






 本文介绍了Ubuntu下软链接和硬链接的创建及其区别,强调软链接可跨文件系统并允许对不存在文件名的链接。此外,文章还详细讲解了CUDA的编译流程和兼容性,以及如何创建文件夹、查看包安装位置和管理进程。CUDA的兼容性涉及虚拟架构和真实架构的概念,确保程序在不同GPU上运行。
本文介绍了Ubuntu下软链接和硬链接的创建及其区别,强调软链接可跨文件系统并允许对不存在文件名的链接。此外,文章还详细讲解了CUDA的编译流程和兼容性,以及如何创建文件夹、查看包安装位置和管理进程。CUDA的兼容性涉及虚拟架构和真实架构的概念,确保程序在不同GPU上运行。
1、为文件夹建立软链接
ubuntu创建软链接类似windows下创建快捷方式,建立命令
ln -s source dist
source:文件原始地址
dist:文件想要建立链接的位置
软链接与硬链接的区别(通俗):
硬链接可认为是一个文件拥有两个文件名;而软链接则是系统新建一个链接文件,此文件指向其所要指的文件。
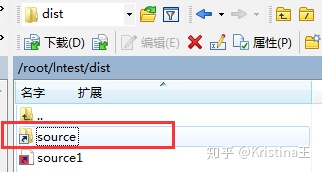
例如:
ln -s /root/lntest/source/ /root/lntest/dist/
这里看到软链就是个快捷方式。
软链接与硬链接的区别(讲解):
对于一个文件来说,有唯一的索引接点与之对应,而对于一个索引接点号,却可以有多个文件名与之对应。因此,在磁盘上的同一个文件可以通过不同的路径去访问该文件。
连接有软连接和硬连接(hard link)之分的,软连接(symbolic link)又叫符号连接。符号连接相当于Windows下的快捷方式。
不可以对文件夹建立硬连接的,我们通常用的还是软连接比较多。
eg:
ln -s source dist # 建立软连接
ln -s /mnt/hgfs/ /home/luo/ 注意后面的“/” 是将目录里所有的文件链接过去,必须加上,否则,建立的目录显示颜色异常,还不能正常访问,如cd 进不去
ln source dist # 建立硬连接
软链接实际上只是一段文字,里面包含着它所指向的文件的名字,系统看到软链接后自动跳到对应的文件位置处进行处理;相反,硬联接为文件开设一个新的目录项,硬链接与文件原有的名字是平权的,在Linux看来它们是等价的。由于这个原因,硬链接不能连接两个不同文件系统上的文件。
(1)软连接可以 跨文件系统 ,硬连接不可以。
(2)关于 I节点的问题 。硬连接不管有多少个,都指向的是同一个I节点,会把 结点连接数增加,只要结点的连接数不是 0,文件就一直存在,不管你删除的是源文件还是 连接的文件 。只要有一个存在 ,文件就 存在 (其实也不分什么源文件连接文件的 ,因为他们指向都是同一个 I节点)。 当你修改源文件或者连接文件任何一个的时候 ,其他的文件都会做同步的修改。软链接不直接使用i节点号作为文件指针,而是使用文件路径名作为指针。所以 删除连接文件 对源文件无影响,但是删除源文件,连接文件就会找不到要指向的文件 。软链接有自己的inode,并在磁盘上有一小片空间存放路径名.
(3)软连接可以对一个不存在的文件名进行连接 。
(4)软连接可以对目录进行连接。
参考来源:
Linux ln命令 - 建立文件/目录链接www.linuxidc.com
2、创建文件夹各参数选择命令
(1)输入命令:mkdir music,创建文件夹 music;
(2)输入命令:mkdir a1 a2 a3,批量创建文件夹 a1、文件夹 a2、文件夹 a3;
(3)输入命令:mkdir -p b1/b2/b3,连续创建文件夹 b1、文件夹 b2、文件夹 b3;也即,为b1创建子文件夹b2, 为b2创建子文件夹b3。

