFrameHolder at <console>:22
//这里需要注意Optimized与Analyzed间的区别
//Filter被进行了优化
== Optimized Logical Plan ==
Filter ((age#1 >= 13) && (age#1 <= 19))
LogicalRDD [name#0,age#1], MapPartitionsRDD[4] at rddToDataFrameHolder at <console>:22
== Physical Plan ==
Filter ((age#1 >= 13) && (age#1 <= 19))
Scan PhysicalRDD[name#0,age#1]
Code Generation: true6. 聚合SQL运行流程
执行语句:
scala> val aggregateQuery=sqlContext.sql("SELECT a.name,sum(a.age) FROM (SELECT * FROM people WHERE age >= 13)a where a.age <= 19 group by a.name")
aggregateQuery: org.apache.spark.sql.DataFrame = [name: string, _c1: bigint]运行流程查看:
scala> aggregateQuery.queryExecution
res6: org.apache.spark.sql.SQLContext#QueryExecution =
//注意'Aggregate ['a.name], [unresolvedalias('a.name),unresolvedalias('sum('a.age))]
//即group by a.name被 parsed为unresolvedalias('a.name)
== Parsed Logical Plan ==
'Aggregate ['a.name], [unresolvedalias('a.name),unresolvedalias('sum('a.age))]
'Filter ('a.age <= 19)
'Subquery a
'Project [unresolvedalias(*)]
'Filter ('age >= 13)
'UnresolvedRelation [people], None
== Analyzed Logical Plan ==
name: string, _c1: bigint
Aggregate [name#0], [name#0,sum(cast(age#1 as bigint)) AS _c1#9L]
Filter (age#1 <= 19)
Subquery a
Project [name#0,age#1]
Filter (age#1 >= 13)
Subquery people
LogicalRDD [name#0,age#1], MapPartitionsRDD[4] at rddToDataFrameHolder at <console>:22
== Optimized Logical Plan ==
Aggregate [name#0], [name#0,sum(cast(age#1 as bigint)) AS _c1#9L]
Filter ((age#1 >= 13) && (age#1 <= 19))
LogicalRDD [name#0,age#1], MapPartitions...
//查看其Physical Plan
scala> aggregateQuery.queryExecution.sparkPlan
res10: org.apache.spark.sql.execution.SparkPlan =
TungstenAggregate(key=[name#0], functions=[(sum(cast(age#1 as bigint)),mode=Final,isDistinct=false)], output=[name#0,_c1#14L])
TungstenAggregate(key=[name#0], functions=[(sum(cast(age#1 as bigint)),mode=Partial,isDistinct=false)], output=[name#0,currentSum#17L])
Filter ((age#1 >= 13) && (age#1 <= 19))
Scan PhysicalRDD[name#0,age#1]其它SQL语句,大家可以使用同样的方法查看其执行流程,以掌握Spark SQL背后实现的基本思想。
转自:
Spark修炼之道(进阶篇)——Spark入门到精通:第九节 Spark SQL运行流程解析-阿里云开发者社区developer.aliyun.com

















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









