




 本文汇总了截至2019年中旬的文本检测主流思路、解决方案及常用数据集,包括ICDAR系列数据集、MSRA-TD500等,并介绍了主流框架如Faster R-CNN、SSD、Mask R-CNN的改进模型及其在文本检测领域的应用。
本文汇总了截至2019年中旬的文本检测主流思路、解决方案及常用数据集,包括ICDAR系列数据集、MSRA-TD500等,并介绍了主流框架如Faster R-CNN、SSD、Mask R-CNN的改进模型及其在文本检测领域的应用。
1 文本检测主流思路
到2019年中旬,目前的文本检测方案汇总如下:(看不清的可以点大图)
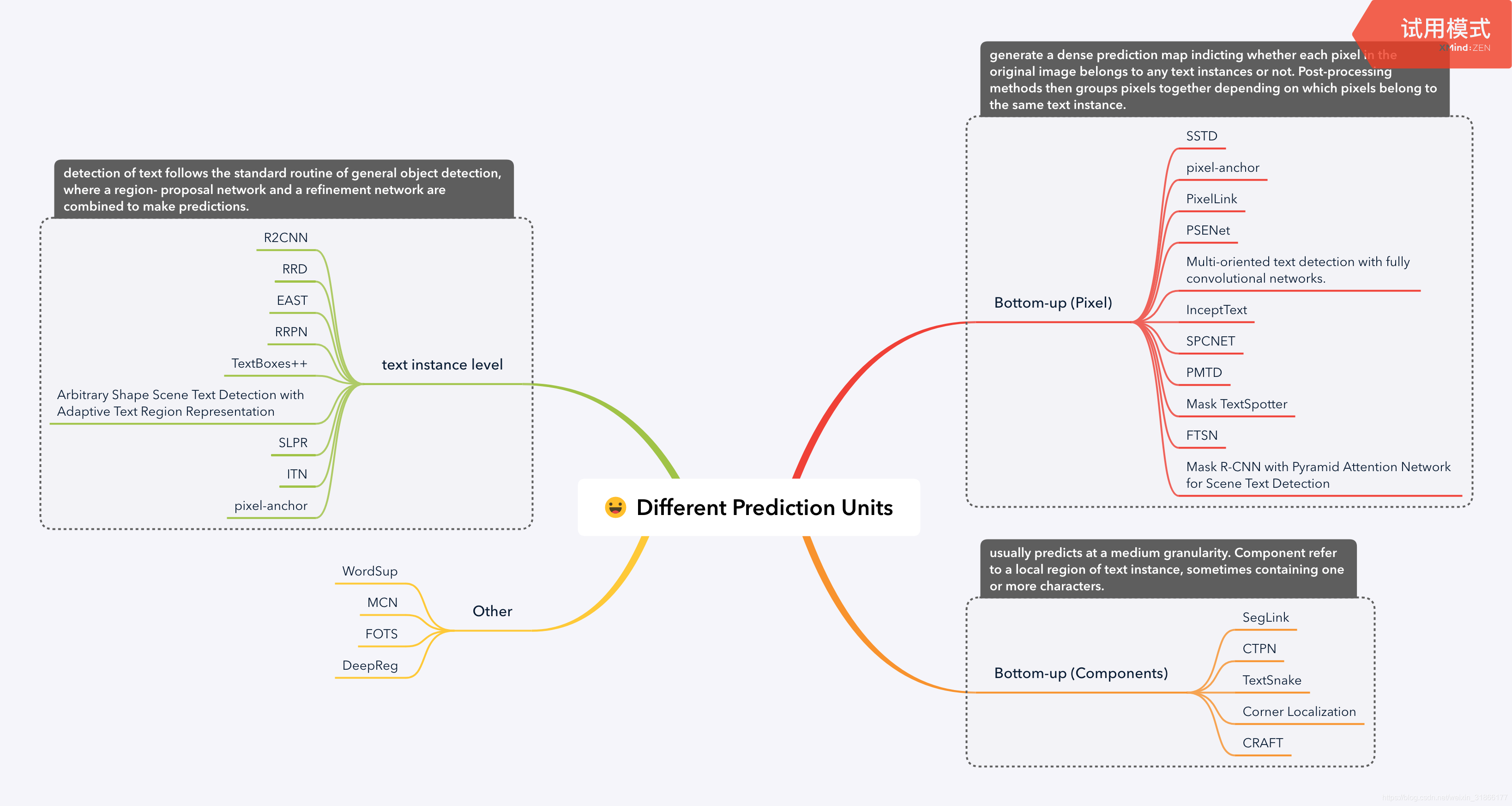
2 文本检测解决方案
含常用数据集上的检测结果


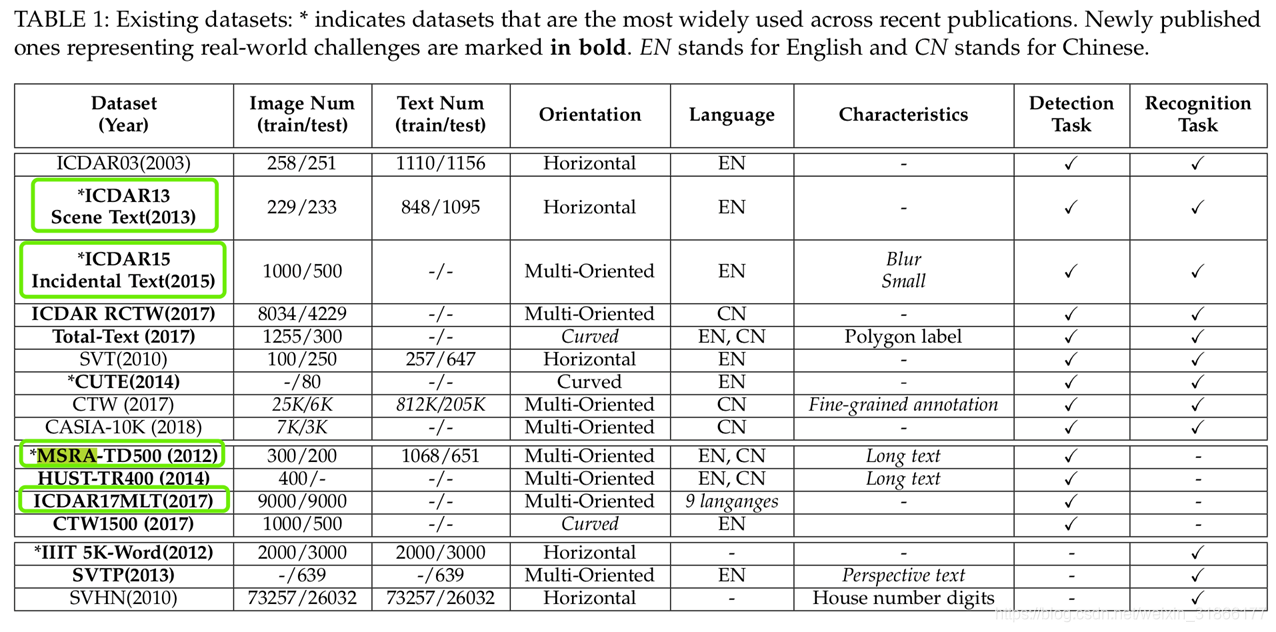
3 文本检测常用数据集介绍
Benchmark Datasets
ICDAR 2013(Focused Scene Text)(水平文本)

ICDAR2015(Incidental Scene Text)(倾斜文本)

ICDAR 2017 MLT. (主要是多语言)


现有benchmark现状
4 主流框架