【总结】
- mkdir xxx 创建文件夹xxx
- mkdir a1 a2 a3 批量创建文件夹 a1、文件夹 a2、文件夹 a3
- mkdir -p b1/b2/b3 连续创建文件夹 b1、文件夹 b2、文件夹 b3
参考来源:https://blog.youkuaiyun.com/sunnyzyq/article/details/87930448
你一定要知道的关于Linux文件目录操作的12个常用命令 - angelling - 博客园www.cnblogs.com
mkdir命令
mkdir用来创建指定名称的目录,要求创建目录的用户在当前目录中具有写权限,并且指定的目录名不能是当前目录中已有的目录。
(1) 命令格式:mkdir [选项] 目录
(2) 命令功能:在指定位置创建指定文件名命名的文件夹或目录,要创建文件夹或目录的用户必须对所创建的文件夹的父文件夹具有写权限,且同一个目录下不能有重名的。
(3) 命令参数:
-m,--mode模式 设定权限<模式>(类似chmod),而不是rwxrwxrwx
-p,--parents可以是一个路径的名称,此时若路径中的某些目录不存在,加上此选项后系统将自动建立好那些尚不存在的目录,即一次可以建立多个目录
-v,--verbose创建当前新目录或文件时显示信息,如“已创建目录test6”
【删除文件夹命令】
强制删除并提示
sudo rm -r 文件夹名强制删除不提示
sudo rm -rf 文件夹名-r表示强制删除,-f表示不提示
【服务器之间的文件传输】
scp -r 文件名 远程服务器名{at}服务器地址:要上传到的文件路径
解压:unzip FileName.zip
压缩:zip FileName.zip DirName
可参考:
https://blog.youkuaiyun.com/lthirdonel/article/details/80076465
3、CUDA:NVCC编译过程和兼容性详解
Matching SM architectures (CUDA arch and CUDA gencode) for various NVIDIA cards
编译流程
CUDA编译阶段将源文件中包含C++ externed(cuda 相关代码)的内容变换到标准的C++代码,然后交给c++编译器进行进一步的编译和链接。
CUDA编译的工作原理如下:输入程序首先被设备编译器(nvcc)编译即在设备编译器(nvcc)预处理过程,并将CUDA相关代码(主要是核函数)编译为放置在fatbinary中的CUDA二进制(Cubin)和/或PTX中间代码,并将CUDA特定的C ++扩展转换为标准C ++构造合成嵌入fatbinary。
可以看到,编译过程其实分两部分,一部分是主机端和普通c++一样的编译,另一部分是针对CUDA中扩展的C++程序的编译,设备端的编译最终的结果文件为fatbinary文件,GPU(的驱动)通过fatbinary文件来执行GPU功能。
[Note]:
为了让应用程序适应不同的GPU,fatbinary里可能会有多种GPU的实现,程序在运行的时候会根据自己的特点选择合适的最高效的GPU实现进行运行:
CUDA 运行时系统(GPU驱动程序)会监视fatbinary文件中的内容,每次程序运行时,CUDA 运行时系统(GPU驱动程序)都会找到fatbinary中最合适部分并映射到当前GPU。(fatbinary会有适合不同的GPU的实现)
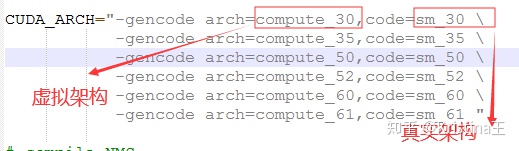
一些基础知识
GPU的“代”
GPU有个重要参数,计算能力,计算能力的值对应GPU的“代”值,如计算能力3.0,对应的“代”为sm_30,也对应kepler架构。
(注:实际中的结论,compute_30以上的程序,计算能力高的GPU可以运行编译成低代的程序,反之则不行,如计算能力6.1的GPU可以运行编译成compute_30,sm_30的程序)
GPU的小“代”
除了sm_20,sm_30,sm_50,sm_60这些大的代号,还有sm_21, sm_35, sm_53 ,sm_61这些小代,这些小代不会做大的改变,会有一些小的调整,如调整寄存器和处理器集群的数量,这只影响执行性能,不会改变功能。程序更精确的对应GPU代号可能可以达到最佳性能。
应用程序的兼容性
nvcc依靠两阶段编译模型来确保应用程序与未来GPU世代的兼容性。
即虚拟架构和真实架构:
虚拟架构确定编译成的代号的功能,真实架构确定编译成的真实代号的功能和性能。
虚拟框架由compute_开头。
虚拟架构通常是从大的GPU代上控制的,真实框架必须大于等于虚拟框架,真实框架对应真正运行的GPU,即编译阶段就确定要运行的GPU是什么。真实框架由sm_开头。
提高兼容性的方式
编译阶段本身无助于实现与未来GPU应用兼容的目标。 为此,我们需要其他两种机制:即时编译(JIT)和fatbinaries。
CUDA程序兼容性
