






 本文介绍了如何使用Zabbix监控Linux服务器中资源使用率最高的进程。通过编写shell脚本获取服务器的CPU和内存资源使用率最大的10个进程,以JSON格式输出,并利用Zabbix自动发现功能进行监控。监控包括进程的CPU和内存使用情况,以帮助分析服务器性能瓶颈。
本文介绍了如何使用Zabbix监控Linux服务器中资源使用率最高的进程。通过编写shell脚本获取服务器的CPU和内存资源使用率最大的10个进程,以JSON格式输出,并利用Zabbix自动发现功能进行监控。监控包括进程的CPU和内存使用情况,以帮助分析服务器性能瓶颈。
监控需求
某项目的应用服务器CPU和内存使用率的监控,通过zabbix系统监控记录应用服务器上进程的CPU和内存的使用情况,并以图表的形式实时展现,以便于我们分析服务器的性能瓶颈。
监控方式
利用zabbix监控系统的自动发现功能,首先编写shell脚本获取服务器的CPU和内存资源使用率最大的进程,以json的格式输出,然后对这些进程的CPU和内存资源使用情况进行监控。(本文监控的进程为Linux服务器中资源使用率最高的10个进程。)
缺点
不适用于监控固定的进程
首先使用top命令查看进程状态,再取出进程的%CPU(该值表示单个CPU的进程从上次更新到现在的CPU时间占用百分比) 和%MEM值。hmracdb2:~ # top
top - 13:57:01 up 32 days, 5:21, 2 users, load average: 0.14, 0.26, 0.34
Tasks: 206 total, 1 running, 205 sleeping, 0 stopped, 0 zombie
Cpu(s): 3.7%us, 2.7%sy, 0.0%ni, 87.2%id, 6.3%wa, 0.0%hi, 0.1%si, 0.0%st
Mem: 3926096k total, 3651612k used, 274484k free, 788120k buffers
Swap: 4193276k total, 1369968k used, 2823308k free, 1443884k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
