







简介:SSH框架是Java Web开发中结合Struts2、Spring和Hibernate三大开源框架的集成方案,提供了高效的MVC架构和数据库操作支持。本文章将深入探讨如何使用SSH框架执行数据库的增删改查(CRUD)操作,包括Struts2的动作处理、Spring的依赖注入和事务管理,以及Hibernate的对象关系映射能力。同时,文章会覆盖数据库连接管理、异常处理、视图层展示以及测试等关键方面,旨在帮助开发者全面理解并应用SSH框架进行高效的数据库操作和Web应用程序的构建。
1. SSH框架概述与数据库操作效率
1.1 SSH框架的组成与原理
1.1.1 SSH框架的核心组件解析
SSH框架是Java EE开发中常用的一个框架组合,它包括了Struts2、Spring和Hibernate三个组件,分别担任Web层、业务逻辑层和数据访问层。Struts2作为Web层框架,负责处理用户请求并返回响应;Spring则提供了一个完整的业务逻辑层处理方案,特别是其依赖注入机制,大大简化了业务组件之间的耦合;Hibernate作为数据持久层,提供了ORM映射,使得开发者可以以面向对象的方式来操作数据库。
1.1.2 SSH框架与传统MVC的对比
相较于传统MVC模式,SSH框架在多个层面进行了优化与改进。传统的MVC模式中,模型层(Model)通常与数据库直接打交道,而SSH中,这一层被Spring和Hibernate的组合所取代。Spring通过依赖注入和声明式事务管理,提供了更为松耦合的业务逻辑层;Hibernate则通过对象关系映射(ORM)技术,抽象化数据库操作,简化了数据持久层的复杂性。
1.2 数据库操作的基本概念
1.2.1 SQL语言基础回顾
SQL(Structured Query Language)是用于操作关系数据库的标准语言。它包括数据查询、更新、插入和删除等操作。熟悉基本的SQL语句对于数据库操作至关重要,如SELECT用于查询,INSERT用于插入数据,UPDATE用于更新数据,DELETE用于删除数据。理解这些基本的SQL语句对于提高数据库操作效率至关重要。
1.2.2 数据库事务的ACID属性
在进行数据库操作时,保证事务的ACID属性是非常关键的。ACID代表原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)和持久性(Durability)。原子性保证事务是一个不可分割的工作单位;一致性确保事务的执行使数据库从一个一致性状态转变到另一个一致性状态;隔离性保证并发事务的执行互不干扰;持久性则意味着一旦事务提交,其结果就是永久性的。
1.3 提升数据库操作效率的方法
1.3.1 索引优化与查询性能
在数据库中合理地使用索引可以显著提升查询速度。索引是数据库用来快速查找数据记录的数据结构,类似于书籍的目录。数据库通过索引可以在大量数据中快速定位到特定的数据记录,减少数据扫描范围,提高查询效率。但索引并不是越多越好,不合理的索引设计反而会导致更新操作变慢和额外的存储开销。
1.3.2 SQL语句与性能调优
编写高效的SQL语句是优化数据库操作的关键。合理使用JOIN语句、避免使用子查询、减少SELECT * 的使用、合理选择数据类型和排序方式等,都可以显著提升SQL语句的执行效率。通过分析慢查询日志,可以定位到执行效率低下的SQL语句,进一步进行调整和优化。使用EXPLAIN语句可以查看SQL执行计划,帮助我们理解数据库是如何执行查询的,并据此进行调整。
以上为第一章的内容概要,本章节通过对SSH框架的组成与原理进行了详细解析,并对数据库操作的基础知识进行了回顾,最后介绍了提升数据库操作效率的方法。这些知识是建立高效SSH框架应用的基础,为后续章节的深入学习打下了坚实的基础。
2. Struts2在CRUD操作中的角色与XML配置
2.1 Struts2框架的基本原理
Struts2作为SSH框架中的一部分,在Web应用开发中扮演着重要的角色,特别是在实现MVC模式中的控制器(Controller)部分。Struts2框架将Web层的业务逻辑处理、视图管理和用户请求处理整合在一起,使得整个Web应用的结构更为清晰,更易于开发和维护。
2.1.1 MVC模式在Struts2中的体现
在Struts2中,MVC模式的体现主要表现在以下几个方面:
- Model(模型) : Model代表业务模型,通常由JavaBean来实现。它们用于封装数据以及与数据库进行交互的业务逻辑。
- View(视图) : View是用户界面,负责展示数据(Model)。Struts2支持多种视图技术,包括JSP、FreeMarker、Velocity等。
- Controller(控制器) : Struts2框架的核心是Action类,它是控制器的实现。用户请求首先被发送到Action类,然后Action类根据请求调用业务逻辑,最后决定哪个视图应该被显示。
Struts2通过Action映射机制,将用户请求与具体的业务处理逻辑关联起来。请求到达后,Struts2容器会根据配置文件(如 struts.xml )中的映射信息,将请求分发到相应的Action类中进行处理。
2.1.2 Struts2的Action映射与结果类型
在Struts2中,Action映射主要通过XML配置文件来定义。每一个Action都可以映射到一个URL,当该URL的请求到达时,Struts2就会创建对应的Action实例并执行其方法。
-
Action映射 :在
struts.xml中定义Action的映射,包括Action的名字、类名以及返回的视图页面。
xml <action name="editUser" class="com.example.UserAction"> <result name="success">/edit_user.jsp</result> </action> -