CUDA程序的兼容性,是要在编译时就要决定和设计好的,为了让程序在编译时保证让所有GPU都可以更好的运行,这里给出方案:
JIT和fatbinaryies只能解决每一代的问题,使用-generate arch,可解决所有代的问题。其具体实现命令将在CUDA:nvcc编译参数示例详细描述。
总结
- CUDA程序的编译必须经历两个过程,即虚拟框架和真实框架,虚拟框架决定了程序最小的可运行GPU框架,而真实框架决定了程序可运行的最小的实际GPU。 例如-arch=compute_30;-code=sm_30表示计算能力3.0及以上的GPU都可以运行编译的程序。但计算能力2.0的GPU就不能运行了。
- 即时编译(Just-In-Time)机制让程序可以在大的GPU框架内动态选择与电脑GPU最合适的小代。
- –generate-code保证用户GPU可以动态选择最适合的GPU框架(最适合GPU的大代和小代)。
参考来源:
Matching SM architectures (CUDA arch and CUDA gencode) for various NVIDIA cards - Blame Arnonarnon.dk
4、重启服务器
如下图所示,即使没有使用运行任何程序,但是nvidia-smi查看GPU-Util 达到99%。
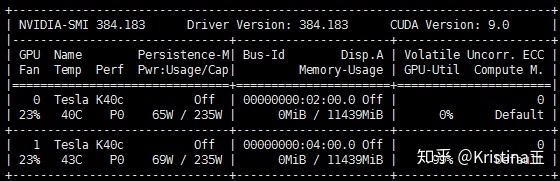
所以需要重启服务器尝试解决。
5、ln -s 命令
ln是linux中又一个非常重要命令,它的功能是为某一个文件在另外一个位置建立一个同步的链接.当我们需要在不同的目录,用到相同的文件时,我们不需要在每一个需要的目录下都放一个必须相同的文件,我们只要在某个固定的目录,放上该文件,然后在 其它的目录下用ln命令链接(link)它就可以,不必重复的占用磁盘空间。
这个命令最常用的参数是-s,具体用法是:ln -s 源文件 目标文件
这 里有两点要注意:第一,ln命令会保持每一处链接文件的同步性,也就是说,不论你改动了哪一处,其它的文件都会发生相同的变化;第二,ln的链接又软链接 和硬链接两种,软链接就是ln -s ** **,它只会在你选定的位置上生成一个文件的镜像,不会占用磁盘空间,硬链接ln ** **,没有参数-s, 它会在你选定的位置上生成一个和源文件大小相同的文件,无论是软链接还是硬链接,文件都保持同步变化。
如果你用ls察看一个目录时,发现有的文件后面有一个@的符号,那就是一个用ln命令生成的文件,用ls -l命令去察看,就可以看到显示的link的路径了。
参考:https://blog.youkuaiyun.com/qq_40625030/article/details/79907795
6、Ubuntu查看包安装位置
方法一:pip show 包名
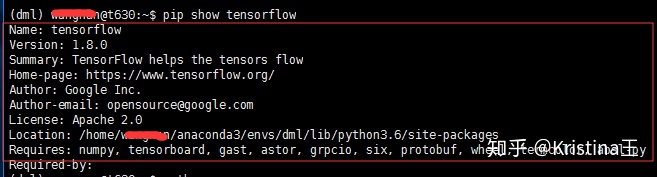
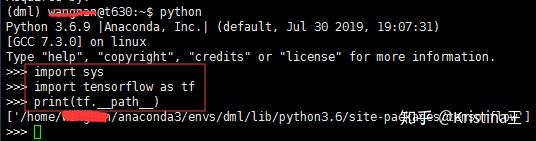
方法二:(以tensorflow包名为例)
python
import sys
import tensorflow as tf
print(tf.__path__)
7、Ubuntu下查看CUDA和CUDNN版本的方法
cuda 版本cat /usr/local/cuda/version.txt
cudnn 版本cat /usr/local/cuda/include/cudnn.h | grep CUDNN_MAJOR -A 2
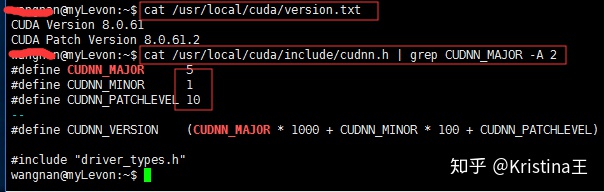
这个结果就表示我的CUDA版本为8.0.61, cuDNN版本为5.1.10
8、一些软件安装
裸机状态下先安装pip
pip2:
sudo apt-get install python-pip python-dev build-essential
pip3:
sudo apt-get install pip3或者sudo apt-get install python3-pip
升级:
pip install --upgrade pip
anaconda 安装:
安装目录:/home/用户名/anaconda
bash Anaconda.sh 文件
按照提示,安装成功。
然后还要环境配置一下(配置环境变量):
如果是界面:sudo gedit ~/.bashrc
如果是命令行安装,则为 :vim ~/.bashrc (采用此方式)
然后进入vim环境中,在最后一行加入下面一句话:
export PATH="/home/用户名/anaconda2/bin:$PATH"
(:wq)
然后:source ~/.bashrc
最后,再python一下试验是否成功。
配置运行环境:
- 安装pytorch
根据anaconda安装的python版本下载pytorch版本:
注意:利用上面这句话安装超级慢,然后中途可能会断网。那么就根据断网后报错的链接去下载。