2365 root 20 0 854m 315m 12m S 3 8.2 1252:49 ohasd.bin
5307 oracle 20 0 1783m 22m 22m S 3 0.6 1106:03 oracle
4532 root 20 0 676m 31m 13m S 2 0.8 853:35.32 crsd.bin
4272 grid RT 0 437m 282m 52m S 2 7.4 1006:47 ocssd.bin
5279 oracle 20 0 1771m 60m 48m S 2 1.6 477:11.19 oracle
5122 oracle 20 0 654m 15m 12m S 1 0.4 537:40.85 oraagent.bin
由于top是交互的命令,我们把top命令的结果输出到一个文件上
hmracdb2:~ # top -b -n 1 > /tmp/.top.txt
第一个脚本,获取监控进程内存资源占有率前10的进程,输出格式为json格式,用于zabbix自动发现进程# cat discovery_process.sh
#!/bin/bash
#system process discovery script
top -b -n 1 > /tmp/.top.txt && chown zabbix. /tmp/.top.txt
proc_array=(`tail -n +8 /tmp/.top.txt | awk '{a[$NF]+=$10}END{for(k in a)print a[k],k}'|sort -gr|head -10|cut -d" " -f2`)
length=${#proc_array[@]}
printf "{\n"
printf '\t'"\"data\":["
for ((i=0;i
do
printf "\n\t\t{"
printf "\"{#PROCESS_NAME}\":\"${proc_array[$i]}\"}"
if [ $i -lt $[$length-1] ];then
printf ","
fi
done
printf "\n\t]\n"
