






 本文介绍了在【Flow-center-web】系统中遇到的数据库死锁问题,通过CAT监控和MySQL死锁状态分析,发现死锁源于流程创建和更新消息并发消费,以及代码中消息Partition路由策略失效。解决方案包括修复消息路由策略和调整数据库事务操作顺序,以确保消息处理的顺序性和避免资源冲突。
本文介绍了在【Flow-center-web】系统中遇到的数据库死锁问题,通过CAT监控和MySQL死锁状态分析,发现死锁源于流程创建和更新消息并发消费,以及代码中消息Partition路由策略失效。解决方案包括修复消息路由策略和调整数据库事务操作顺序,以确保消息处理的顺序性和避免资源冲突。
背景
清流控制台应用系统【Flow-center-web】在【2020-08-07 16:40:XX】-【2020-08-07 17:40:XX】期间陆续收到【数据库Deadlock】Cat告警消息,
需要排查和定位问题的原因,
检查应用系统是否存在缺陷风险
此问题对应用系统的影响范围。
问题的解决方案

问题排查
CAT监控排查
通过应用系统的Cat监控,发现【2020-08-07 16:40:XX】-【2020-08-07 17:40:XX】应用系统打打点流程的处理失败率较高,具体如图

详情参考:


通过Cat监控大批量的出现了【DeadlockLoserDataAccessException】,此异常调用链主要时在清流流程处理监控消息时【processWFMsg】来根据流程的状态信息决定创建流程【createFlow】或者时更新流程【updateFlow】的行为.

死锁状态分析
['
=====================================
2020-08-07 16:55:12 0x7f5ead17d700 INNODB MONITOR OUTPUT
=====================================
Per second averages calculated from the last 8 seconds
-----------------
BACKGROUND THREAD
-----------------
srv_master_thread loops: 4896283 srv_active, 0 srv_shutdown, 265242 srv_idle
srv_master_thread log flush and writes: 5161498
----------
SEMAPHORES
----------
OS WAIT ARRAY INFO: reservation count 41499456
OS WAIT ARRAY INFO: signal count 54386950
RW-shared spins 0, rounds 39950592, OS waits 4200543
RW-excl spins 0, rounds 2396693258, OS waits 18732934
RW-sx spins 48873547, rounds 999958857, OS waits 15310886
Spin rounds per wait: 39950592.00 RW-shared, 2396693258.00 RW-excl, 20.46 RW-sx
------------------------
LATEST DETECTED DEADLOCK
------------------------
2020-08-07 16:55:12 0x7f49dd59b700
*** (1) TRANSACTION:
TRANSACTION 371818041, ACTIVE 0 sec inserting
mysql tables in use 1, locked 1
LOCK WAIT 4 lock struct(s), heap size 1136, 2 row lock(s), undo log entries 2
MySQL thread id 3412760, OS thread handle 139955255465728, query id 2953157849 10.72.140.11 flowcenter update
insert into wf_node
( flow_id,
node_name,
node_duration,
node_wait_duration,
node_status,
node_reentry_times,
node_id,
node_result )
values ( 1291659133342281834,
\'start\',
0,
0,
0,
0,
1291659133342281813,
\'{"status":"SUCCESS","message":"","success":true}\' )
*** (1) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 54 page no 11412699 n bits 528 index IX_NodeId of table `FlowCenter`.`wf_node` trx id 371818041 lock_mode X locks gap before rec insert intention waiting
*** (2) TRANSACTION:
TRANSACTION 371818040, ACTIVE 0 sec starting index read
mysql tables in use 1, locked 1
6 lock struct(s), heap size 1136, 3 row lock(s)
MySQL thread id 3412884, OS thread handle 139955222984448, query id 2953157856 10.76.195.174 flowcenter updating
update wf_flow
SET template_id = 446,
start_time = \'2020-08-07 16:55:10\',
duration = 2489,
wait_duration = 0,
flow_status = 2,
current_node_id = 1291659133342281813,
current_step_id = 1291659133342281812,
priority = 0
WHERE ( flow_id = 1291659133342281834 )
*** (2) HOLDS THE LOCK(S):
RECORD LOCKS space id 54 page no 11412699 n bits 528 indexIX_NodeId of table `FlowCenter`.`wf_node` trx id 371818040 lock_mode X locks gap before rec
*** (2) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 51 page no 480250 n bits 744 index IX_FlowId of table `FlowCenter`.`wf_flow` trx id 371818040 lock_mode X waiting
通过Mysql的死锁的状态Dump日志分析发现,Mysql分别开启2个事务执行流程操作,分别时【trx id 371818041】的 Insert 【wf_node】与【trx id 371818040】的update【wf_flow】,由于2个事务间存在相互锁定资源,从而引起死锁问题,至于死锁的原因待后续图解,但是根据应用系统处理的特性,流程创建事务操作的执行链如下:
createFlow
|
|-------------insert wf_flow
|-------------insert wf_node
|-------------insert wf_step
updateFlow
|-------------update wf_node
|-------------update wf_step
|-------------update wf_flow
应用排查
消息处理记录排查
基本上通过上面的流程事务处理执行链,很明显存在一个资源竞争的顺序问题,也是大多数死锁产生的原因,但是需要一个前提,那就是事务并发的情况,基础此,排查一下,应用系统中对于createFlow与updateFlow中并发操作的可能行进行排查,通过系统记录的Mafka消息消费记录表中的记录发现,的确发现了流程的流程创建消息和流程更新消息并发的消费了。