结果类型 :Struts2支持多种结果类型,如
dispatcher、redirect、chain等。dispatcher是默认的结果类型,它会将控制权交还给Struts2框架,并请求一个JSP页面。
xml <result type="dispatcher">/result.jsp</result>
2.2 XML配置详解
2.2.1 Struts2的配置文件结构
Struts2框架的配置文件 struts.xml 主要由几个部分组成: constant 元素、 package 元素、 action 元素以及 interceptor 元素等。
- constant元素 :用于配置Struts2框架的运行时属性,如文件上传大小限制、国际化资源文件路径等。
xml <constant name="struts.multipart.maxSize" value="20971520" />
- package元素 :是struts.xml中的核心元素,定义了Action的命名空间以及拦截器栈(interceptor stack)。
xml <package name="user" extends="struts-default" namespace="/"> <action name="login" class="com.example.LoginAction"> <result name="success">/home.jsp</result> </action> </package>
2.2.2 常用的配置元素与作用域
配置文件中的一些常用元素包括 interceptor 、 result-type 和 exception-mapping 等。
- interceptor元素 :用于定义自定义拦截器,拦截器在Action执行前后提供钩子(Hook)功能,以扩展Struts2框架的功能。
xml <interceptor name="userInterceptor" class="com.example.UserInterceptor" />
- result-type元素 :可以自定义返回类型,与标准的结果类型不同,自定义的结果类型可以完成更复杂的功能。
xml <result-type name="tiles" class="org.apache.struts2.result.TilesResult" />
- exception-mapping元素 :用于处理Action执行时可能出现的异常,可以将异常映射到某个Action或页面。
xml <exception-mapping result="error" exception="java.lang.Exception" />
2.3 CRUD操作实践
CRUD操作是数据库应用中的基本操作,分别对应创建(Create)、读取(Read)、更新(Update)和删除(Delete)。Struts2通过Action类来实现这些操作,并通过配置文件来映射请求和结果。
2.3.1 增加记录的操作流程与代码实现
操作流程一般如下:
- 创建对应的Model类和Action类。
- 在
struts.xml配置文件中定义Action映射。 - 在Action类中编写添加记录的逻辑。
- 定义返回的视图页面。
代码实现 :
public class CreateUserAction extends ActionSupport {
private User user;
public String execute() {
// 业务逻辑,添加用户记录到数据库
userService.addUser(user);
return SUCCESS;
}
}
在 struts.xml 中配置:
<action name="createUser" class="com.example.CreateUserAction">
<result name="success">/user_created.jsp</result>
</action>
2.3.2 删除记录的操作流程与代码实现
删除操作与增加操作类似,但需要传递一个标识符来确定要删除的记录。
代码实现 :
public class DeleteUserAction extends ActionSupport {
private Long id;
public String execute() {
// 业务逻辑,删除指定ID的用户记录
userService.deleteUser(id);
return SUCCESS;
}
}
在 struts.xml 中配置:
<action name="deleteUser" class="com.example.DeleteUserAction">
<result name="success">/user_deleted.jsp</result>
</action>
2.3.3 修改记录的操作流程与代码实现
修改操作通常包括加载现有记录,修改数据,然后更新到数据库。
代码实现 :
public class UpdateUserAction extends ActionSupport {
private User user;
public String execute() {
// 业务逻辑,更新指定ID的用户记录
userService.updateUser(user);
return SUCCESS;
}
}
在 struts.xml 中配置:
<action name="updateUser" class="com.example.UpdateUserAction">
<result name="success">/user_updated.jsp</result>