终于在连续下载失败N次后下载成功了!!!这时要注意一定不要把pytorch的压缩包另外放到一个文件夹,而是一定一定要把下载的压缩包放到/home/用户名/anaconda3/pkgs里面,因为利用conda install 命令安装各种包时,都会在该pkgs里面寻找对应的包进行安装。
在安装时,注意将安装路径切换到pkgs路径下面:

新建环境 :conda create -n 环境名
删除环境: conda remove -n 环境名 --all
在当前环境下安装各种包:conda install 包名
在当前环境下删除各种包:conda uninstall 包名
如果安装不成功,则可以用pip安装 :pip install 包名
一般深度学习安装的各种包包括:pillow、jupyter、matplotlib、lxml、opencv、keras,jupyter notebook,pytorch等
如果安装指定包的版本,以tensorflow为例,则为:conda install tensorflow-gpu=1.2
这里一定要注意:cuda和cudnn以及Keras和TensorFlow的匹配问题,一定要注意各版本的兼容与匹配,还要注意安装顺序,有教程总结了各包的兼容版本与安装顺序!!!
安装jupyter notebook并远程配置:
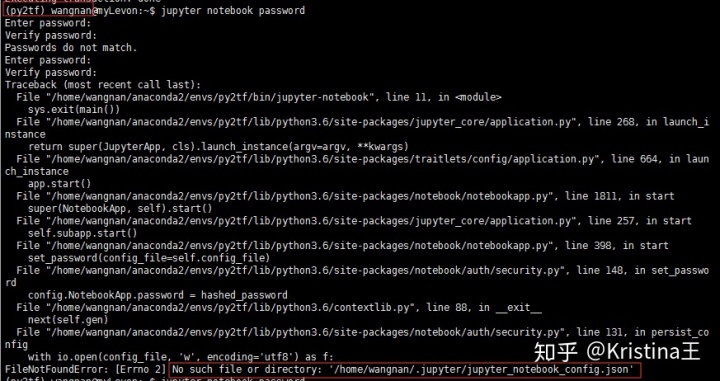

