







CTPN的网络结构(图1):
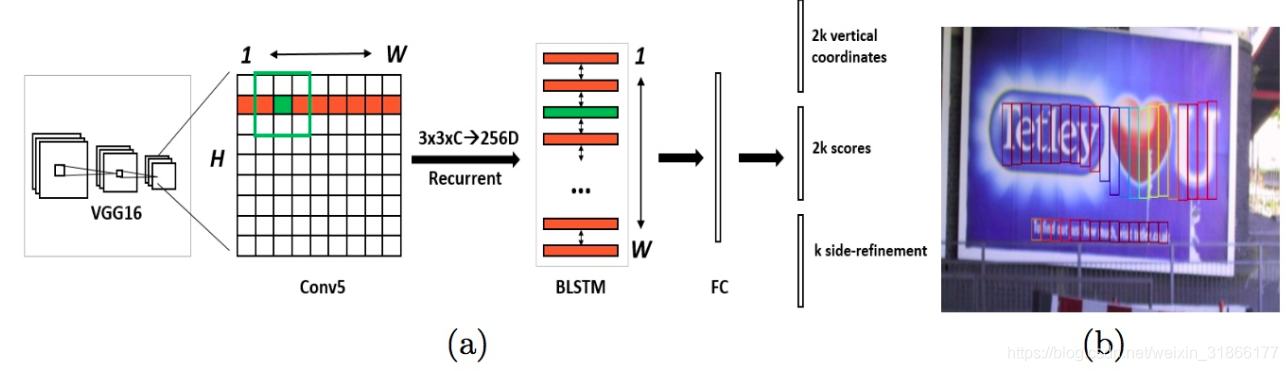
Fig. 1: (a) Architecture of the Connectionist Text Proposal Network (CTPN). We densely slide a 3×3 spatial window through the last convolutional maps (conv5) of the VGG16 model [27]. The sequential windows in each row are recurrently connected by a Bi-directional LSTM (BLSTM) [7], where the convolutional feature (3×3×C) of each window is used as input of the 256D BLSTM (including two 128D LSTMs). The RNN layer is connected to a 512D fully-connected layer, followed by the output layer, which jointly predicts text/non-text scores, y-axis coordinates and side-refinement offsets of k anchors. (b) The CTPN outputs sequential fixed-width fine-scale text proposals. Color of each box indicates the text/non-text score. Only the boxes with positive scores are presented.
整个检测分六步:
- 第一,用VGG16的前5个Conv stage(到conv5)得到feature map(W*H*C)
- 第二,在Conv5的feature map的每个位置上取3*3*C的窗口的特征,这些特征将用于预测该位置k个anchor(anchor的定义和Faster RCNN类似)对应的类别信息,位置信息。
- 第三,将每一行的所有窗口对应的3*3*C的特征(W*3*3*C)输入到RNN(BLSTM)中,得到W*256的输出
- 第四,将RNN的W*256输入到512维的fc层
- 第五,fc层特征输入到三个分类或者回归层中。第二个2k scores 表示的是k个anchor的类别信息(是字符或不是字符)。第一个2k vertical coordinate和第三个k side-refinement是用来回归k个anchor的位置信息。2k vertical coordinate表示的是bounding box的高度和中心的y轴坐标(可以决定上下边界),k个side-refinement表示的bounding box的水平平移量。这边注意,只用了3个参数表示回归的bounding box,因为这里默认了每个anchor的width是16,且不再变化(VGG16的conv5的stride是16)。回归出来的box如Fig.1中那些红色的细长矩形,它们的宽度是一定的。
- 第六,用简单的文本线构造算法,把分类得到的文字的proposal(图Fig.1(b)中的细长的矩形)合并成文本线
- 关于全卷积FC的理解:理解为什么要将全连接层转化为卷积层
转化为全卷积的两个理由,一是不用限制死输入图像的大小,提供方便。二是前向传播时效率更高。
- 问题
(1这一个格子变成了一条,5这个格子变成了一条(竖着的那个绿))
![]()
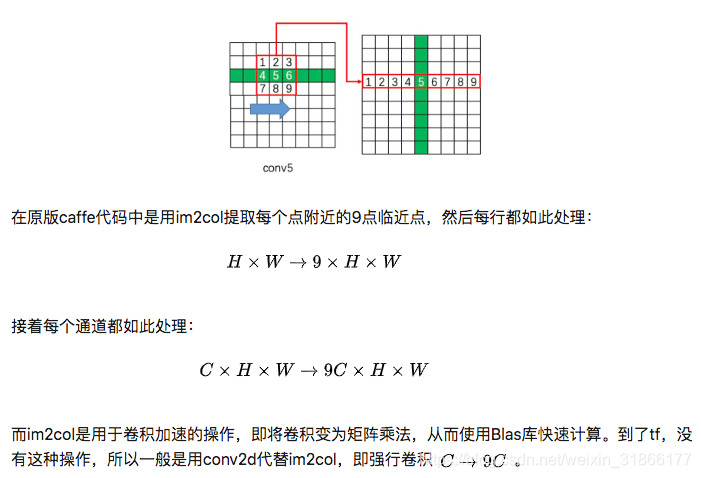
要明白三个问题(我应该还有更多要明白的?)
time-step=W,hidden_units=128,因为是bilstm所以最后得到了256d。
首先,CTPN中为何使用LSTM?
CNN学习的是感受野内的空间信息,LSTM学习的是序列特征。对于文本序列检测,显然既需要CNN抽象空间特征,也需要序列特征(毕竟文字是连续的)。
双向LSTM,当前状态,不仅可以获取之前的信息,也可以获取之后所发生的信息。
如何通过"FC"卷积层输出产生图1-b中的Text proposals?
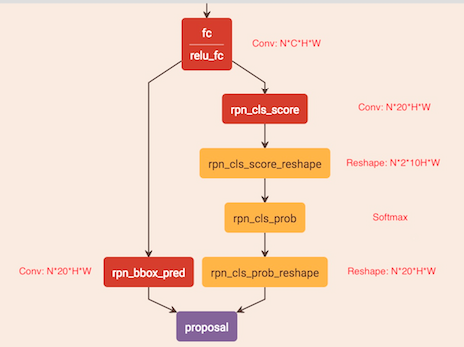
CTPN通过CNN和BiLSTM学到一组“空间 + 序列”特征后,在"FC"卷积层(全卷积)后接入RPN网络。这里的RPN与Faster R-CNN类似,分为两个分支:(回归+分类)
- 左边分支用于bounding box regression。由于fc feature map每个点配备了10个Anchor,同时只回归中心y坐标与高度2个值,所以rpn_bboxp_red有20个channels;
- 右边分支用于Softmax分类Anchor;
具体RPN网络与Faster R-CNN完全一样,所以不再介绍,只分析不同之处。
竖直Anchor定位文字位置
由于CTPN针对的是横向排列的文字检测,所以其采用了一组(10个)等宽度的Anchors,用于定位文字位置。Anchor宽高为:

同时fc与conv5 width和height都相等!!!
如图所示,CTPN为fc feature map每一个点都配备10个上述Anchors。
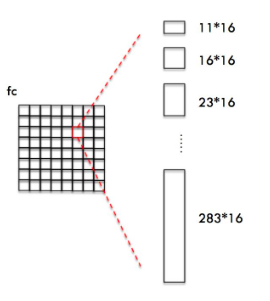
这样设置Anchors是为了:
- 保证在
 方向上,Anchor覆盖原图每个点且不相互重叠。(w:160)
方向上,Anchor覆盖原图每个点且不相互重叠。(w:160) - 不同文本在
 方向上高度差距很大,所以设置Anchors高度为11-283,用于覆盖不同高度的文本目标。
方向上高度差距很大,所以设置Anchors高度为11-283,用于覆盖不同高度的文本目标。
获得Anchor后,与Faster R-CNN类似,CTPN会做如下处理:
- Softmax判断Anchor中是否包含文本,即选出Softmax score大的正Anchor
- Bounding box regression修正包含文本的Anchor的中心y坐标与高度。
注意,与Faster R-CNN不同的是,这里Bounding box regression不修正Anchor中心x坐标和宽度。具体回归方式如下:
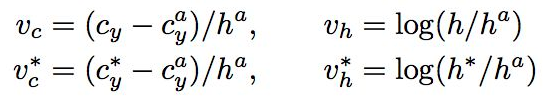
Anchor经过上述Softmax和 方向bounding box regeression处理后,会获得图Text proposal所示的一组竖直条状text proposal。后续只需要将这些text proposal用文本线构造算法连接在一起即可获得文本位置。