</action>
2.3.4 查询记录的操作流程与代码实现
查询操作可能涉及分页、过滤等复杂的逻辑,Struts2通过返回不同的结果类型来处理。
代码实现 :
public class ListUserAction extends ActionSupport {
// List或Criteria等查询接口的实现
public List<User> getUsers() {
return userService.getUsers();
}
}
在 struts.xml 中配置:
<action name="listUsers" class="com.example.ListUserAction">
<result name="success" type="dispatcher">/list_users.jsp</result>
</action>
以上展示的Struts2框架在CRUD操作中的应用,通过定义Action类、配置 struts.xml 以及编写与业务逻辑相关的Java代码,实现Web层的数据操作和流程控制。这样可以有效地将业务逻辑和视图展示分离,增强系统的可维护性和扩展性。
3. Spring的依赖注入、Bean管理及事务控制
3.1 依赖注入与Bean生命周期
3.1.1 依赖注入的原理与应用
依赖注入(Dependency Injection, DI)是一种设计模式,其核心思想是让调用者不负责资源的查找和创建,而由容器自动提供所需的资源。这种模式降低了组件之间的耦合度,增强了应用的可配置性和可测试性。在Spring框架中,依赖注入通过以下两种方式进行:
- 构造器注入(Constructor Injection) :通过构造函数为依赖的属性赋值。这种方式强制依赖在使用前必须被提供,确保了依赖项的可用性。
- setter注入(Setter Injection) :通过setter方法为依赖的属性赋值。这种方式提供了一种更灵活的注入方式,允许依赖项在某些情况下可以为空。
以下是构造器注入的示例代码:
public class SomeService {
private SomeDependency dependency;
// 构造器注入
public SomeService(SomeDependency dependency) {
this.dependency = dependency;
}
// SomeService的业务逻辑方法...
}
// Bean配置
@Bean
public SomeService someService(SomeDependency dependency) {
return new SomeService(dependency);
}
依赖注入的实现原理基于Spring的控制反转(Inversion of Control, IoC)容器,容器负责创建和管理Bean的生命周期。Spring通过依赖注入的方式,将配置的依赖项自动注入到目标Bean中。
3.1.2 Bean的作用域与生命周期管理
在Spring中,Bean具有不同的作用域,可以影响其生命周期和可见性。主要作用域包括:
- singleton :每个Spring IoC容器中只有一个Bean实例,这是默认作用域。
- prototype :每次请求Bean实例时,容器都会创建一个新的Bean实例。
- request :每次HTTP请求都会创建一个新的Bean实例,仅适用于Web应用。
- session :同一个HTTP session共享一个Bean实例。
- application :整个Web应用共享一个Bean实例,同
session作用域类似,但作用范围为整个Web应用。 - websocket :在整个WebSocket生命周期内共享一个Bean实例。
Bean的生命周期管理涉及初始化和销毁两个重要阶段:
- 初始化 :Bean创建后,Spring容器会调用
init方法。此方法可以通过@PostConstruct注解标记,或在XML配置的init-method属性中指定。 - 销毁 :当容器关闭时,Spring容器会调用
destroy方法。此方法可以通过@PreDestroy注解标记,或在XML配置的destroy-method属性中指定。
下面是一个通过注解管理Bean生命周期的示例:
@Component
public class SomeBean {
// 初始化方法
@PostConstruct
public void init() {
System.out.println("Bean is being initialized");
}
// 销毁方法
@PreDestroy
public void destroy() {
System.out.println("Bean is being destroyed");
}
}
通过这种方式,开发者可以控制Bean的创建和销毁,从而精确管理Spring应用中的资源。
3.2 事务管理机制
3.2.1 Spring事务的隔离级别与传播行为
在数据库操作中,事务的管理是保证数据一致性和完整性的关键。Spring框架提供了声明式事务管理,使得开发者可以不用编写复杂的代码即可管理事务。Spring事务的隔离级别和传播行为是两个重要的概念。
-
隔离级别 :事务隔离级别定义了不同事务之间的数据可见性和并发控制。Spring支持以下四种隔离级别:
-
DEFAULT :使用底层数据库默认的隔离级别。
- READ_UNCOMMITTED :允许读取尚未提交的数据变更,可能导致脏读、幻读或不可重复读。
- READ_COMMITTED :只能读取已经提交的数据,可以避免脏读,但可能发生不可重复读和幻读。
- REPEATABLE_READ :确保同一事务多次读取同一数据的结果一致,可以避免脏读和不可重复读,但可能发生幻读。