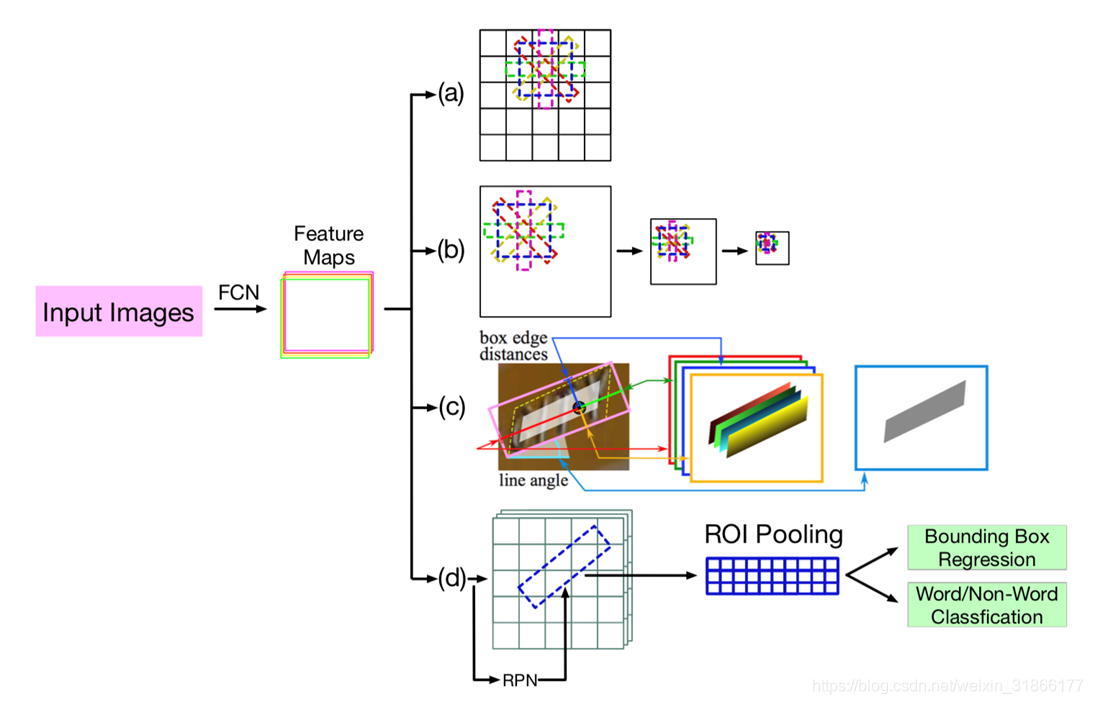
(1)anchor/roi-pooling based methods
High level illustration of existing anchor/roi-pooling based methods: (a) Similar to YOLO, predicting at each anchor positions. Representative methods include rotating default boxes. (b) Variants of SSD, including Textboxes, predicting at feature maps of different sizes. (c) Direct regression of bounding boxes, also predicting at each anchor position. (d) Region Proposal based methods, including rotating Region of Interests (RoI) and RoI of varying aspect ratios.
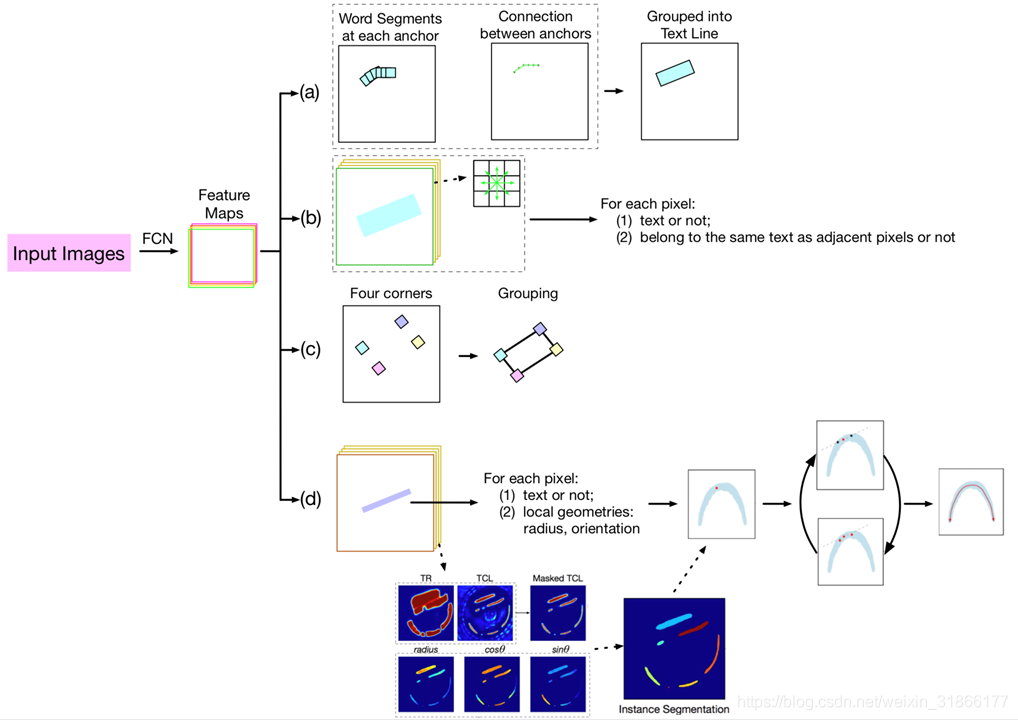
(2)bottom-up methods
Illustration of representative bottom-up methods: (a) SegLink: with SSD as base network, predict word segments at each anchor position, and connections be- tween adjacent anchors. (b) PixelLink: predict for each pixel, text/non-text classification and whether it belongs to the same text as adjacent pixels or not/ (c) Corner Localization: predict the four corners of each text and group those belonging to the same text instances. (d) TextSnake: predict text/non-text and local geometries, which are used to reconstruct text instance.
