



 本文探讨了《Depth from Videos in the Wild》论文中的亮点,包括无需实例分割处理移动物体的方法、遮挡情形下的深度预测一致性及通过网络学习内参等。重点分析了遮挡处理对深度预测的影响。
本文探讨了《Depth from Videos in the Wild》论文中的亮点,包括无需实例分割处理移动物体的方法、遮挡情形下的深度预测一致性及通过网络学习内参等。重点分析了遮挡处理对深度预测的影响。
2019年7月17日11:37:05
论文 Depth from Videos in the Wild: Unsupervised Monocular Depth Learning from Unknown Cameras
主要有几个亮点:
1,处理移动物体时 instance segmentation and tracking are not required,不需要实例分割,
虽然文章里说还是需要一个网络预测可能移动的区域,但比起需要实例分割,难度还是下降了点。
2,occlusion-aware consistency 遮挡情形下的深度预测一致性
3,能够通过网络学习内参
这篇文章还是有点干货的,毕竟谷歌出品。
先讨论第二点,遮挡情形下的深度预测的问题
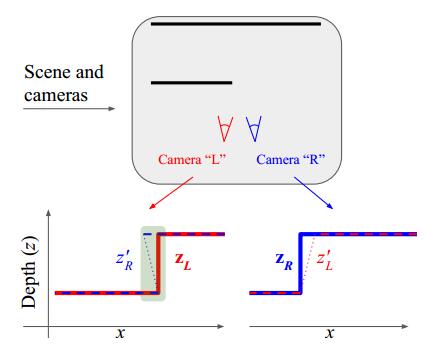

这里很好理解也比较好实现:
左右两个相机对同一个场景进行观察,但是因为存在遮挡的原因,左右两个相机对
同一个三维点的深度预测结果不一致。这些遮挡区域有什么特点呢?

为什么是这些区域?
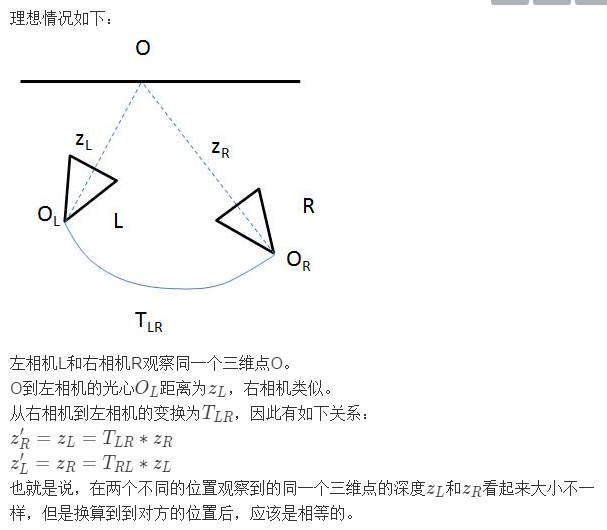
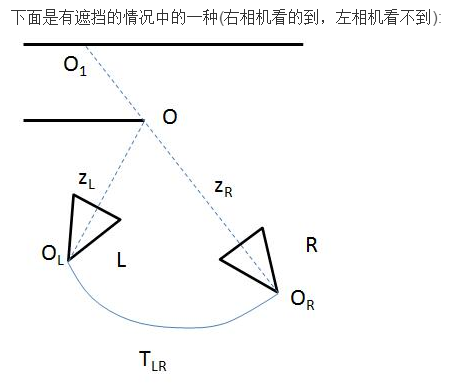
这里就不仅要像sfmlearner中做warp ref img to tgt ,还要在两个相机位置上互相warp深度图,
再把上述区域剔除出计算loss的部分。
深度不一致,一是因为有遮挡,二是因为这个三维点在运动。

所以这个方式对于处理移动物体的深度预测也是有帮助的
总的来讲就是要让loss计算的更清楚,把不该计算的部分剔除出去。
2019年7月18日12:18:13
我想了一下,warp ref_img和warp 深度图Z是一样的,利用现有设施简单改造下
就可以达到目标。
2019年7月19日23:42:42
遮挡的处理会干扰ssim的计算。。。


















 2327
2327

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