-
SERIALIZABLE :完全避免脏读、不可重复读和幻读,但并发性能低。
-
传播行为 :事务的传播行为定义了事务方法与外部事务的边界。Spring支持以下传播行为:
-
REQUIRED :如果当前没有事务,就新建一个事务,如果已经存在一个事务中,加入到这个事务中。
- SUPPORTS :支持当前事务,如果当前没有事务,就以非事务方式执行。
- MANDATORY :使用当前的事务,如果当前没有事务,就抛出异常。
- REQUIRES_NEW :新建事务,如果当前存在事务,把当前事务挂起。
- NOT_SUPPORTED :以非事务方式执行操作,如果当前存在事务,就把当前事务挂起。
- NEVER :以非事务方式执行,如果当前存在事务,则抛出异常。
- NESTED :如果当前存在事务,则在嵌套事务内执行。如果当前没有事务,则进行与
REQUIRED相似的操作。
在Spring中,可以通过 @Transactional 注解来指定事务的隔离级别和传播行为,也可以在XML配置文件中进行配置。
@Transactional(isolation = Isolation.READ_COMMITTED, propagation = Propagation.REQUIRED)
public void someServiceMethod() {
// 业务逻辑代码
}
事务的隔离级别和传播行为配置对事务的完整性、一致性以及应用性能有着直接的影响,合理配置可以有效避免并发问题,优化事务性能。
3.2.2 声明式事务与编程式事务的比较
Spring提供两种事务管理的方式:声明式事务和编程式事务。
- 声明式事务 :声明式事务管理是基于AOP实现的,允许开发者声明事务应该怎样管理,通常通过
@Transactional注解或XML配置进行声明。这种方式的优点是简单且不会侵入业务代码,非常适合用于业务逻辑和事务管理分离的场景。
@Transactional
public void performTransaction() {
// 执行一些数据操作
}
- 编程式事务 :编程式事务管理则通过编码方式管理事务,开发者需要使用
TransactionTemplate或者PlatformTransactionManager来管理事务。这种方式虽然较为繁琐,但在一些复杂的事务逻辑中提供了更高的灵活性。
@Autowired
private TransactionTemplate transactionTemplate;
public void performComplexTransaction() {
transactionTemplate.execute(new TransactionCallbackWithoutResult() {
@Override
protected void doInTransactionWithoutResult(TransactionStatus status) {
// 执行一些数据操作
}
});
}
编程式事务管理提供了对事务处理过程更细粒度的控制,但其缺点是代码较为复杂,且难以重用。在实际应用中,通常推荐使用声明式事务管理,因为它更简洁且易于维护。
3.3 实践中事务的应用与优化
3.3.1 基于注解的事务管理配置
在Spring中,基于注解的声明式事务管理是使用最为广泛的配置方式。开发者仅需在方法上添加 @Transactional 注解,就可以让Spring负责该方法的事务管理。这种方式简单易用,减少了事务管理的配置和编码工作。
@Service
public class SomeService {
@Autowired
private SomeDao someDao;
@Transactional
public void transferMoney(Long fromId, Long toId, BigDecimal amount) {
someDao.debit(fromId, amount);
someDao.credit(toId, amount);
}
}
以上代码中, transferMoney 方法在执行过程中,要么都成功,要么遇到异常都会回滚,保证了资金转账操作的原子性和一致性。 @Transactional 注解可以配置多个属性来控制事务的行为,如 isolation 、 propagation 等。
3.3.2 事务的性能优化技巧
虽然事务管理为应用带来了诸多便利,但在性能方面也引入了额外的开销。以下是提高事务管理性能的一些优化技巧:
- 使用合适的隔离级别 :选择合适的隔离级别可以有效减少锁的竞争,提高并发处理能力。合理选择隔离级别,既能满足业务需求,又能避免不必要的开销。
- 仅在需要时使用事务 :确保只有在必要的操作上才使用事务,例如数据库访问操作。不相关的操作不应放入事务块中。
- 控制事务的大小 :尽可能缩短事务的持续时间,将大的事务拆分成小的事务,可以减少锁的持续时间,从而提高并发性能。
- 优化数据库访问 :在数据库访问层面进行优化,例如使用批量操作和减少数据库访问次数,以提高事务处理的效率。
- 使用只读事务 :如果某个事务只涉及到读操作,可以将其配置为只读事务,这样Spring会通知底层数据源优化相应的操作。
@Transactional(readOnly = true)
public User findUserById(Long id) {
return userRepository.findById(id);
}
在上述代码中,如果 findUserById 方法仅涉及读操作,则加上 readOnly = true 可以提升性能。
- 使用连接池 :配置数据源使用连接池,可以有效管理数据库连接,减少建立和关闭连接的开销。