5 常用改进模型
大部分由Faster R-CNN、SSD、Mask R-CNN、FCN改进而来。
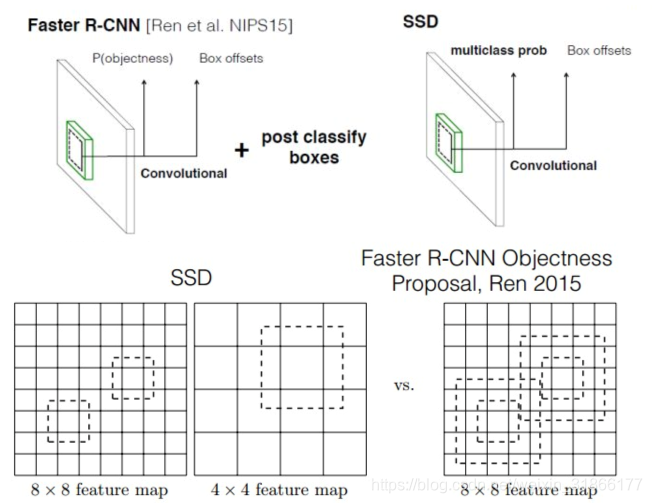
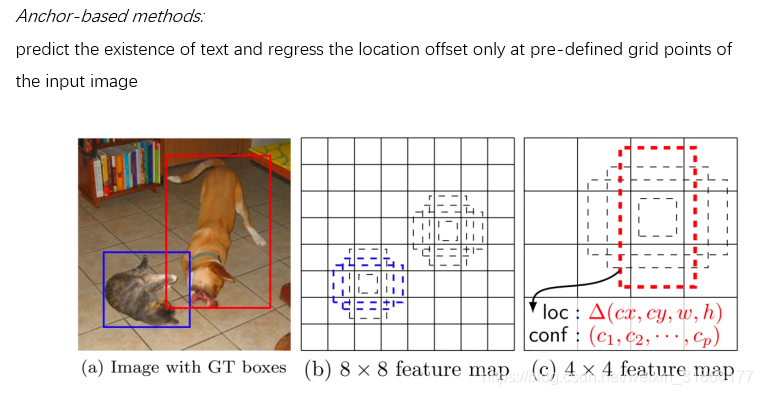
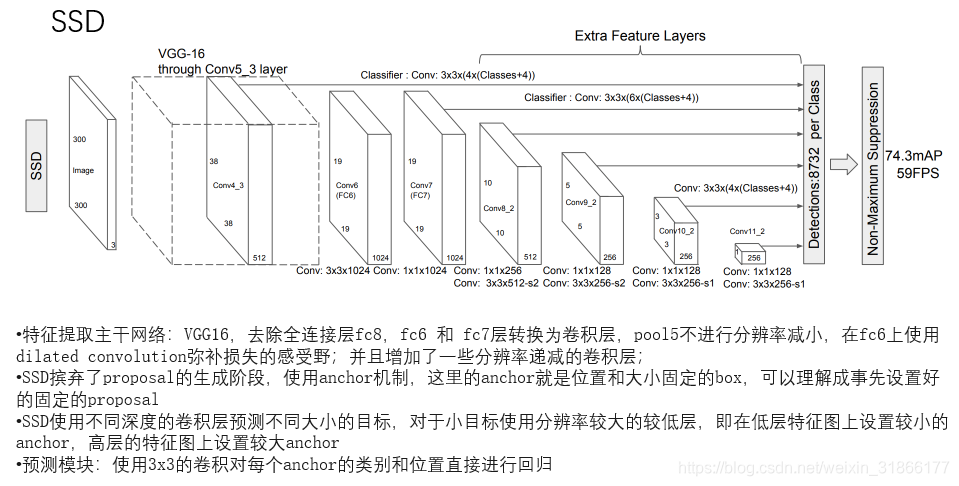
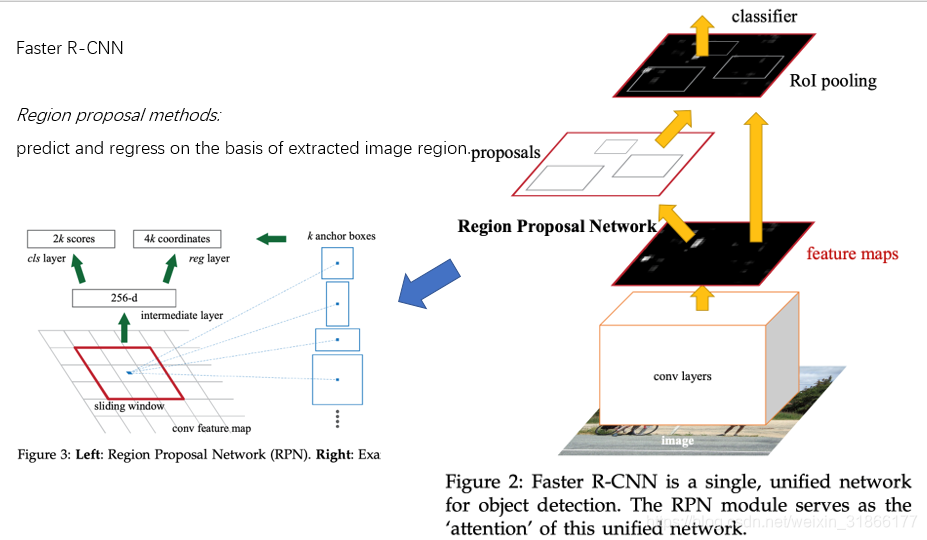
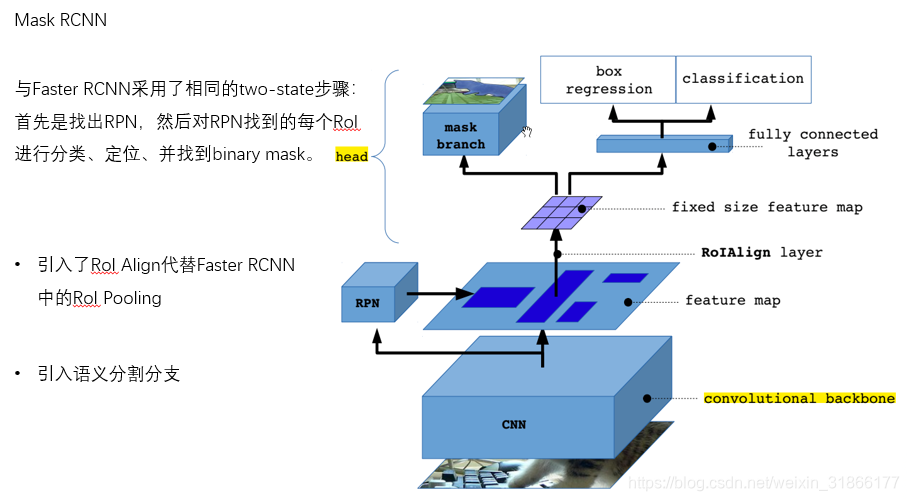
Mask RCNN是Faster RCNN的扩展,对于Faster RCNN的每个Proposal Box都要使用FCN进行语义分割,分割任务与定位、分类任务是同时进行的;
引入了RoI Align代替Faster RCNN中的RoI Pooling。因为RoI Pooling并不是按照像素一一对齐的;
引入语义分割分支,实现了mask和class预测的关系的解耦,mask分支只做语义分割,类型预测的任务交给另一个分支。
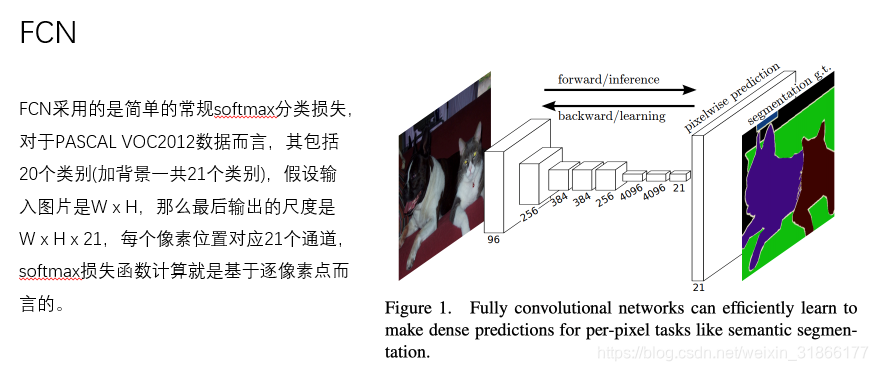
这与原本的FCN网络是不同的,原始的FCN在预测mask时还用同时预测mask所属的种类。
含对最新paper的总结
Arbitrary Shape Scene Text Detection with Adaptive Text Region Representation
Detecting Text in the Wild with Deep Character Embedding Network (CENet)
Character Region Awareness for Text Detection (CRAFT)
PMTD-Pyramid Mask Text Detector(目前baseline最高)
Scene Text Detection with Supervised Pyramid Context Network (SPCNET)
补充:
参考:
Scene Text Detection and Recognition-The Deep Learning Era
有需要的话,论文可以打包发o(* ̄▽ ̄*)ブ


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









