




 本文深入解析卷积神经网络(CNN)中感受野的概念,详细阐述其计算公式与影响因素,如卷积核大小、步长、填充等,并通过具体实例说明感受野在不同层间的变化,揭示了特征图上每个像素点对应原始图像区域大小的重要性。
本文深入解析卷积神经网络(CNN)中感受野的概念,详细阐述其计算公式与影响因素,如卷积核大小、步长、填充等,并通过具体实例说明感受野在不同层间的变化,揭示了特征图上每个像素点对应原始图像区域大小的重要性。
感受野
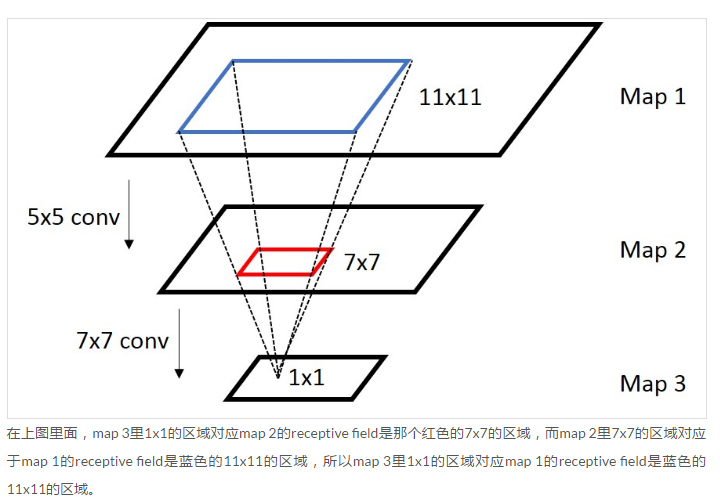
定义:CNN每一层输出的特征图上的像素点在原始图像上映射的区域大小。
(注:这里是输入图,不是原始图。好多博客写的都是原图上的区域,经过一番的资料查找,发现并不是原图。)

于是,特征图的大小逐渐变小,一个特征表示的信息量越来越大。
隐藏层边长(输出的边长) = (Input - K + 2P)/S + 1
(其中 Input是输入特征的大小,K是卷积核大小,P是填充大小,S是步长(stride))
为了理解方便我就把公式先用英文写一下:
output field size = ( input field size - kernel size + 2*padding ) / stride + 1
(output field size 是卷积层的输出,input field size 是卷积层的输入)
反过来问你: 卷积层的输入(也即前一层的感受野) = ?
答案必然是: input field size = (output field size - 1)* stride - 2*padding + kernel size
再重申一下:卷积神经网络CNN中,某一层输出结果中一个元素所对应的输入层的区域大小,被称作感受野receptive field。感受野的大小是由kernel size,stride,padding , outputsize 一起决定的。
insize = 224
def outFromIn(isz, net, layernum):#从前向后算输出维度
totstride = 1
insize = isz
for layer in range(layernum):
fsize, stride, pad = net[layer]
outsize = (insize - fsize + 2*pad) / stride + 1
insize = outsize
totstride = totstride * stride
return outsize, totstride
def inFromOut(net, layernum):#从后向前算感受野 返回该层元素在原始图片中的感受野
RF = 1
for layer in reversed(range(layernum)):
fsize, stride, pad = net[layer]
RF = ((RF -1)* stride) + fsize
return RF所以——VGG网络两个3*3相当于5*5
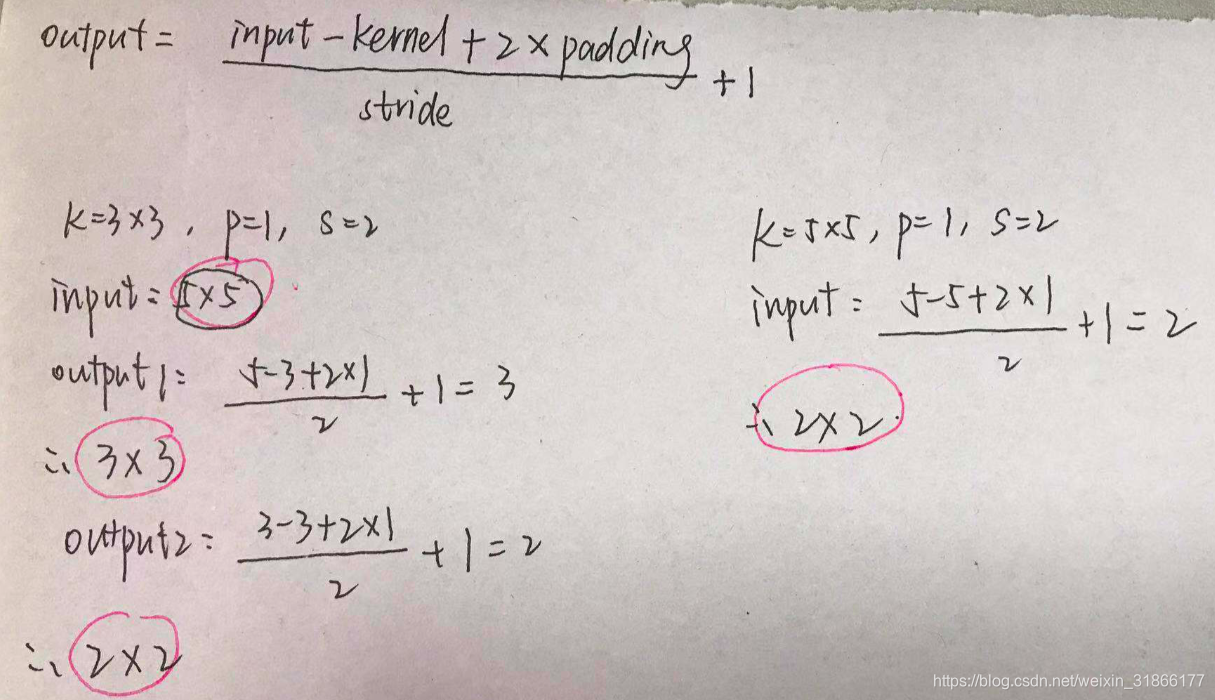
参考:
https://zhuanlan.zhihu.com/p/24780433原始图片中的ROI如何映射到到feature map?(这里含有一个坐标映射)
感受野上面的坐标映射 (Coordinate Mapping)
lallalala

















 1096
1096

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