事务管理的性能优化是一个持续的过程,需要根据具体的应用场景和性能测试结果不断调整和改进。通过上述的技巧,可以在保持事务一致性的前提下,尽可能地优化事务处理性能。
4. Hibernate的ORM技术与Session接口操作
Hibernate作为持久化层框架,提供了对象关系映射(Object-Relational Mapping,ORM)技术,允许开发者以面向对象的方式操作关系型数据库。本章节将深入探讨Hibernate框架的核心组件、Session接口的使用、以及如何利用高级映射与查询技术来处理更复杂的数据操作场景。
4.1 ORM技术概述
4.1.1 ORM的概念与优势
ORM全称是Object-Relational Mapping,即对象关系映射。它是一种编程技术,用于在不同的系统之间进行转换,主要是在关系数据库和对象之间进行映射。传统的JDBC操作要求开发者必须手动编写SQL语句,并处理结果集的转换,这使得代码中充斥着大量的数据操作逻辑,降低了开发效率并且增加了错误的可能性。
ORM框架如Hibernate,通过注解或XML配置,自动将Java对象持久化为数据库中的数据表,反之亦然。开发者只需关注业务逻辑,无需直接编写SQL语句,就可以实现数据的增删改查操作。这种模型可以大幅简化数据访问层的代码,提高开发效率,并且保持代码的可读性和可维护性。
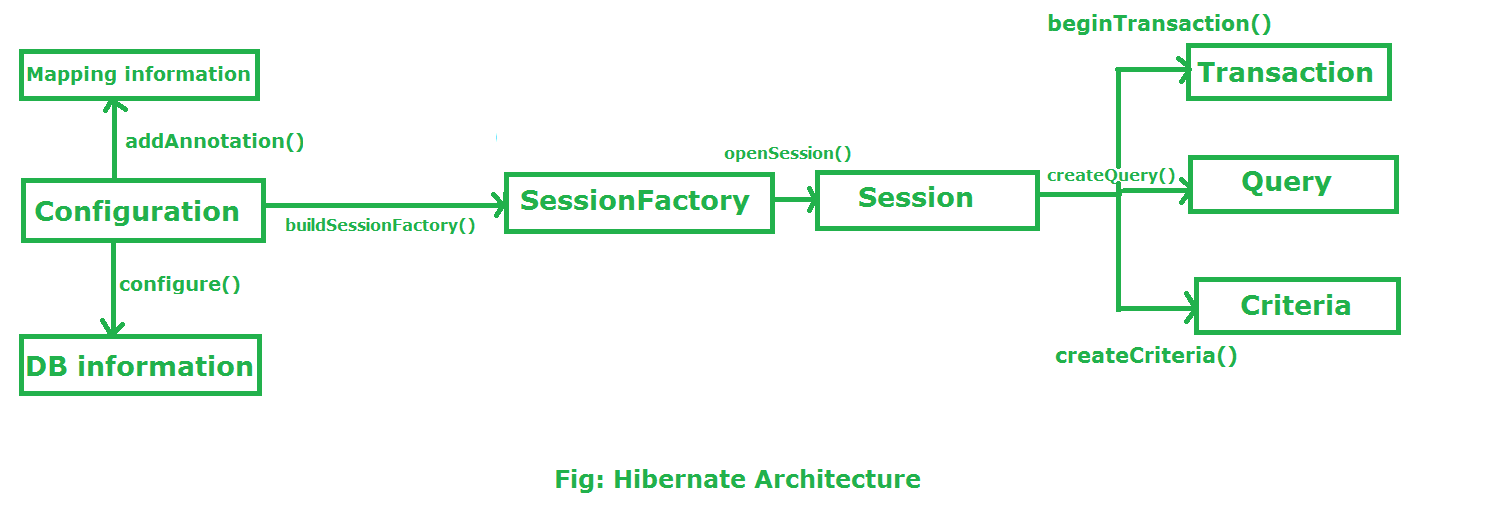
4.1.2 Hibernate的架构及其关键组件
Hibernate的核心架构包括以下几个关键组件:
-
Session Factory :负责创建Session实例,是线程安全的,并且可以被应用中的多个线程共享。它在应用初始化时创建,并且应当被缓存起来,在整个应用生命周期中复用。它通过读取Hibernate配置文件和映射信息,负责管理和配置Hibernate运行环境。
-
Session :表示应用与持久层之间的一次交互,是数据操作的单元,具有打开和关闭两种状态。Session负责提供对数据库进行操作的方法,例如保存、更新、删除和查询对象等。
-
Transaction :封装了对事务的操作,例如提交、回滚和设置隔离级别。一个Transaction实例与一个Session实例相关联,并且不能跨Session进行事务处理。
-
Query :代表执行在数据库上的查询操作。Hibernate允许开发者通过HQL(Hibernate Query Language)或Criteria API编写查询语句。
-
Configuration :用于读取Hibernate配置文件(hibernate.cfg.xml),配置信息包括数据库连接信息、映射文件路径和Hibernate的全局属性。
4.2 Session接口的使用
4.2.1 Session的生命周期与状态管理
Session的生命周期从创建开始,到关闭结束。每个Session实例负责一个持久化上下文,这个上下文负责追踪和管理数据模型对象(称为实体)的生命周期状态。
- 瞬态(Transient) :在Session的持久化上下文之外的实体实例。
- 持久化(Persistent) :与Session关联的实体实例。
- 游离(Detached) :之前与Session关联,但现在关闭或不相关的实体实例。
Session通过一系列的方法来控制实体的生命周期状态:
-
save():将瞬态实体持久化到数据库。 -
update()或merge():将游离实体重新关联到当前Session。 -
get()或load():从数据库加载持久化实体。 -
close():关闭Session,结束实体的持久化上下文。
4.2.2 CRUD操作在Hibernate中的实现
在Hibernate中进行基本的CRUD操作是非常简单的。以下是每种操作的代码示例及其逻辑分析:
Session session = sessionFactory.openSession();
Transaction tx = session.beginTransaction();
try {
// Create
User user = new User("username", "password");
session.save(user);
// Read
User retrievedUser = (User) session.get(User.class, 1L);
// Update
retrievedUser.setPassword("newPassword");
session.update(retrievedUser);
// Delete
session.delete(retrievedUser);
tx.commit();
} catch (Exception e) {
tx.rollback();
} finally {
session.close();
}
- 创建(Create) :使用
session.save()方法将一个新的实体对象保存到数据库。在调用此方法前,实体处于瞬态状态。 -
读取(Read) :可以通过
session.get()或session.load()方法读取实体。get()方法在实体不存在时返回null,而load()方法抛出异常,通常建议使用load()方法,因为它通常有更高的性能。 -
更新(Update) :通过调用
session.update()或session.merge()方法将实体状态同步到数据库。使用update()需要实体在之前已被加载,否则会抛出异常;而merge()方法可以将一个游离状态的实体同步到数据库。 -
删除(Delete) :使用
session.delete()方法从数据库中删除一个实体。调用此方法后,实体变为瞬态状态,并最终从数据库中删除。
4.3 高级映射与查询技术
4.3.1 关联映射与继承映射的处理
