






 本文介绍了一种使用SQL对时间戳数据进行间隔分组的方法,即如何将时间间隔小于等于3秒的数据归为同一组。通过创建临时表并插入一系列时间戳数据,演示了如何实现这种分组,并最终展示如何通过聚合函数获取每组的开始和结束时间。
本文介绍了一种使用SQL对时间戳数据进行间隔分组的方法,即如何将时间间隔小于等于3秒的数据归为同一组。通过创建临时表并插入一系列时间戳数据,演示了如何实现这种分组,并最终展示如何通过聚合函数获取每组的开始和结束时间。
实现日期间隔分组, 间隔小于等于3s的数据为一组,数据源如下
create table #tmptable(id nvarchar(20),dd date ,dt datetime)
go
insert #tmptable values('1','2010-1-1','2010-1-1 00:00:01')
insert #tmptable values('1','2010-1-1','2010-1-1 00:00:02')
insert #tmptable values('1','2010-1-1','2010-1-1 00:00:03')
insert #tmptable values('1','2010-1-1','2010-1-1 00:00:04')
insert #tmptable values('1','2010-1-1','2010-1-1 00:00:05')
insert #tmptable values('1','2010-1-1','2010-1-1 00:00:06')
insert #tmptable values('1','2010-1-1','2010-1-1 00:00:07')
insert #tmptable values('1','2010-1-1','2010-1-1 00:00:09')
insert #tmptable values('1','2010-1-1','2010-1-1 00:00:11')
insert #tmptable values('1','2010-1-1','2010-1-1 00:00:12')
insert #tmptable values('1','2010-1-1','2010-1-1 00:00:15')
insert #tmptable values('1','2010-1-1','2010-1-1 00:00:19')
insert #tmptable values('1','2010-1-1','2010-1-1 00:00:20')
insert #tmptable values('1','2010-1-1','2010-1-1 00:00:24')
insert #tmptable values('1','2010-1-1','2010-1-1 00:00:25')
insert #tmptable values('1','2010-1-1','2010-1-1 00:00:26')
insert #tmptable values('1','2010-1-1','2010-1-1 00:00:27')
insert #tmptable values('1','2010-1-1','2010-1-1 00:00:28')
insert #tmptable values('1','2010-1-1','2010-1-1 00:00:29')
insert #tmptable values('1','2010-1-2','2010-1-2 00:00:36')
insert #tmptable values('1','2010-1-2','2010-1-2 00:00:37')
insert #tmptable values('1','2010-1-2','2010-1-2 00:00:48')
insert #tmptable values('1','2010-1-2','2010-1-2 00:00:59')
insert #tmptable values('2','2010-1-1','2010-1-1 00:00:09')
insert #tmptable values('2','2010-1-1','2010-1-1 00:00:11')
insert #tmptable values('2','2010-1-1','2010-1-1 00:00:12')
insert #tmptable values('2','2010-1-1','2010-1-1 00:00:15')
insert #tmptable values('2','2010-1-1','2010-1-1 00:00:19')
insert #tmptable values('2','2010-1-1','2010-1-1 00:00:20')
insert #tmptable values('2','2010-1-1','2010-1-1 00:00:24')
insert #tmptable values('2','2010-1-1','2010-1-1 00:00:25')
insert #tmptable values('2','2010-1-1','2010-1-1 00:00:26')
insert #tmptable values('2','2010-1-1','2010-1-1 00:00:27')
insert #tmptable values('2','2010-1-1','2010-1-1 00:00:28')
insert #tmptable values('2','2010-1-1','2010-1-1 00:00:29')
insert #tmptable values('2','2010-1-2','2010-1-2 00:00:36')
insert #tmptable values('2','2010-1-2','2010-1-2 00:00:37')
insert #tmptable values('2','2010-1-2','2010-1-2 00:00:48')
insert #tmptable values('2','2010-1-2','2010-1-2 00:00:59')
go
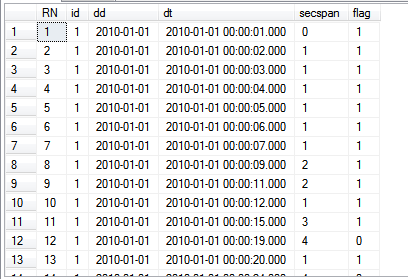
检测数据断点
;WITH MyList AS(SELECT ROW_NUMBER() OVER(ORDER BY id,dd, dt asc) RN,T.* FROM #tmptable T)
select a.RN,a.id,a.dd,a.dt,
CASE WHEN b.dt IS null then 0
ELSE DATEDIFF(ss,b.dt,a.dt) END as secspan,
CASE WHEN b.dt IS null or DATEDIFF(ss,b.dt,a.dt) <= 3 THEN 1 ELSE 0
END as flag
--into #TMP1
from MyList a left join MyList b
on b.RN = a.RN - 1 and a.id = b.id and a.dd = b.dd
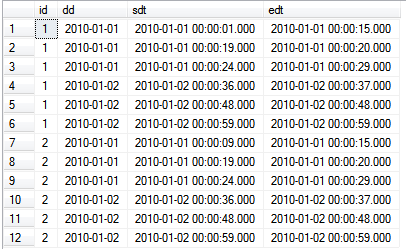
聚合时间段
select id,dd,MIN(dt) as sdt,MAX(dt) as edt from
(
select ss=(select SUM(flag) from #TMP1 where dt <= a.dt and id = a.id and dd = a.dd)
,* from #TMP1 a where id= a.id and dd = a.dd
) a
GROUP BY (RN - ss),id,dd

















 1011
1011

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