printf "}\n"
或者# cat discovery_process2.sh
#!/bin/bash
#system process discovery script
top -b -n 1 > /tmp/.top.txt && chown zabbix. /tmp/.top.txt
proc_array=`tail -n +8 /tmp/.top.txt | awk '{a[$NF]+=$10}END{for(k in a)print a[k],k}'|sort -gr|head -10|cut -d" " -f2`
length=`echo "${proc_array}" | wc -l`
count=0
echo '{'
echo -e '\t"data":['
echo "$proc_array" | while read line
do
echo -en '\t\t{"{#PROCESS_NAME}":"'$line'"}'
count=$(( $count + 1 ))
if [ $count -lt $length ];then
echo ','
fi
done
echo -e '\n\t]'
echo '}'
输出的效果如下[root@Zabbix_19F ~]# ./discovery_process.sh
{
"data":[
{"{#PROCESS_NAME}":"mysqld"},
{"{#PROCESS_NAME}":"php-fpm"},
{"{#PROCESS_NAME}":"zabbix_server"},
{"{#PROCESS_NAME}":"nginx"},
{"{#PROCESS_NAME}":"sshd"},
{"{#PROCESS_NAME}":"bash"},
{"{#PROCESS_NAME}":"zabbix_agentd"},
{"{#PROCESS_NAME}":"qmgr"},
{"{#PROCESS_NAME}":"pickup"},
{"{#PROCESS_NAME}":"master"}
]
}
第二个脚本,用于zabbix监控的具体监控项目(item)的key,通过脚本获取第一个脚本自动发现的进程的CPU和内存的具体使用情况与使用率。#!/bin/bash