Hibernate支持对象之间的关联映射,包括一对多、多对一、一对一和多对多。关联映射通常通过在实体类中声明关联属性来实现,并通过XML配置或注解来指定关联的详细信息。
继承映射允许开发者将具有共性的父类映射为一张数据库表,而子类映射为附加表或通过表继承的方式映射。Hibernate提供了多种继承映射策略,如单表继承、类表继承和联合表继承。
4.3.2 HQL与Criteria查询的应用实例
HQL(Hibernate Query Language)是面向对象的查询语言,它允许开发者使用Java类和属性来编写查询语句,而不是直接使用SQL语句。Hibernate负责将HQL语句翻译成对应的SQL语句并执行。
Session session = sessionFactory.openSession();
Transaction tx = session.beginTransaction();
try {
Query query = session.createQuery("FROM User WHERE username = :username");
query.setParameter("username", "admin");
List<User> users = query.list();
tx.commit();
} catch (Exception e) {
tx.rollback();
} finally {
session.close();
}
Criteria API提供了一种类型安全的方式来进行查询操作,它允许通过方法链的方式动态地构建查询条件,非常适合进行复杂的查询操作。
Session session = sessionFactory.openSession();
Transaction tx = session.beginTransaction();
try {
Criteria criteria = session.createCriteria(User.class);
criteria.add(Restrictions.eq("username", "admin"));
List<User> users = criteria.list();
tx.commit();
} catch (Exception e) {
tx.rollback();
} finally {
session.close();
}
通过本章节的介绍,您已经对Hibernate的ORM技术及其Session接口操作有了深入的理解。Hibernate通过对象关系映射技术简化了Java对象与数据库表之间的交互,通过Session接口提供了方便的数据操作方法。在实际开发中,通过合理运用高级映射与查询技术,能够有效地处理复杂的数据操作场景,提升应用的性能和可维护性。
5. SSH框架的高级应用与优化
5.1 综合异常处理机制
5.1.1 异常处理策略的设计与实现
在SSH框架中,异常处理是一个关键的组成部分,它确保了应用程序在出现错误时能够稳定地运行,并提供对错误的详细反馈。设计一个有效的异常处理机制需要考虑到不同层次的异常捕获和响应策略。首先,我们需要定义不同的异常类型:业务异常和系统异常。
-
业务异常(BusinessException) :这类异常通常由业务逻辑中的特定条件触发,例如用户输入错误、数据验证失败等。它们不应该导致应用程序崩溃,而是通过友好的错误信息反馈给用户。
-
系统异常(SystemException) :这类异常通常是由于系统资源问题或者不可预知的情况引起的,例如数据库连接失败、文件读写错误等。它们可能会导致程序的不稳定性,因此需要进行日志记录,并通知系统管理员。
为了实现上述策略,我们需要在SSH框架的Struts2和Spring层面上进行相应的配置。在Struts2中,我们可以使用 struts.xml 配置文件来定义全局异常处理,将特定的异常类型映射到对应的处理动作(Action)上。
<global-exception-mappings>
<exception-mapping result="errorPage" exception="com.example.MyBusinessException"/>
<exception-mapping result="systemErrorPage" exception="com.example.MySystemException"/>
</global-exception-mappings>
在Spring中,我们可以创建自定义的 @ControllerAdvice 类来处理全局的异常。例如:
@ControllerAdvice
public class GlobalExceptionHandler {
@ExceptionHandler(BusinessException.class)
public String handleBusinessException(BusinessException e, Model model) {
// 记录异常信息到日志
// 返回错误页面给用户
model.addAttribute("errorMessage", e.getMessage());
return "errorPage";
}
@ExceptionHandler(SystemException.class)
public String handleSystemException(SystemException e, Model model) {
// 记录异常信息到日志,并通知管理员
// 返回系统错误页面给用户
model.addAttribute("systemErrorMessage", e.getMessage());
return "systemErrorPage";
}