但是清流应用系统定制了Mafka的消息发送Partition的路由策略,能保证对于同一个流程(FlowId相同)的消息处理,会发送到同一个partition,同时对于partition的消息也是按照串行的方式,但是通过监控消息表中的消费记录,发现并未有按照预期的设想处理,由此需要从源头中排查2个问题,
1.清流定制的消息Partition的路由策略为何没有生效? 是中间件问题,还是应用代码实现机制有问题?
2.假设消息Partition的路由策略时效,消费并发处理,是否意味着消息发送的并发处理,还是意味着消息积压导致?
消息发送记录排查
1.消息Partition的路由策略失效排查
通过代码排查发现清流定制的消息Partition的路由策略代码没有在最新的代码中实现,对比代码修改记录,在清流1.2.26版本之后,此段Partition的路由策略代码也就遗漏,因此需要修复此代码缺陷问题。
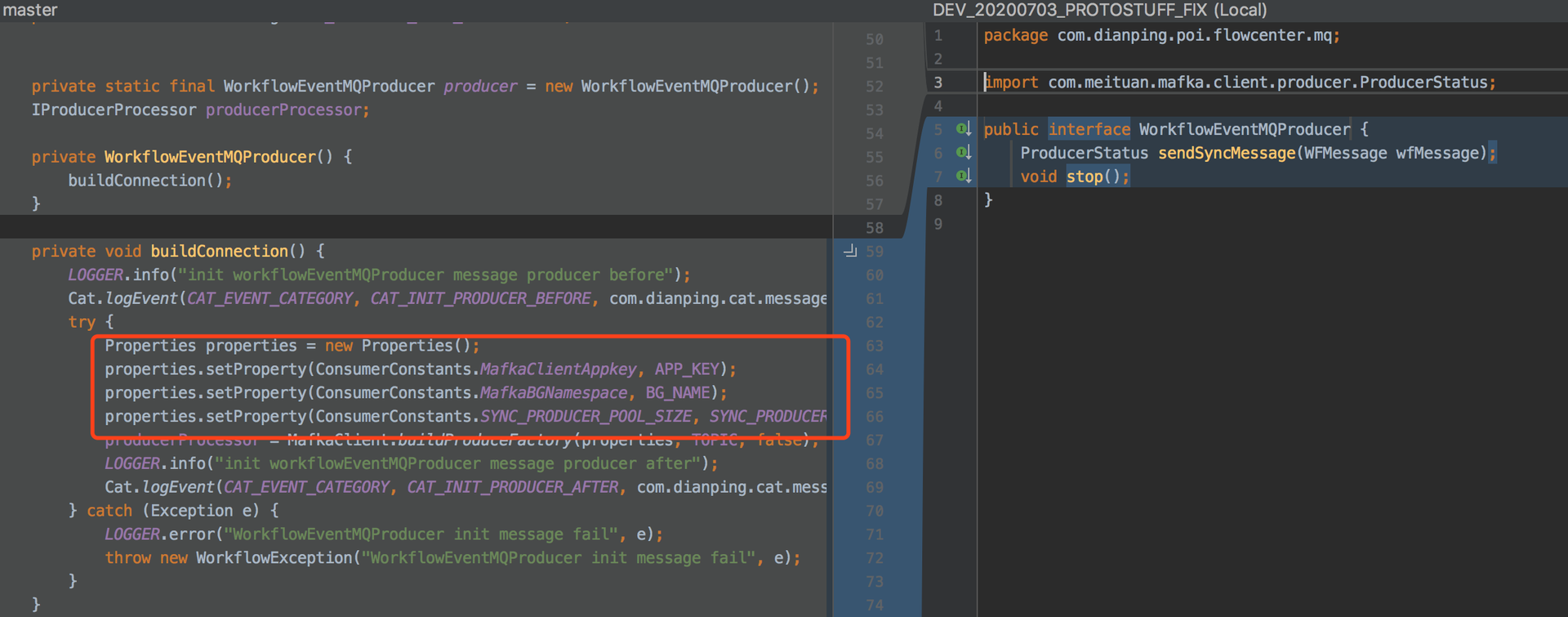 VS
VS
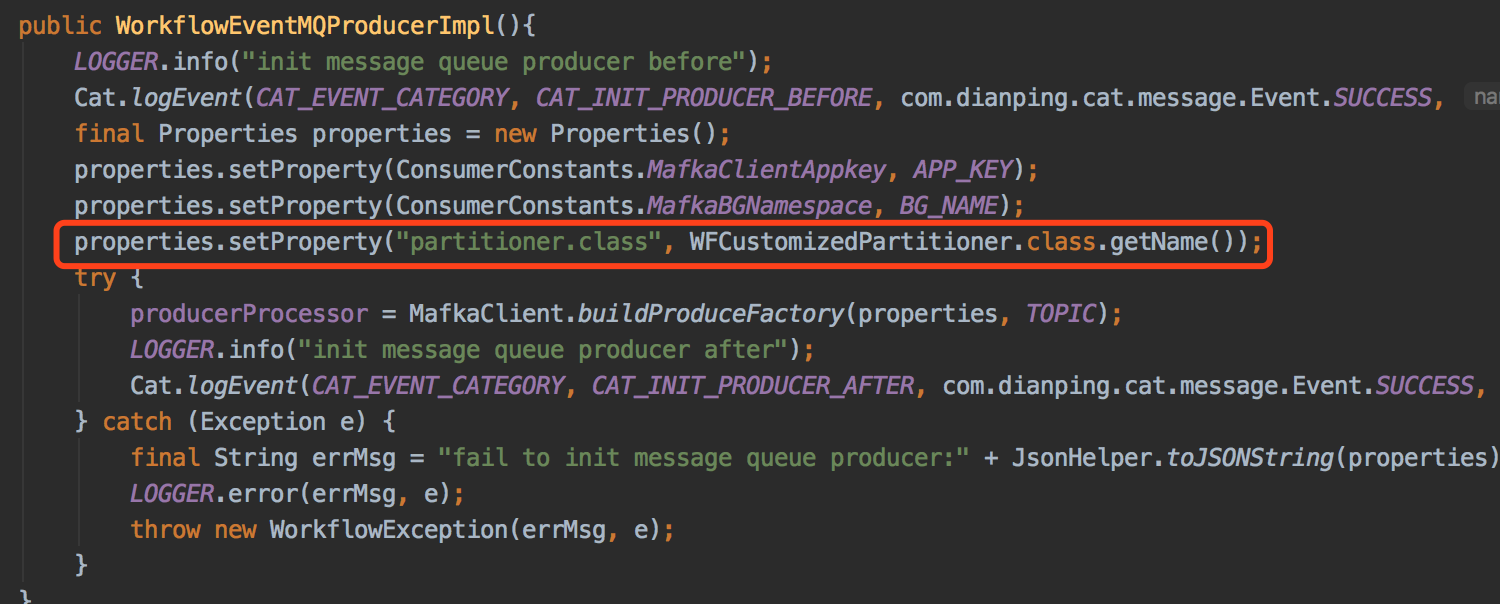
2.消费消息并发处理问题排查
由于流程消息发送时,清流1.2.26版本之后,此段Partition的路由策略失效,导致同一个流程Flowid可能被发送到多个partition的缘故,在多个partition中的消息消费无法保证消息处理的顺序性,因此存在并发处理的可能性
消息创建和消息更新的消息发送到不同的partition中的offset差异,对于不同的partition,可能由于partition积压时,也会存在并发消息问题,本质还是消息的顺序性问题
问题定位
通过上面的问题排查,