Text proposal
在论文中,作者也给出了直接使用Faster R-CNN RPN生成普通proposal与CTPN LSTM+竖直Anchor生成text proposal的对比,如图,明显可以看到CTPN这种方法更适合文字检测。


文本线构造算法?
在上一个步骤中,已经获得了图Text proposal所示的一串或多串text proposal,接下来就要采用文本线构造办法,把这些text proposal连接成一个文本检测框。

为了说明问题,假设某张图有上图所示的2个text proposal,即蓝色和红色2组Anchor,CTPN采用如下算法构造文本线:

下面详细解释。假设每个Anchor index如绿色数字,同时每个Anchor Softmax score如黑色数字。

举例?构造文本线(重要!)
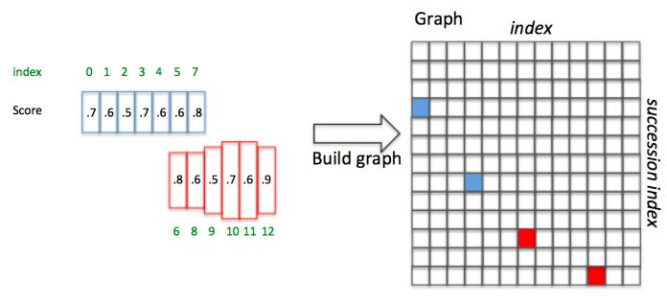
举例说明,如图10,Anchor已经按照 顺序排列好,并具有图中的Softmax score(这里的score是随便给出的,只用于说明文本线构造算法):

这样就通过Text proposals确定了文本检测框。
训练

总结
- 由于加入LSTM,所以CTPN对水平文字检测效果超级好。
- 因为Anchor设定的原因,CTPN只能检测横向分布的文字,小幅改进加入水平Anchor即可检测竖直文字。但是由于框架限定,对不规则倾斜文字检测效果非常一般。
- CTPN加入了双向LSTM学习文字的序列特征,有利于文字检测。但是引入LSTM后,在训练时很容易梯度爆炸,需要小心处理。
嘻嘻下周上班就要实际场景应用了,希望顺利吧~!
参数含义:
Anchor合并机制:
ctpn需要将每一个anchor回归的框进行合并,从而生成最终的文本框。
合并的主要原则,
(1)水平的最大连接距离为MAX_HORIZONTAL_GAP=50个像素
(2)垂直方向的一维IOU是否满足大于MIN_V_OVERLAPS=0.7比例(垂直方向)
(3)两个相邻的anchor的高度是否满足小于MIN_SIZE_SIM=0.7比例(水平方向)
然后基于上述的原则,首先从左往右扫描一遍,将满足条件的anchor合并,然后从右往左扫描一遍,将满足条件的anchor合并。
- 与真值IoU大于0.7的anchor作为正样本,与真值IoU最大的那个anchor也定义为正样本,这个时候不考虑IoU大小有没有到0.7,这样做有助于检测出小文本。(默认的anchor有很多,但是只要挑选出一定数量的正anchor,与gt的IoU重叠>0.7的anchor被称为正anchor)
- 与真值IoU小于0.5的anchor定义为负样本。
- 只保留score大于0.7的proposal,score阈值设置:0.7 (+NMS)
- 使用了双向的LSTM,每个LSTM有128个隐层
- 训练图片都将短边放缩到600像素
# text_connector/text_connect_cfg.py
class Config:
MAX_HORIZONTAL_GAP = 50
TEXT_PROPOSALS_MIN_SCORE = 0.7
TEXT_PROPOSALS_NMS_THRESH = 0.2
MIN_V_OVERLAPS = 0.7
MIN_SIZE_SIM = 0.7
MIN_RATIO = 0.5
LINE_MIN_SCORE = 0.9
TEXT_PROPOSALS_WIDTH = 16
MIN_NUM_PROPOSALS = 2
参考:
后序:
http://www.neurta.com/index.php/node/414
inception block 是为检测长文本提供更好的卷积感受野( inception block of three-scale convolutional kernels to give flexible receptive field better covering long text)。【from @RRD】
这里我记得有个1*2,2*1的卷积用来代替xxx,也是为了增大感受野吗?
主要修改:为代码添加依据验证集loss保存模型

















 5836
5836

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