}
5.1.2 自定义异常与全局异常处理器
SSH框架鼓励开发者使用自定义异常来更好地封装和处理特定的错误情况。自定义异常应该继承自 Exception 类或其子类,并可以添加特定的属性来描述错误。
public class BusinessException extends Exception {
public BusinessException(String message) {
super(message);
}
}
public class SystemException extends Exception {
public SystemException(String message) {
super(message);
}
}
在全局异常处理器 GlobalExceptionHandler 中,通过使用 @ExceptionHandler 注解,我们可以处理这些自定义异常,并提供相应的错误处理逻辑。这样做可以让异常处理更加模块化和可维护。
5.2 视图层技术与数据展示
5.2.1 JSP与Tiles布局的集成使用
SSH框架中视图层的搭建通常依赖于JSP(Java Server Pages)技术,它允许我们在服务器端动态生成HTML页面。为了更高效地管理和维护JSP页面,通常会使用Tiles框架来实现页面布局的复用。
Tiles框架通过定义布局模板(Tile definitions)来实现页面的可复用部分,例如页头、侧边栏、页脚等。这些布局模板可以在多个JSP页面中被引用,从而减少代码重复和提高开发效率。
在 tiles-defs.xml 文件中,我们可以定义布局模板:
<definition name="baseLayout" template="/WEB-INF/layouts/main.jsp">
<put-attribute name="header" value="/WEB-INF/includes/header.jsp" />
<put-attribute name="sidebar" value="/WEB-INF/includes/sidebar.jsp" />
<put-attribute name="body" value="" />
<put-attribute name="footer" value="/WEB-INF/includes/footer.jsp" />
</definition>
然后在具体的JSP页面中引用这个布局模板:
<%@ taglib uri="http://tiles.apache.org/tags-tiles" prefix="tiles"%>
<tiles:insert definition="baseLayout" flush="true">
<tiles:put name="body" value="/WEB-INF/pages/home.jsp" />
</tiles:insert>
通过这种方式,我们可以在 baseLayout 中定义一个通用的页面结构,然后在 home.jsp 中专注于编写具体内容,从而实现代码的复用和分离。
5.2.2 数据展示与前端框架的结合
随着前端技术的迅速发展,现代Web应用越来越倾向于将数据展示和业务逻辑分离,这可以通过使用前端框架来实现。流行的选择包括AngularJS、React和Vue.js等。这些框架与SSH框架结合使用时,可以有效地处理数据绑定、事件处理和组件化开发。
在SSH框架中,我们通常会在Controller中处理业务逻辑,并将结果数据设置到Model中。然后,这些数据可以通过Spring MVC提供的JSP标签库(如 <spring:eval> )传递到JSP页面。
<%@ taglib uri="http://www.springframework.org/tags" prefix="spring"%>
<div id="data-container">
<spring:eval expression="dataModel.dataList" var="dataList"/>
<ul>
<c:forEach items="${dataList}" var="dataItem">
<li>${dataItem.name} - ${dataItem.description}</li>
</c:forEach>
</ul>
</div>
当与前端框架结合时,数据展示变得更加动态和灵活。例如,使用AngularJS时,可以将后端传递的数据通过 ng-repeat 指令渲染到页面上:
<div id="data-container">
<ul>
<li ng-repeat="dataItem in dataList">{{ dataItem.name }} - {{ dataItem.description }}</li>
</ul>
</div>
这种方式允许前端框架动态地管理数据的渲染和交互,从而提高应用的响应速度和用户体验。
5.3 测试与性能优化
5.3.1 单元测试与集成测试的实践
对于任何软件项目,尤其是SSH框架项目,编写测试代码是确保代码质量的关键步骤。单元测试关注于最小的代码单元,通常是方法,以验证它们的行为是否符合预期。集成测试则关注于测试应用程序的多个组件或服务如何协同工作。
在SSH框架中,我们可以使用JUnit和Mockito等工具进行单元测试,同时使用TestNG或Cucumber等工具进行集成测试。例如,使用JUnit和Mockito测试Struts2 Action:
@RunWith(MockitoJUnitRunner.class)
public class UserActionTest {
@Mock
private UserService userService;
@InjectMocks