1.定位出数据库死锁的根本原因是由于Mafka流程创建消息和Mafka流程更新消息并发消费顺序问题
2.在应用程序代码中流程创建的资源锁定和流程更新的资源锁定顺序不一致,从而导致数据库的资源的相互锁定问题
createFlow
|
|-------------insert wf_flow
|-------------insert wf_node
|-------------insert wf_step
updateFlow
|-------------update wf_step
|-------------update wf_node
|-------------update wf_flow
解决方案
消息Partition的路由策略失效
修改清流1.2.26版本之后,按照FlowId路由策略来发送消息,确保消息的顺序性问题
数据库事务操作的顺序性问题
调整更新操作的顺序性问题 createFlow
|
|-------------insert wf_flow
|-------------insert wf_node
|-------------insert wf_step
updateFlow
|-------------update wf_flow
|-------------update wf_node
|-------------update wf_step
问题验证
先忽略数据库中的GAP锁中复杂情况,单独从执行顺序角度来复现问题验证一下
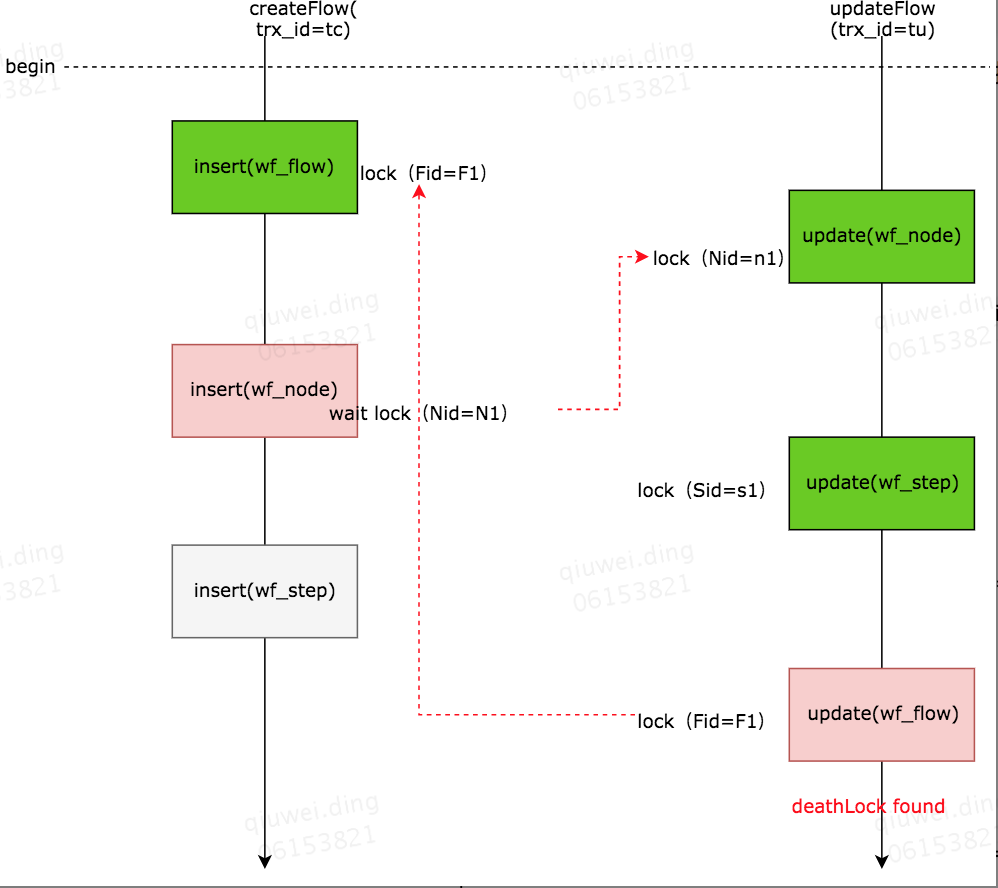
复现脚本
---------------------------------------------------------------------------------------------- | ---------------------------------------------------------------------------|
begin ; |
insert into wf_flow(flow_id,template_id,current_node_id,current_step_id) values(4,443,40,400); | begin;
| update wf_node set node_name='n1' where node_id=40;
| update wf_step set step_name='s1',node_id=30 where step_id=300;
insert into wf_node(flow_id,node_id) values(4,40); -----query waiting...... |
| update wf_flow set current_node_id=40,current_step_id=400 where flow_id=4;
| -----Deadlock found when trying to get lock; try restarting transaction
insert into wf_step(flow_id,node_id,step_id) values(4,40,400);//never happend due deadlock |

















 906
906

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