#system process CPU&MEM use information
#mail: mail@huangming.org
mode=$1
name=$2
process=$3
mem_total=$(cat /proc/meminfo | grep "MemTotal" | awk '{printf "%.f",$2/1024}')
cpu_total=$(( $(cat /proc/cpuinfo | grep "processor" | wc -l) * 100 ))
function mempre {
mem_pre=`tail -n +8 /tmp/.top.txt | awk '{a[$NF]+=$10}END{for(k in a)print a[k],k}' | grep "\b${process}\b" | cut -d" " -f1`
echo "$mem_pre"
}
function memuse {
mem_use=`tail -n +8 /tmp/.top.txt | awk '{a[$NF]+=$10}END{for(k in a)print a[k]/100*'''${mem_total}''',k}' | grep "\b${process}\b" | cut -d" " -f1`
echo "$mem_use" | awk '{printf "%.f",$1*1024*1024}'
}
function cpuuse {
cpu_use=`tail -n +8 /tmp/.top.txt | awk '{a[$NF]+=$9}END{for(k in a)print a[k],k}' | grep "\b${process}\b" | cut -d" " -f1`
echo "$cpu_use"
}
function cpupre {
cpu_pre=`tail -n +8 /tmp/.top.txt | awk '{a[$NF]+=$9}END{for(k in a)print a[k]/('''${cpu_total}'''),k}' | grep "\b${process}\b" | cut -d" " -f1`