private UserAction userAction;
@Test
public void shouldReturnSuccessWhenValidUser() throws Exception {
// 创建模拟用户
User mockUser = new User("John", "Doe");
// 配置模拟行为
when(userService.getUserById(1)).thenReturn(mockUser);
// 执行操作
String result = userAction.execute();
// 验证结果
assertEquals(Action.SUCCESS, result);
verify(userService, times(1)).getUserById(1);
}
}
在集成测试中,我们可能需要模拟整个请求流程,以确保所有组件正确地协同工作。例如,使用TestNG和Mockito模拟整个Struts2请求流程:
@ContextConfiguration(locations = { "classpath:/applicationContext.xml" })
@WebAppConfiguration
public class StrutsIntegrationTest extends AbstractTransactionalJUnit4SpringContextTests {
@Autowired
private WebApplicationContext wac;
private MockHttpSession session;
private MockHttpServletRequest request;
private MockHttpServletResponse response;
@Before
public void setup() {
this.session = new MockHttpSession(wac.getServletContext());
this.request = new MockHttpServletRequest(wac.getServletContext());
this.response = new MockHttpServletResponse();
}
@Test
public void testAction() throws Exception {
request.setSession(session);
request.setMethod("POST");
request.setRequestURI("/userAction");
request.setContextPath("/myapp");
request.addParameter("id", "1");
// 初始化Struts 2
ActionProxy proxy = new ActionProxyFactory().createActionProxy("", "userAction", null, true, false);
proxy.execute();
// 验证结果
assertEquals(Action.SUCCESS, proxy.getAction().execute());
assertEquals("Expected view", proxy.getResultCode());
}
}
5.3.2 SSH框架性能监控与调优方法
随着应用程序的上线和用户量的增加,性能监控和调优成为保持应用稳定运行的重要环节。SSH框架提供了许多工具和方法来监控应用性能,比如使用JConsole、VisualVM等工具进行JVM监控,或者使用Struts2、Spring自带的性能分析工具。
例如,在Struts2中,我们可以通过 struts.xml 文件中的 <constant> 标签启用性能监控:
<constant name="struts.logDetailedStackTraces" value="true" />
<constant name="struts.configuration.xml.reload" value="true" />
这些设置将帮助我们在开发和测试阶段捕获更详细的错误信息和堆栈跟踪。
在Spring中,我们可以使用 @Profile 注解来定义不同环境下的配置,并通过 spring.profiles.active 参数来激活特定的配置文件:
@Configuration
@Profile("production")
public class ProductionConfig {
// 定义生产环境下的配置
}
通过这些配置文件,我们可以根据不同的部署环境(如开发、测试和生产环境)调整资源和数据库连接池的配置。
在生产环境中,性能调优往往关注于数据库和缓存优化、代码效率提升以及资源使用的优化。我们可以使用Spring Boot Actuator来监控应用的健康状况、指标和审计信息。此外,应用日志分析和第三方服务监控工具(如New Relic、Dynatrace)也是性能调优的有力工具。
简介:SSH框架是Java Web开发中结合Struts2、Spring和Hibernate三大开源框架的集成方案,提供了高效的MVC架构和数据库操作支持。本文章将深入探讨如何使用SSH框架执行数据库的增删改查(CRUD)操作,包括Struts2的动作处理、Spring的依赖注入和事务管理,以及Hibernate的对象关系映射能力。同时,文章会覆盖数据库连接管理、异常处理、视图层展示以及测试等关键方面,旨在帮助开发者全面理解并应用SSH框架进行高效的数据库操作和Web应用程序的构建。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









