






MATLAB作为科学计算的主流工具,在处理大规模数据或复杂算法时,代码效率直接影响生产力。以下是提升MATLAB代码运行速度的10个关键技巧,从基础到进阶全面覆盖。
1. 向量化操作:告别循环
重要性:MATLAB底层基于矩阵运算,循环效率远低于向量化操作。
优化策略:用矩阵运算替换for/while循环。
% 记录低效循环代码的开始时间
tic;
sum1 = 0;
for i = 1:100000
sum1 = sum1 + i;
end
% 记录低效循环代码的结束时间并计算运行时间
time_loop = toc;
% 记录向量化代码的开始时间
tic;
sum2 = sum(1:100000);
% 记录向量化代码的结束时间并计算运行时间
time_vectorized = toc;
% 显示结果
fprintf('低效循环代码运行时间: %.6f 秒\n', time_loop);
fprintf('向量化代码运行时间: %.6f 秒\n', time_vectorized);
% 显示结果差值
time_difference = time_loop - time_vectorized;
fprintf('循环代码比向量化代码慢 %.6f 秒\n', time_difference);
2. 预分配内存:避免动态扩容
重要性:动态扩展数组会导致反复复制内存,严重拖慢速度。
优化策略:预先用zeros、ones等函数固定数组大小。
% 记录未预分配内存代码的开始时间
tic;
data1 = [];
for i = 1:10000
data1(end + 1) = i^2;
end
% 记录未预分配内存代码的结束时间并计算运行时间
time_unpreallocated = toc;
% 记录预分配内存代码的开始时间
tic;
data2 = zeros(1, 10000);
for i = 1:10000
data2(i) = i^2;
end
% 记录预分配内存代码的结束时间并计算运行时间
time_preallocated = toc;
% 显示结果
fprintf('未预分配内存代码运行时间: %.6f 秒\n', time_unpreallocated);
fprintf('预分配内存代码运行时间: %.6f 秒\n', time_preallocated);
% 显示结果差值
time_difference = time_unpreallocated - time_preallocated;
fprintf('未预分配内存代码比预分配内存代码慢 %.6f 秒\n', time_difference); 
3. 优先使用内置函数
重要性:MATLAB内置函数(如sum、mean)由C++实现,比自定义函数快数十倍。
优化策略:熟悉常用函数,避免重复造轮子。
% 生成一个示例数组
N = 100000; % 数组的长度
array = rand(1, N); % 生成一个长度为 N 的随机数组
% 测量自定义循环求和的时间
tic;
total_loop = 0;
for i = 1:N
total_loop = total_loop + array(i);
end
time_loop = toc;
% 测量使用内置 sum 函数求和的时间
tic;
total_sum = sum(array);
time_sum = toc;
% 显示结果
fprintf('自定义循环求和运行时间: %.6f 秒\n', time_loop);
fprintf('使用内置 sum 函数求和运行时间: %.6f 秒\n', time_sum);
% 计算时间差
time_difference = time_loop - time_sum;
fprintf('自定义循环求和比内置 sum 函数慢 %.6f 秒\n', time_difference);
4. 稀疏矩阵处理大型稀疏数据
重要性:稀疏矩阵(sparse)可节省内存与计算时间。
优化策略:对零元素占比高的矩阵使用稀疏存储。
% 比较直接定义密集矩阵和稀疏矩阵的创建时间
% 测量直接定义密集矩阵的时间
tic;
dense_matrix = eye(1000);
time_dense = toc;
% 测量创建稀疏矩阵的时间
tic;
sparse_matrix = speye(1000);
time_sparse = toc;
% 显示结果
fprintf('直接定义密集矩阵的运行时间: %.6f 秒\n', time_dense);
