






 本文介绍了Kafka的Partition分配策略,旨在实现负载均衡。详细阐述了Producer如何发送消息到Partition Leader,以及Follower如何复制数据。讨论了消息投递的可靠性,包括ack参数的三种情况。同时,分析了消息消费的可靠性,如at most once、at least once和exactly once策略。最后预告了后续将探讨的Broker状态判断和leader选举。
本文介绍了Kafka的Partition分配策略,旨在实现负载均衡。详细阐述了Producer如何发送消息到Partition Leader,以及Follower如何复制数据。讨论了消息投递的可靠性,包括ack参数的三种情况。同时,分析了消息消费的可靠性,如at most once、at least once和exactly once策略。最后预告了后续将探讨的Broker状态判断和leader选举。
Kafka的高可用源于其多个副本(replication)。
拥有多个副本,那么带来的问题就是数据怎么同步。我们都知道数据是存放在partition物理目录下的文件里面。通过前面几节的介绍,我们也知道消息过来后直接跟partition leader交互,然后由leader进行数据同步。由于partition 的replication机制,在kafka看来partition不分leader 和 follower之分的,都是replica。
同一个partition可能会有多个replica,此时需要在这些replica之间选出一个leader,producer和Consumer只与leader交互,其它replica作为follower从leader中复制数据。

图片来源自网络
一个topic下可能会有多个partition,同一个partition又可能有多个replica,那它们是怎么分配的,不可能无秩序的。
为了更好的做负载均衡,Kafka尽量将所有的Partition均匀分配到整个集群上。Kafka分配Replica的算法如下:
· 将所有存活的N个Brokers和待分配的Partition排序
· 将第i个Partition分配到第(i mod n)个Broker上,这个Partition的第一个Replica存在于这个分配的Broker上,并且会作为partition的优先副本
· 将第i个Partition的第j个Replica分配到第((i + j) mod n)个Broker上
假设集群一共有4个brokers,一个topic有4个partition,每个Partition有3个副本。下图是每个Broker上的副本分配情况。
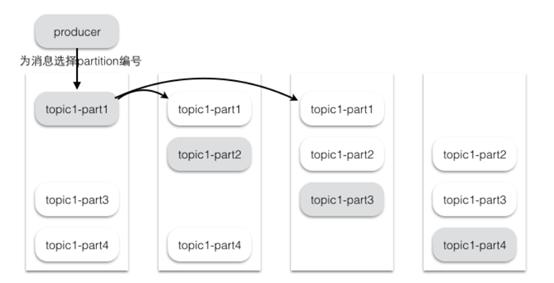
图片来源自网络
Producer在发布消息到某个Partition时,先通过ZooKeeper找到该Partition的Leader,然后无论该Topic的Replication有多少个,Producer只将该消息发送到该Partition的Leader。Leader会将该消息写入其本地Log。每个Follower都从Leader pull数据。这种方式上,Follower存储的数据顺序与Leader保持一致。Follower在收到该消息并写入其Log后,向Leader发送ACK。一旦Leader收到了ISR中的所有Replica的ACK,该消息就被认为已经commit了,Leader将增加HW并且向Producer发送ACK。
为了提高性能,每个Follower在接收到数据后就立马向Leader发送ACK,而非等到数据写入Log中。因此,对于已经commit的消息,Kafka只能保证它被存于多个Replica的内存中,而不能保证它们被持久化到磁盘中,也就不能完全保证异常发生后该条消息一定能被Consumer消费。
Consumer读消息也是从Leader读取,只有被commit过的消息才会暴露给Consumer。
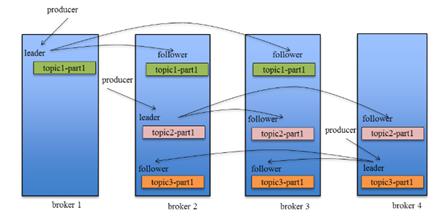
图片来源自网络
消息投递的可靠性
- 当ack=0的时候,表示producer发送出去message,只要对应的kafka broker topic partition leader接收到的这条message,producer就返回成功,不管partition leader 是否真的成功把message真正存到kafka。
- 当ack=1的时候,表示producer发送出去message,同步的把message存到对应topic的partition的leader上,然后producer就返回成功,partition leader异步的把message同步到其他partition replica上。
- 当ack=all或-1,表示producer发送出去message,同步的把message存到对应
topic的partition的leader和对应的replica上之后,才返回成功
消息消费的可靠性
at most once:最多一次,这个和JMS中"非持久化"消息类似,发送一次,无论成败,将不会重发。消费者fetch消息,然后保存offset,然后处理消息;当client保存offset之后,但是在消息处理过程中出现了异常,导致部分消息未能继续处理。那么此后"未处理"的消息将不能被fetch到,这就是"at most once"。
at least once:消息至少发送一次,如果消息未能接受成功,可能会重发,直到接收成功。消费者fetch消息,然后处理消息,然后保存offset。如果消息处理成功之后,但是在保存offset阶段zookeeper异常导致保存操作未能执行成功,这就导致接下来再次fetch时可能获得上次已经处理过的消息,这就是"at least once",原因offset没有及时的提交给zookeeper,zookeeper恢复正常还是之前offset状态。
exactly once:消息只会发送一次。kafka中并没有严格的去实现(基于2阶段提交),我们认为这种策略在kafka中是没有必要的。
通常情况下 at-least-once 是我们首选。
这一节对上一节留的问题说完了,partition replica的分配及消息的可靠性(投递和消费),下一节会说到,kafka 针对broker是怎么判断“活着”的状态以及leader的选举,再着重说说kafka顺序写入与数据读取其中涉及到的zero-copy

















 1262
1262

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









