







 本文提出了一种基于CPU-GPU异构混合编程的遥感数据时空融合算法,通过CUDA架构大幅提升了计算效率。针对STDFA、STARFM、CDSTARFM三种融合算法,实验结果显示最高加速比可达195.6,为高效处理海量遥感数据提供了技术支撑。
本文提出了一种基于CPU-GPU异构混合编程的遥感数据时空融合算法,通过CUDA架构大幅提升了计算效率。针对STDFA、STARFM、CDSTARFM三种融合算法,实验结果显示最高加速比可达195.6,为高效处理海量遥感数据提供了技术支撑。
作 者 信 息
陈 凯1,曹云刚1,2,杨秀春3,潘 梦1,张 敏1
(1. 西南交通大学 地球科学与环境工程学院,四川 成都 611756;2. 西南交通大学 高速铁路运营安全空间信息技术国家地方联合工程实验室,四川 成都 611756;3. 中国农业科学院 农业资源与农业区划研究所,北京 100081)
“【摘要】现有的遥感数据时空融合算法复杂,计算时间长,获取海量时序的高时空分辨率遥感影像非常困难。因此,通过分析GPU并行运算模式与遥感数据时空融合算法的实现步骤,合理地设计了一种基于CPUGPU异构混合编程的遥感数据时空融合并行处理算法流程,将融合算法中的数据密集型计算部分由CPU移植到GPU中执行。遥感数据时空融合算法种类繁多,不同算法的可并行程度与算法复杂度有着很大的差异,选取3种不同类型的遥感数据时空融合算法STDFA、STARFM、CDSTARFM进行GPU并行设计,并使用CUDA架构实现。实验结果表明,基于CPU-GPU异构混合编程技术可大幅度缩减遥感数据时空融合时间,提升计算效率,最高加速比可达到195.6,从而可为海量时空遥感数据的深度应用提供技术支撑。
【关键词】遥感数据时空融合;GPU;CUDA;混合编程;并行计算
【中图分类号】TP302 【文献标识码】A 【文章编号】1672-1586(2019)06-0006-08
”引文格式:陈 凯,曹云刚,杨秀春,等. 基于CPU-GPU异构混合编程的遥感数据时空融合[J].地理信息世界,2019,26(6):6-13.
正文
0 引 言
高时间、高空间分辨率遥感影像在地球系统科学研究中有着非常重要的作用。但是由于技术与资金的限制,在轨同一传感器很难同时获取既具有高空间分辨率,又具有高时间分辨率的影像。因此,研究人员提出了遥感数据时空融合算法来获取高时空分辨率的遥感影像,从而为深入认知地球表层变化提供有效的数据源。遥感影像数据量大,遥感数据时空融合算法复杂度高,使用CPU串行计算效率低、耗时长。因此,通过遥感数据时空融合算法获取海量时序的高时空分辨率遥感影像非常困难。
为解决上述问题,本文设计了一种基于CPU-GPU异构混合编程的遥感数据时空融合并行处理算法流程来大幅度地提高其计算效率。GPU(Graphics Process Unit)有着高质量、高性能的图形处理与图形计算能力,非常适用于数据密集型计算。随着近几年来GPU的快速发展,GPU的计算能力有着巨大的提升,特别是2006年NVIDIA推出CUDA(Compute Unified Device Architecture)架构后,大幅度降低了GPU编程的难度,使得普通用户也能使用GPU处理复杂的计算问题,充分发挥出GPU的高并行计算能力。从而,GPU在高性能计算领域得到了广泛的使用。GPU有着远高于CPU的数值运算能力,现有研究证明在浮点运算、并行计算等方面,GPU相比CPU来说可以提高几十倍乃至于上百倍的性能。使用GPU处理海量遥感数据能够充分发挥CUDA大量处理器核心的高并行计算能力,是一种非常有效的处理方法。
