






 本文详细介绍了列表、元组、字典和集合四种基本数据结构的操作方法,包括增加、删除、修改、查找及遍历等内容,并对比了它们之间的联系与区别。
本文详细介绍了列表、元组、字典和集合四种基本数据结构的操作方法,包括增加、删除、修改、查找及遍历等内容,并对比了它们之间的联系与区别。
list=['a','b','c']
list.append(['d','q'])
list.extend(['e','f'])
list.insert(0,1)
删:
list=['a','b','c','d','e','f']
del list[0]
list.pop()
list.remove('e')
list.clear()
查:
print(list)
print(list[0])
改:
list=['a','b','c','d','e','f']
list[0]=1
print(list)
遍历:
for i in list:
print(i,end='')
for i in range(len(list)):
print(list[i],end='')
for index,value in enumerate(list):
print(index,value)
2、元组
增:
tupA=('a','b','c','d','e','f')
tupB=('q','m')
tupC=tupA+tupB
print(tupC)
删:
del tupC
查:
print(tupC)
print(tupC[0]) 
改:
元组不能修改
遍历:
for i in tupA:
print(i,end='')
for i in range(len(list)):
print(tupA[i],end='')
for index,value in enumerate(tupA):
print(index,value)
3、字典
增:
dict={'a':1,'b':2,'c':3,'d':4}
dict['e']=5
dict.update({'f':6,'g':7})
print(dict)
删:
dict={'a':1,'b':2,'c':3,'d':4}
del dict['a']
dict.pop('d')
print(dict)
查:
dict={'a':1,'b':2,'c':3,'d':4}
print(dict['a'])
改:
dict={'a':1,'b':2,'c':3,'d':4}
dict.update({'a':9999})
dict['b']=999
print(dict)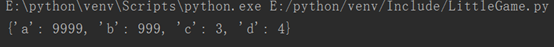
遍历:
dict={'a':1,'b':2,'c':3,'d':4}
for i in dict.items():
print(i)
for i in dict.keys():
print(i)
for i in dict.values():
print(i)
for i,j in dict.items():
print(i,j) 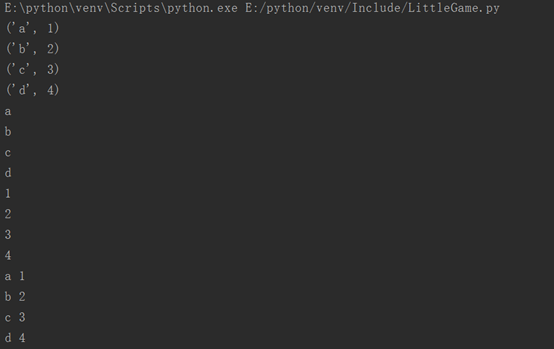
4、集合
增:
set={'a',1,2,'c','d'}
set.update({'qq':1})
set.update([1,2,3])
set.add('bb')
print(set)

删:
set={'a',1,2,'c','d'}
set.discard('qqqq')
set.remove('a')
set.pop()
set.clear()
print(set)
查:
set={'a',1,2,'c','d'}
print(set) 
改:
没有修改的方法
遍历:
set={'a',1,2,'c','d'}
for i in set:
print(i,end='')

二.总结列表,元组,字典,集合的联系与区别。
1、列表的括号是"[ ]" ,元组的括号是”( )“,字典的括号和集合的括号都是”{ }“;
2、列表与元组都为有序序列,字典与集合为无序序列;
3、列表、字典、集合属于可变序列,而元组属于不可变序列;
4、列表和元组允许重复,而字典和集合不允许重复;
5、列表和元组是可以根据下标进行查找,但元组不可修改,列表可以,字典可根据字典的键名查找相应的值,集合是不允许通过下标进行查询的。
三.词频统计
1.下载一长篇小说,存成utf-8编码的文本文件 file
2.通过文件读取字符串 str
3.对文本进行预处理
4.分解提取单词 list
5.单词计数字典 set , dict
6.按词频排序 list.sort(key=lambda),turple
7.排除语法型词汇,代词、冠词、连词等无语义词
- 自定义停用词表
- 或用stops.txt
8.输出TOP(20)
9.可视化:词云
排序好的单词列表word保存成csv文件
import pandas as pd
pd.DataFrame(data=word).to_csv('big.csv',encoding='utf-8')
线上工具生成词云:
https://wordart.com/create
代码如下:
import pandas as pd
file=open('artical.txt',encoding='utf-8')
text=file.read()
text=text.lower()
for i in str('''?!",.'''):
text=text.replace(i,'')
text=text.split()
# 统计单词数量
exclude = ['a', 'the', 'and', 'if', 'you', 'in', 'but', 'not', 'it', ' s', 'if', "i"]
dict={}
for i in text:
if i not in exclude:
if i not in dict:
dict[i]=text.count(i)
print(dict)
# 排序单词数量
word=list(dict.items())
word.sort(key=lambda x: x[1], reverse=True)
print(word)
# 输出前二十位的单词
for i in range(20):
print(word[i])
pd.DataFrame(data=word).to_csv('b.csv',encoding='utf-8')
运行结果:
生成csv文件如下:
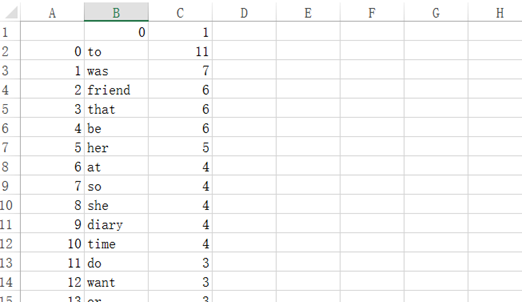
生成词云如下:


















 246
246

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









