







 本文介绍了在面临多个数据库数据同步需求时,如何利用MySQL的binlog和阿里巴巴的开源工具Canal来实现实时数据同步。文章详细讲解了从手动解析binlog到使用Canal简化流程的过程,包括配置Canal、监听binlog事件以及处理数据变更的步骤,最终实现灵活、高效的数据同步解决方案。
本文介绍了在面临多个数据库数据同步需求时,如何利用MySQL的binlog和阿里巴巴的开源工具Canal来实现实时数据同步。文章详细讲解了从手动解析binlog到使用Canal简化流程的过程,包括配置Canal、监听binlog事件以及处理数据变更的步骤,最终实现灵活、高效的数据同步解决方案。
业务背景
写任何 工具 都不能脱离实际业务的背景。开始这个项目的时候是因为现有的项目中数据分布太零碎,零零散散的分布在好几个 数据库 中,没有统一的数据库来收集这些数据。这种情况下想做一个大而全的会员中心系统比较困难。(这边是一个以互联网保险为中心的项目,保单,会员等数据很零散的储存在好几个项目之中,并且项目之间的数据基本上是隔离的)。
现有的项目数据库是在腾讯云中储存,虽然腾讯提供了数据同步功能,但是这样必须要表结构相同才行,并不符合我们的需求。所以需要自行开发。
需求
1:需要能灵活配置。
2:实时数据10分钟内希望可以完成同步。
3:来源数据与目标数据可能结构,字段名称不同。
4:增删改都可以同步。
技术选择
这个任务交给了我和另外一个同事来做。
同事的
同事希望可以通过ETL工具Kettle来做,这个东西我没有研究过,是同事自己在研究。具体过程不是很清楚,但是最后是通过在 mysql 中设置更新,修改,删除的触发器,然后在Kettle中做了一个定时任务,实现了数据同步的功能,初步测试符合需求。但是必须要在数据库中设置触发器,并且会有一个临时表,这一点我个人不是很喜欢。
我的
我是本着能自己写就自己写的原则 ,准备自己写一个。刚开始使用的是定时任务比较两个库的数据差别,然后再同步数据。但是经过一定的数据测试后,发现在数据量大的时候,定时任务中的上一个任务没有执行完毕,下一个任务就又开始了。这样造成了两边数据不一致。最终这个方案废弃了。
后来通过研究,发现mysql的数据操作会记录在binlog中,这时就有了新的方案。可以通过逐行获取binlog信息,经过解析数据后,同步在目标库中。
既然有了方案,那么就开始做吧。
开始尝试:1
首先要打开数据库的binlog功能,这一步比较简单,修改mysql的配置文件: /etc/mysql/mysql.conf.d/mysqld.cnf ,添加:
server-id= 1
log_bin= /var/log/mysql/mysql-bin.log
expire_logs_days= 10
max_binlog_size = 100M
binlog_format = ROW
然后重启mysql 就好了,具体每个参数的意思,搜索一下就好了。这时候随意的对某一个数据库中的表做一下增删改,对应的日志就会记录在 /var/log/mysql/ 这个文件夹下了。我们看一下这个文件夹里的东西:
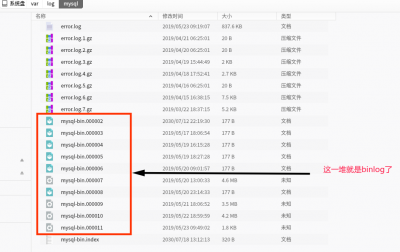
这里的文件是没有办法正常查看的,需要使用mysql提供的命令来查看,命令是这个样子的:
1:查看
mysqlbinlog mysql-bin.000002
2:指定位置查看
mysqlbinlog --start-position="120" --stop-position="332" mysql-bin.000002
因为我们现在的 binlog_format 指定的格式是 ROW (就在上面写的,还记得吗?),所谓binlog文件的内容没有办法正常查看,因为他是这个样子的:
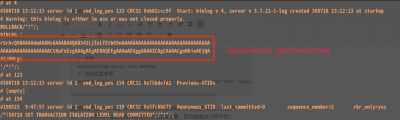
这时,我们需要:
对输出进行解码
mysqlbinlog --base64-output=decode-rows -v mysql-bin.000001
这时候,显示的结果就变成了:
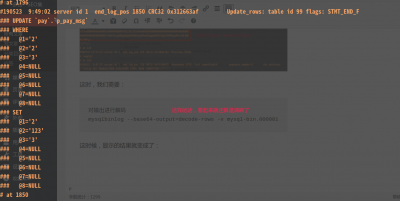 虽然还不是正常的sql,但是好赖是有一定的格式了。
虽然还不是正常的sql,但是好赖是有一定的格式了。
but自己来做解析的话还是很麻烦,so~放弃这种操作。
继续尝试:2
经过再次研究后,发现数据库中执行sql也是可以查看binlog的。主要有如下几条命令:
重置binlog
reset master;
查看binlog的配置
show variables like '%binlog%';
查看所有的binlog
show binary logs;
查看正在写入的binlog
show master status;
查看指定binlog文件
show binlog events in 'mysql-bin.000001';
查看指定binlog文件,并指定位置
show binlog events in 'mysql-bin.000001' from [pos] limit [显示多少条];
按照上面的命令执行结果为:
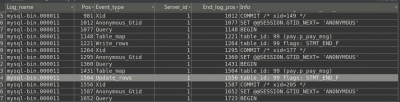
发现sql还是不能正常显示。这里的原因应该是 binlog_format 配置的原因。将其修改为 binlog_format= Mixed 后,完美解决。经过数据库中一通增删改后,显示的sql类似这样:
use `pay`; /* ApplicationName=DataGrip 2018.2.5 */ UPDATE `pay`.`p_pay_log` t SET t.`mark_0` = 'sdfsdf' WHERE t.`id` LIKE '342' ESCAPE '#'
现在似乎已经可以开始写数据同步了,只要在启动的时候获取当正在使用
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 2658
2658

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









