







目录
3) Spark 框架根据需求将计算逻辑根据分区划分成不同的任务
4) 调度节点将任务根据计算节点状态发送到对应的计算节点进行计算
什么是 RDD
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是 Spark 中最基本的数据处理模型。代码中是一个抽象类,它代表一个弹性的、不可变、可分区、里面的元素可并行计算的集合。
➢ 弹性
- 存储的弹性:内存与磁盘的自动切换;
- 容错的弹性:数据丢失可以自动恢复;
- 计算的弹性:计算出错重试机制;
- 分片的弹性:可根据需要重新分片。
➢ 分布式:数据存储在大数据集群不同节点上
➢ 数据集: RDD 封装了计算逻辑,并不保存数据
➢ 数据抽象: RDD 是一个抽象类,需要子类具体实现
➢ 不可变: RDD 封装了计算逻辑,是不可以改变的,想要改变,只能产生新的 RDD,在新的 RDD 里面封装计算逻辑
➢ 可分区、并行计算
执行原理
从计算的角度来讲,数据处理过程中需要计算资源(内存 & CPU)和计算模型(逻辑)。执行时,需要将计算资源和计算模型进行协调和整合。
Spark 框架在执行时,先申请资源,然后将应用程序的数据处理逻辑分解成一个一个的计算任务。然后将任务发到已经分配资源的计算节点上, 按照指定的计算模型进行数据计算。最后得到计算结果。
RDD 是 Spark 框架中用于数据处理的核心模型,在 Yarn 环境中, RDD的工作原理:
1) 启动 Yarn 集群环境
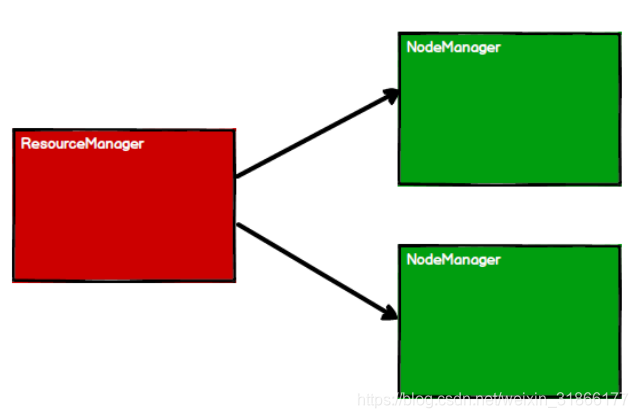
2) Spark 通过申请资源创建调度节点和计算节点

3) Spark 框架根据需求将计算逻辑根据分区划分成不同的任务
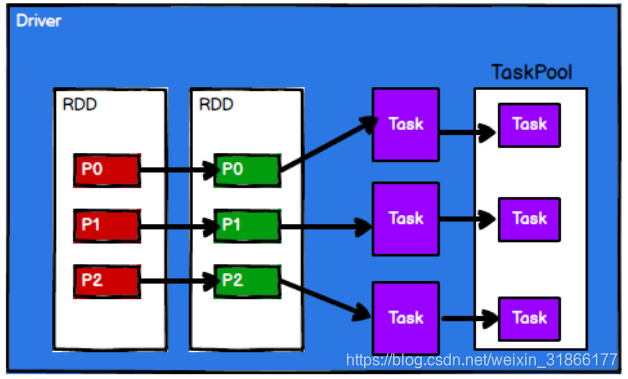
4) 调度节点将任务根据计算节点状态发送到对应的计算节点进行计算
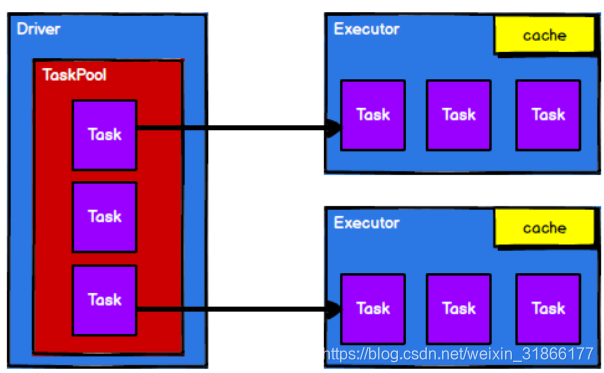
从以上流程可以看出 RDD 在整个流程中主要用于将逻辑进行封装,并生成 Task 发送给Executor 节点执行计算。

















 1719
1719

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