发现报错:找不到json文件,是因为路径设置错了,进入vim,具体可参考:
https://blog.youkuaiyun.com/ShawnAtCSDB/article/details/83827608

在根目录下安装jupyter notebook


ubuntu 中下载并安装opencv2
Ubuntu16.04下安装OpenCV2.4.13:
Ubuntu16.04下安装OpenCV2.4.13 - 上品物语 - 博客园www.cnblogs.com

报错:
安装opencv-python
pip install opencv-python

根据报错的网址进行下载:

Windows10使用Anaconda安装OpenCV(二):
下载whl格式的opencv文件:
https://www.lfd.uci.edu/~gohlke/pythonlibs/
Windows10使用Anaconda安装OpenCV(二)www.jianshu.com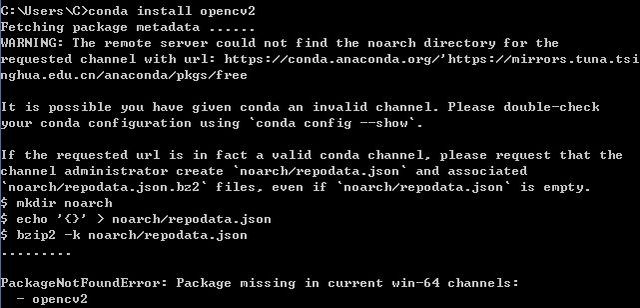
在windows系统中的pycharm配置anaconda 虚拟坏境:
file-settings:
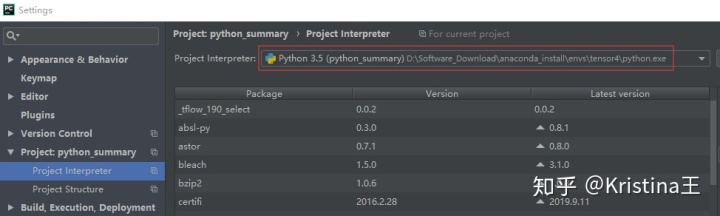

9、linux 进程查看及杀死进程
(1). ps -ef |grep redis
ps:将某个进程显示出来 -A 显示所有程序。 -e 此参数的效果和指定"A"参数相同。 -f 显示UID,PPIP,C与STIME栏位。 grep命令是查找 中间的|是管道命令 是指ps命令与grep同时执行
这条命令的意思是显示有关redis有关的进程
(2). kill[参数][进程号]
kill -9 4394
kill就是给某个进程id发送了一个信号。默认发送的信号是SIGTERM,而kill -9发送的信号是SIGKILL,即exit。exit信号不会被系统阻塞,所以kill -9能顺利杀掉进程。当然你也可以使用kill发送其他信号给进程。
本地服务器向远程服务器传送文命令:
scp -r 本地文件名@远程服务器地址:/远程路径
具体可参考:
https://blog.youkuaiyun.com/MahoneSun/article/details/80809042blog.youkuaiyun.comUbuntu下gcc安装及使用:
https://blog.youkuaiyun.com/lucifa_li/article/details/79483686blog.youkuaiyun.com什么是Gcc:
Linux系统下的Gcc(GNU C Compiler)是GNU推出的功能强大、性能优越的多平台编译器,是GNU的代表作品之一。gcc是可以在多种硬体平台上编译出可执行程序的超级编译器,其执行效率与一般的编译器相比平均效率要高20%~30%。
Gcc编译器能将C、C++语言源程序、汇程式化序和目标程序编译、连接成可执行文件,如果没有给出可执行文件的名字,gcc将生成一个名为a.out的文件。在Linux系统中,可执行文件没有统一的后缀,系统从文件的属性来区分可执行文件和不可执行文件。

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