echo "$cpu_pre"
}
case $name in
mem)
if [ "$mode" = "pre" ];then
mempre
elif [ "$mode" = "avg" ];then
memuse
fi
;;
cpu)
if [ "$mode" = "pre" ];then
cpupre
elif [ "$mode" = "avg" ];then
cpuuse
fi
;;
*)
echo -e "Usage: $0 [mode : pre|avg] [mem|cpu] [process]"
esac
我们先来查看一下当前系统的内存和CPU大小情况:-- 内存
[root@Zabbix_19F ~]# cat /proc/meminfo | grep "MemTotal" | awk '{printf "%.f",$2/1024}'
3832
-- CPU
[root@Zabbix_19F ~]# cat /proc/cpuinfo | grep "processor" | wc -l
8
执行脚本运行效果如下(获取监控项key值)[root@Zabbix_19F ~]# ./process_check.sh avg mem mysqld #输出mysqld进程使用的内存(计算公式:3832*18.5/100)
708.92
[root@Zabbix_19F ~]# ./process_check.sh pre mem mysqld #输出mysqld进程内存的使用率
18.5
[root@Zabbix_19F ~]# ./process_check.sh avg cpu mysqld #单个CPU的mysqld进程使用率
3.9
[root@Zabbix_19F ~]# ./process_check.sh pre cpu mysqld #所有CPU的mysqld进程的使用率
0.004875
配置zabbix_agentd,在agentd客户端的etc/zabbix_agentd.conf中增加userparameter配置,增加进程自动发现的key,和进程资源检测的key。hmracdb2:/opt/zabbix # vim etc/zabbix_agentd.conf.d/userparameter_script.conf