遥感数据时空融合算法中存在大量的数据密集型计算和易于并行计算的步骤。关庆锋团队利用了GPU的高并行计算能力开发了STARFM、ESTARFM和STNLFFM3个遥感数据时空融合模型的并行算法,并使用了自适应数据分解、自适应线程设置、自适应寄存器优化和循环任务分配等策略减少了冗余计算和内存消耗,提高了灵活性和可移植性。但需要对输入的Landsat和MODIS影像进行预处理,限制了模型在实际应用中流程化处理的可行性。
因此,本文结合遥感数据时空融合算法和CUDA架构,基于CPU-GPU异构混合编程设计了一种合理的遥感数据时空融合并行处理算法流程,验证了STDFA、STARFM、CDSTARFM3种模型并行化的可行性,并详细论述了每一个时空融合模型中各个不同组件的并行处理算法与加速效果。本文程序要求输入MODGQ09标准数据集和解压缩后Landsat原始数据集,不需要额外的预处理操作,支持流程化处理(源代码参考网址:https://github.com/bcrx/chenkai)。其中,CPU负责执行复杂的逻辑处理、事务处理与数据读写,GPU负责遥感数据时空融合算法中的数据密集型计算和易于并行部分的计算。充分发挥CPU和GPU各自的优势,大幅度地降低高时空分辨率影像的融合时间。
1 实验数据与方法
1.1 实验数据
本文选取两幅L a n d s a t 8 O L I影像(影像尺寸为7 864×7 767,空间分辨率为30 m),4幅MODGQ09影像作为实验数据,各数据的获取时间和用途等信息见表1。该地区大部分为植被覆盖,有少部分居民区等其他地物,满足遥感数据时空融合算法的要求。其中,Landsat8 OLI数据来源于地理空间数据云,MODIS反射率产品来源于NASA土地数据中心。
表1 Landsat8 OLI数据与MODIS数据
Tab.1 Landsat8 OLI and MODIS dataset

本文实验计算机配置如下:CPU型号i7-6700,内存8 G,基准速度2.60 GHz;显卡型号NVIDIA GTX960M,显卡内存2 G,CUDA处理器核心数量640,核心频率1 096 MHz。
1.2 实验方法
1.2.1 CPU-GPU异构混合编程
现有主要的CPU-GPU异构混合编程架构有两个,分别是CUDA和OpenCL。CUDA为NVIDIA推出的一个异构并行编程架构,相比OpenCL、CUDA拥有良好的开发环境、丰富的函数库和更加优秀的性能。本文采用CUDA架构,其中CPU作为主机负责执行复杂的逻辑与事件处理,加载GPU所需要的数据。GPU作为设备,负责大规模密集型数据的并行计算。
1.2.2 遥感数据时空融合算法
本文选取了3种具有代表性的遥感数据时空融合算法:
1)像元分解降尺度算法(the Spatial Temporal Data Fusion Approach,STDFA)。
2)自适应遥感影像时空融合方法(the Spatial and Temporal Adaptive Reflectance Fusion Model,STRAFM)。
3)混合模型融合方法(Combining STARFM and Downscaling Mixed Pixel Algorithm,CDSTARFM)。
现有的这3种算法适用于CPU串行计算,不能直接移植到GPU中执行。因此,通过分析这3种算法的结构,结合GPU并行运算的模式与特点,将其中可并行计算部分分为多个独立组件,移植到GPU中执行。基于CPU-GPU异构混合编程的时空数据融合算法流程如图1所示,粗斜体部分使用GPU并行处理,其他步骤使用CPU处理。
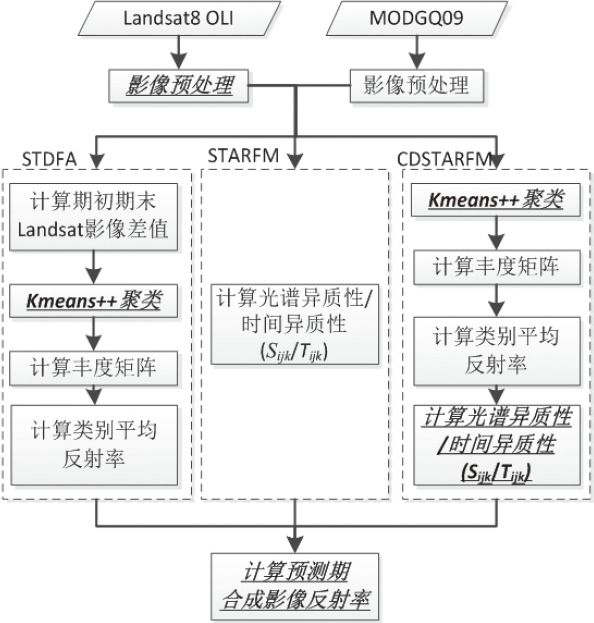
图1 基于CPU-GPU异构混合编程的时空数据融合算法流程(粗斜体部分为GPU运算)
Fig.1 Temporal and spatial fusion algorithm flow based on CPU-GPU heterogeneous mixed programming (the bold italic part is GPU operation)
每个并行计算的CUDA核函数通用逻辑及其各设备间的数据通信如图2所示,其中每个并行计算组件的计算单元Grid 、Block 、Thread 之间数据通信过程一致,若输入数据大小为M ×N ,每个block 的thread 数量有限,不能设置过大,每个block 分配256个thread ,则总共block数量计算公式为:
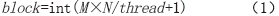
不同的核函数主机内存与显存、显存与计算单元之间的数据通信有细微的差异,同一个核函数这两者之间的数据通信内容一致。下面将对GPU并行设计细节做详细阐述。
1)Landsat影像预处理
Landsat影像预处理分为以下两个步骤:
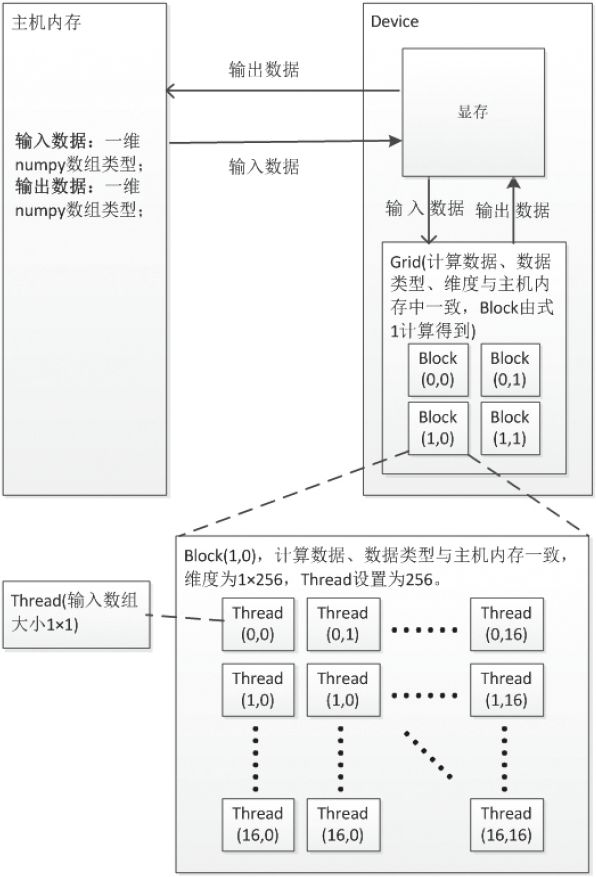
图2 CUDA核函数逻辑图
Fig.2 Logic diagram of CUDA kernel function
①辐射定标。本文使用Landsat8 OLI影像数据计算大气顶部光谱辐射值,计算每一个像素点大气顶部光谱辐射值时均为独立计算,适合使用GPU并行处理;
②大气校正。其中,大气校正可使用6S模型或者FLAASH模型,不做GPU并行处理。辐射定标并行处理流程如下:
① 读取L a n d s a t 影像与元数据得到亮度值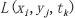 与波段λ的调整因子
与波段λ的调整因子
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 365
365

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









