







 本文详细探讨了Spark中的广播变量及其原理,展示了如何通过广播变量减少内存消耗和提升网络传输效率。同时,介绍了RDD分区的概念,以及它们在任务分布和性能优化中的作用。重点讲解了使用和不使用广播变量的对比,并提供了使用注意事项,帮助开发者更好地进行Spark性能调优。
本文详细探讨了Spark中的广播变量及其原理,展示了如何通过广播变量减少内存消耗和提升网络传输效率。同时,介绍了RDD分区的概念,以及它们在任务分布和性能优化中的作用。重点讲解了使用和不使用广播变量的对比,并提供了使用注意事项,帮助开发者更好地进行Spark性能调优。
持续更新,直到写出每个环节的关系。
目录
首先了解下driver、executor、task的关系。
【spark广播】
一、使用广播变量的好处
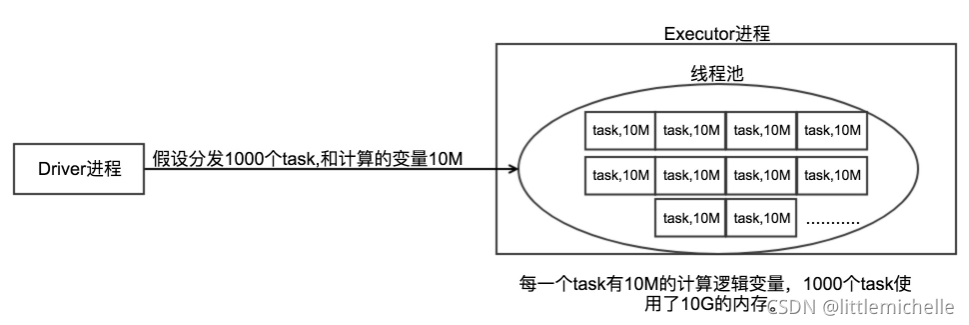
1、Driver每次分发任务的时候会把task和计算逻辑的变量发送给Executor。不使用广播变量,在每个Executor中有多少个task就有多少个Driver端变量副本。这样会导致消耗大量的内存导致严重的后果。
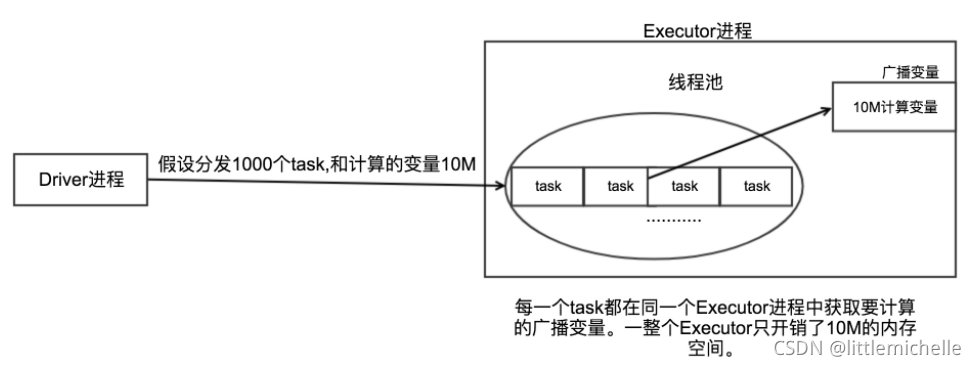
2、使用广播变量的好处,不需要每个task带上一份变量副本,而是变成每个节点的executor才一份副本。这样的话, 就可以让变量产生的副本大大减少;
二、广播变量的原理
广播变量,初始的时候,就在Drvier上有一份副本。task在运行的时候,想要使用广播变量中的数据,此时首先会在自己本地的Executor对应的BlockManager中,尝试获取变量副本;如果本地没有,那么就从Driver远程拉取变量副本,并保存在本地的BlockManager中;此后这个executor上的task,都会直接使用本地的BlockManager中的副本。executor的BlockManager除了从driver上拉取,也可能从其他节点的BlockManager上拉取变量副本。
BlockManager:负责管理某个Executor对应的内存和磁盘上的数据,尝试在本地BlockManager中找map。
三、代码中广播变量的使用