UserParameter=discovery.process,/opt/zabbix/scripts/discovery_process.sh
UserParameter=process.check[*],/opt/zabbix/scripts/process_check.sh $1 $2 $3
配置完之后重启agentd服务hmracdb2:/opt/zabbix # service zabbix_agentd restart
Shutting down zabbix_agentd done
Starting zabbix_agentd done
在zabbix服务器端手动获取监控项key值数据[root@Zabbix_19F ~]# zabbix_get -p10050 -k 'discovery.process' -s 10.xxx.xxx.xxx
{
"data":[
{"{#PROCESS_NAME}":"ohasd.bin"},
{"{#PROCESS_NAME}":"ocssd.bin"},
{"{#PROCESS_NAME}":"oracle"},
{"{#PROCESS_NAME}":"oraagent.bin"},
{"{#PROCESS_NAME}":"crsd.bin"},
{"{#PROCESS_NAME}":"orarootagent.bi"},
{"{#PROCESS_NAME}":"watchdog/3"},
{"{#PROCESS_NAME}":"watchdog/2"},
{"{#PROCESS_NAME}":"watchdog/1"},
{"{#PROCESS_NAME}":"watchdog/0"}
]
}
[root@Zabbix_19F ~]# zabbix_get -p10050 -k 'process.check[pre,mem,oracle]' -s 10.xxx.xxx.xxx
2.9
[root@Zabbix_19F ~]# zabbix_get -p10050 -k 'process.check[avg,mem,oracle]' -s 10..xxx.xxx.xxx