fprintf('创建稀疏矩阵的运行时间: %.6f 秒\n', time_sparse);
% 计算时间差
time_difference = time_dense - time_sparse;
fprintf('直接定义密集矩阵比创建稀疏矩阵慢 %.6f 秒\n', time_difference);
5. 逻辑索引代替find函数
重要性:逻辑索引无需生成中间数组,效率更高。
优化策略:直接用逻辑表达式筛选数据。
% 生成示例数据
data = rand(1, 100000); % 生成一个包含 100000 个随机数的行向量
% 测量使用 find 函数的时间
tic;
indices = find(data > 0.5);
filtered_find = data(indices);
time_find = toc;
% 测量使用逻辑索引的时间
tic;
filtered_logical = data(data > 0.5);
time_logical = toc;
% 显示结果
fprintf('使用 find 函数过滤数据的运行时间: %.6f 秒\n', time_find);
fprintf('使用逻辑索引过滤数据的运行时间: %.6f 秒\n', time_logical);
% 计算时间差
time_difference = time_find - time_logical;
fprintf('使用 find 函数比使用逻辑索引慢 %.6f 秒\n', time_difference);
6. 避免全局变量
重要性:全局变量(global)阻碍MATLAB内存优化,降低代码可维护性。
优化策略:改用函数参数传递或嵌套函数共享数据。
% 避免示例
global config;
config = load('params.mat');
% 优化方法
function result = compute(data, params)
result = data * params.weight;
end7. 利用parfor加速并行计算
重要性:多核CPU并行处理循环任务,耗时减少近线性倍率。
优化策略:对独立迭代的循环使用parfor。
% 串行循环
for i = 1:100
process(data(i));
end
% 并行替代
parfor i = 1:100
process(data(i));
end注意:需安装Parallel Computing Toolbox,并预先启动并行池(parpool)。
8. 分析瓶颈:使用性能分析工具
重要性:盲目优化可能徒劳,优先针对性优化耗时模块。
优化策略:利用profile命令定位性能瓶颈。
profile on; % 开启性能分析
my_slow_code();% 运行待优化代码
profile viewer;% 查看详细耗时报告% 定义待分析的函数
function my_slow_code()
% 模拟一些耗时操作
for i = 1:10000
for j = 1:1000
temp = i * j;
end
end
end
% 开启性能分析
profile on;
% 运行待优化代码
my_slow_code();
% 查看详细耗时报告
profile viewer;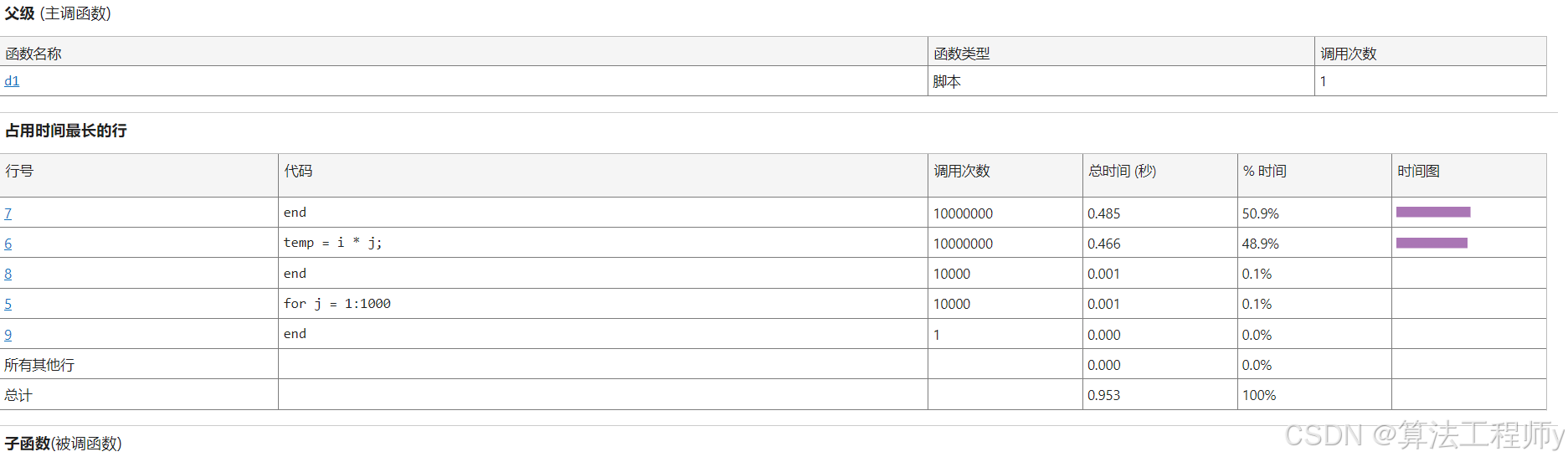
9. 处理大数据时使用内存映射文件
重要性:内存映射(memmapfile)允许直接访问硬盘数据,避免一次性加载超内存数据集。
优化策略:
% 创建内存映射文件
m = memmapfile('large_data.bin', 'Format', 'double');
data_block = m.Data(1:1000); % 按需读取部分数据10. 选择高效算法与数据结构
重要性:算法的时间复杂度(O(n²) vs O(n log n))比代码细节优化影响更大。
优化策略:根据任务特性选择最优算法(如快速排序 vs 冒泡排序)。
% 低效的冒泡排序
sorted = bubble_sort(data);
% 高效的内置排序
sorted = sort(data);综合优化原则
- 先正确,再优化:保证代码功能正确后再进行优化。
- 二八定律:优先优化最耗时的20%代码段。
- 平衡可读性:必要时牺牲少量效率保持代码可维护性。
掌握这10个技巧,可轻松应对90%的MATLAB性能问题。

















 9703
9703

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