SparkContext的broadcast()方法,传入你要广播的变量:
sc.broadcast(b) // b为需要广播出去的变量;sc为SparkContext直接调用广播变量(Broadcast类型)的value() / getValue() 可以获取到之前封装的广播变量:
b.value() //b为上面广播出去的变量。四、使用广播变量和不适用广播变量的对比
(一)图对比
1、不使用广播变量
2、使用广播变量
 (二)实例说明
(二)实例说明
50个executor,1000个task。一个map,10M。 默认情况下,1000个task,1000份副本。10G的数据,网络传输,在集群中,耗费10G的内存资源。 如果使用了广播变量。50个execurtor,最多50个副本。最多500M的数据,网络传输。而且不一定都是从Driver传输到每个节点,还可能是就近从最近的节点的executor的bockmanager上拉取变量副本,网络传输速度大大增加;最多竟有500M的内存消耗。
10000M,500M,20倍。20倍~以上的网络传输性能消耗的降低;20倍的内存消耗的减少。对性能的提升和影响,还是很客观的。 虽然说,不一定会对性能产生决定性的作用。比如运行30分钟的spark作业,可能做了广播变量以后, 速度快了2分钟,或者5分钟。但是一点一滴的调优,积少成多。最后还是会有效果的。
五、使用注意事项
1、广播变量在Driver端定义
2、广播变量在Execoutor只能读取不能修改
3、广播变量的值只能在Driver端修改
4、不能将RDD广播出去,RDD不存数据,可以将RDD的结果广播出去,rdd.collect()
【spark分区】
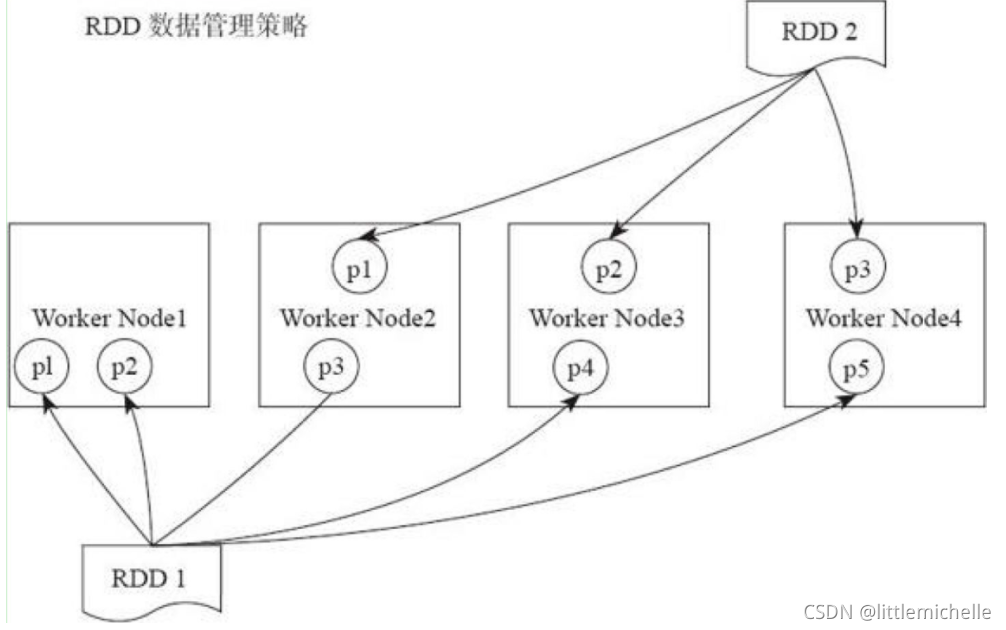
rdd作为一个分布式的数据集,是分布在多个worker节点上的。如下图所示,RDD1有五个分区(partition),他们分布在了四个worker nodes 上面,RDD2有三个分区,分布在了三个worker nodes上面。

















 1353
1353

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