111.186
[root@Zabbix_19F ~]# zabbix_get -p10050 -k 'process.check[avg,cpu,oracle]' -s 10..xxx.xxx.xxx
4
[root@Zabbix_19F ~]# zabbix_get -p10050 -k 'process.check[pre,cpu,oracle]' -s 10..xxx.xxx.xxx
0.01
配置完agentd后,在zabbix服务器配置Web端的模版与监控项目item
Configuration --> Templates --> Create template -->
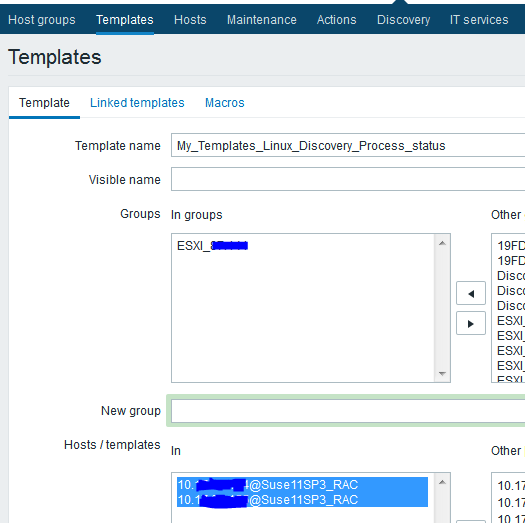
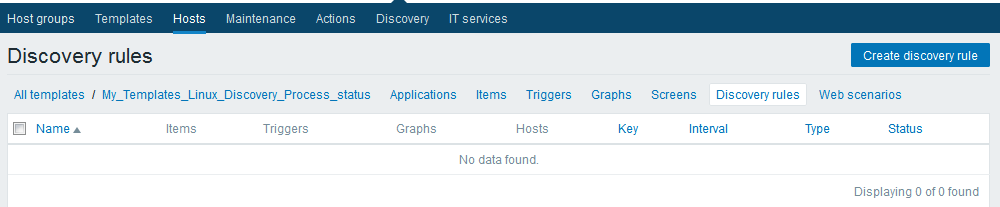
创建完模版之后,添加自动发现规则
Discovery rules -->Create discovesy rule
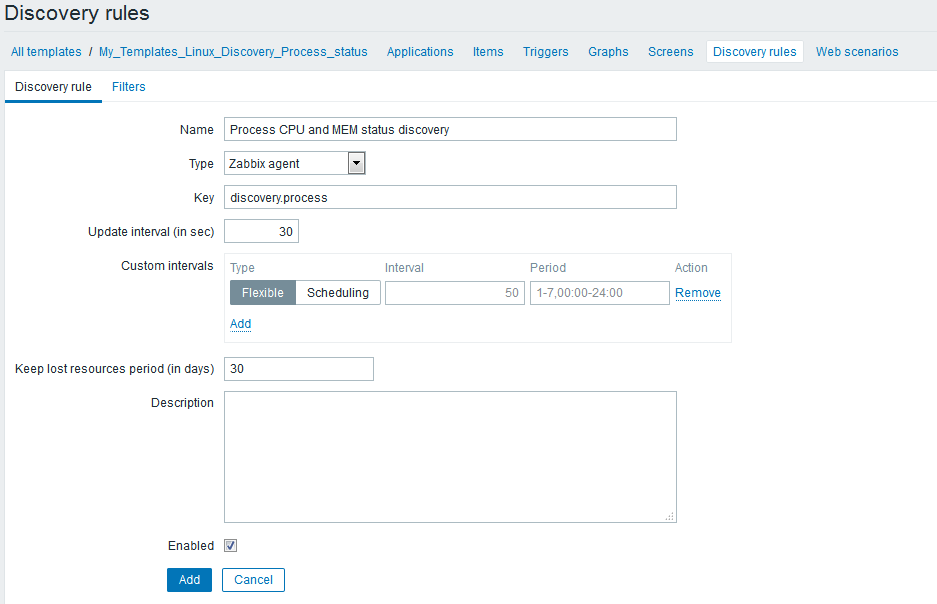
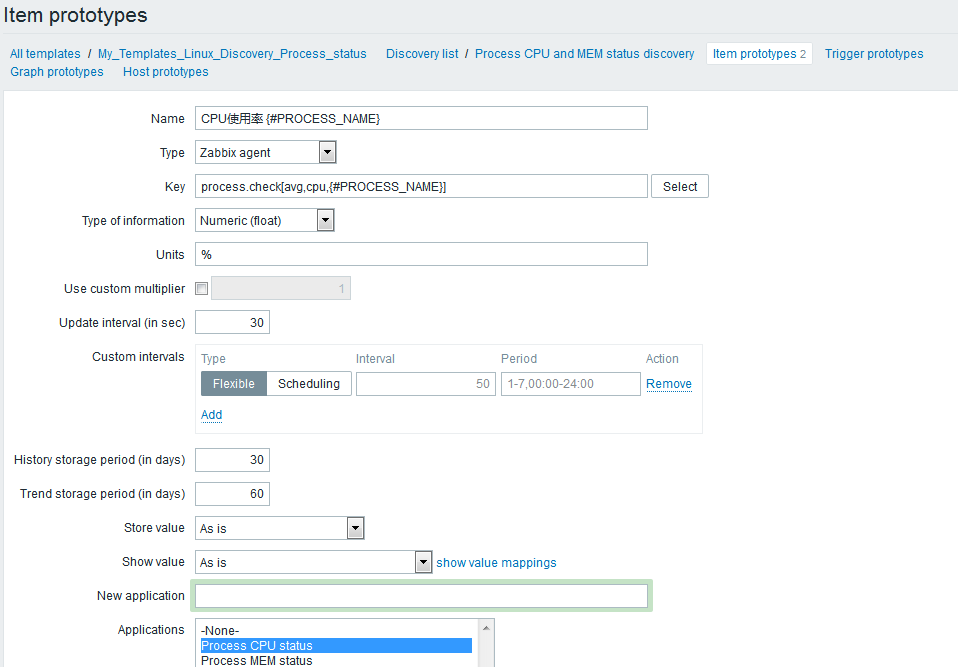
Item prototypes--> Create item prototype
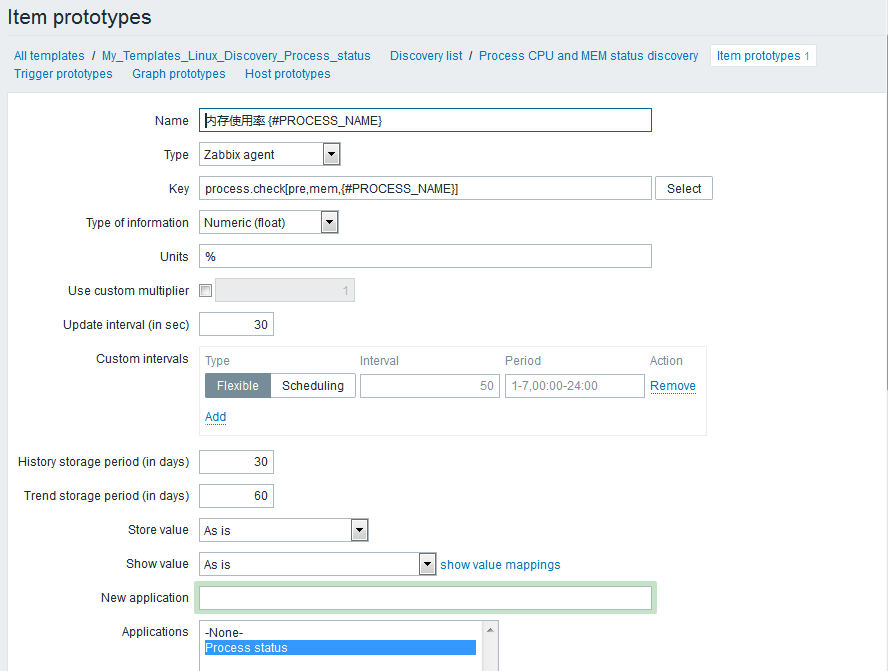
也可以继续添加监控的主机和所需监控项,添加完后我们可以查看下监控的历史数据
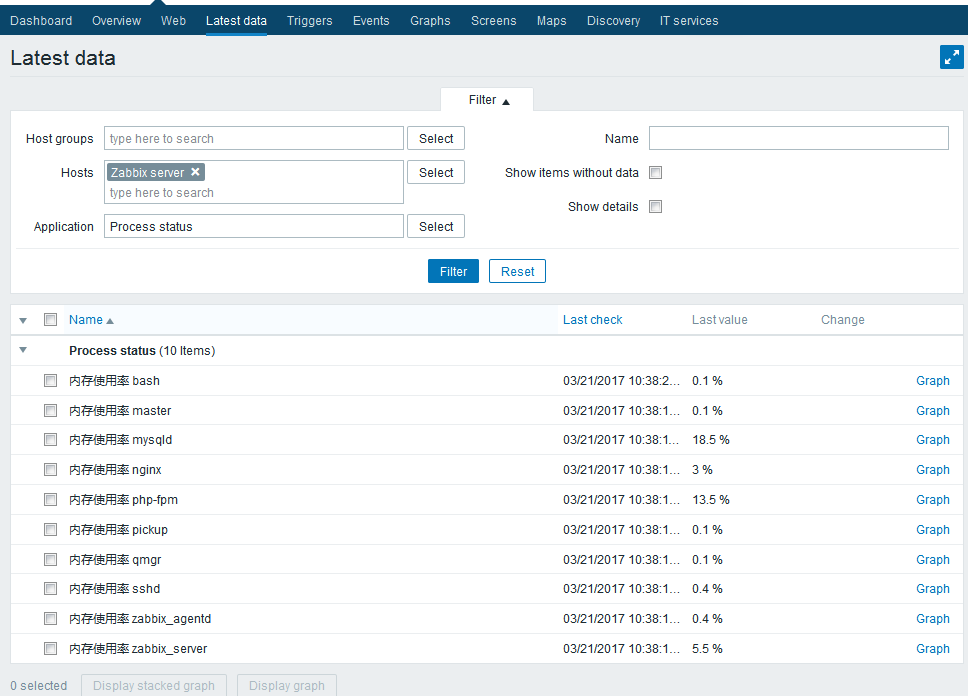
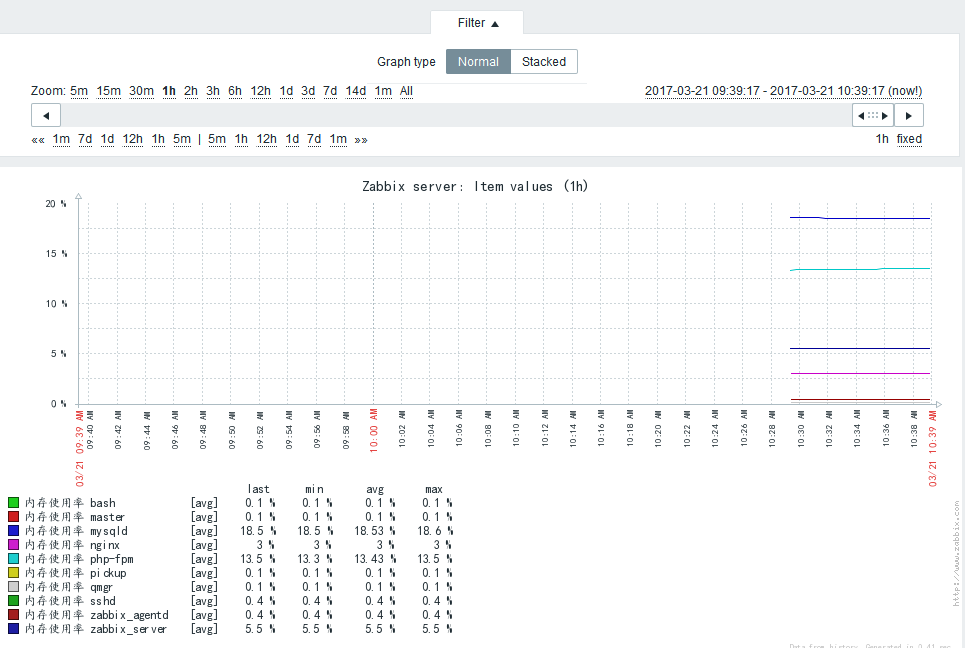
添加一个进程的CPU使用率的监控项
查看历史数据
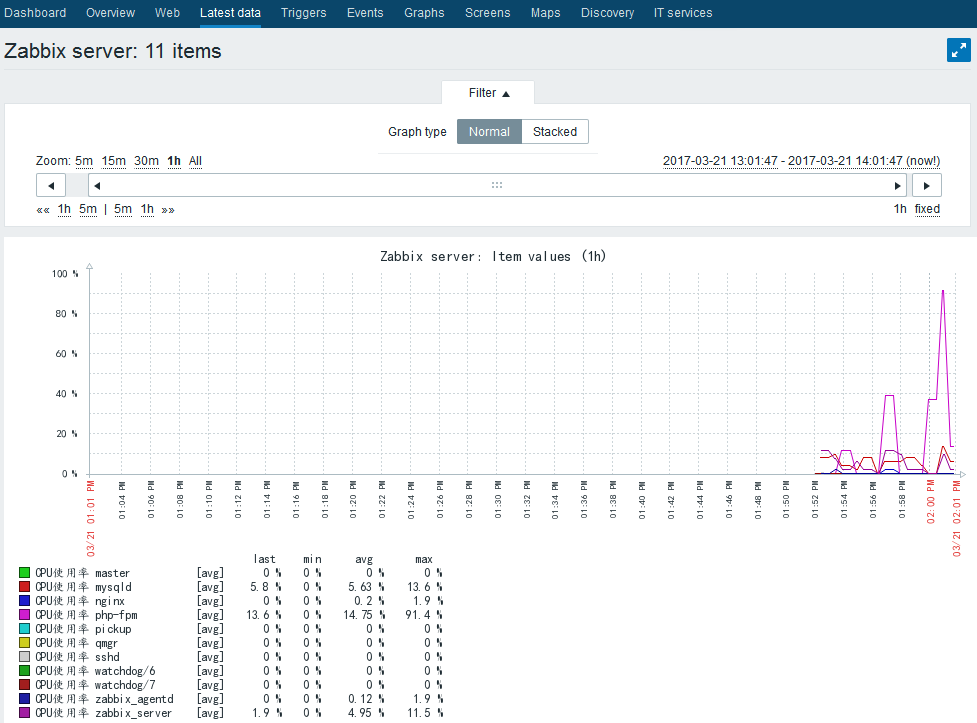
当然还可以获取进程内存使用的具体大小情况
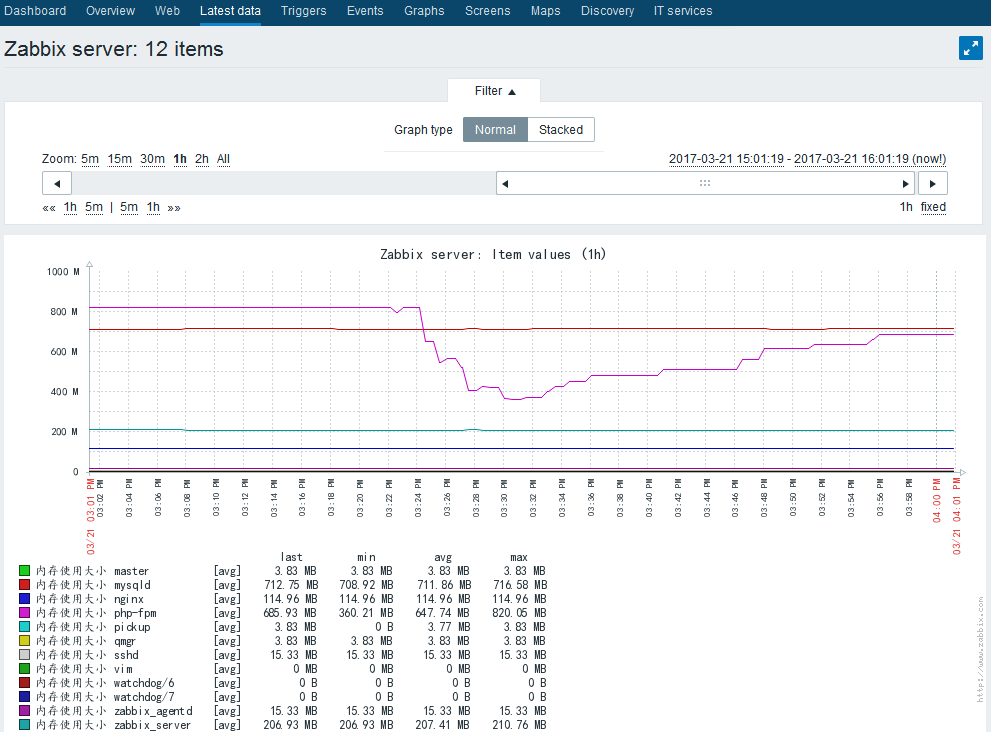
至此,zabbix自动发现进程内存和CPU使用情况并实时监控配置就完成了

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









