






我在 这篇 文章中介绍了 Apache
并不是什么查询都会启用动态裁剪优化的,必须满足以下几个条件:spark.sql.optimizer.dynamicPartitionPruning.enabled 参数必须设置为 true,不过这个值默认就是启用的;
需要裁减的表必须是分区表,而且分区字段必须在 join 的 on 条件里面;
Join 类型必须是 INNER, LEFT SEMI (左表是分区表), LEFT OUTER (右表是分区表), or RIGHT OUTER (左表是分区表)。
满足上面的条件也不一定会触发动态分区裁减,还必须满足 spark.sql.optimizer.dynamicPartitionPruning.useStats 和 spark.sql.optimizer.dynamicPartitionPruning.fallbackFilterRatio 两个参数综合评估出一个进行动态分区裁减是否有益的值,满足了才会进行动态分区裁减。评估函数实现请参见 org.apache.spark.sql.dynamicpruning.PartitionPruning#pruningHasBenefit。
如何使用 Dynamic Partition Pruning
我们先使用 spark.range(10000)
.select(col("id"), col("id").as("k"))
.write.partitionBy("k")
.format("parquet")
.mode("overwrite")
.saveAsTable("iteblog_tab1")
spark.range(100)
.select(col("id"), col("id").as("k"))
.write.partitionBy("k")
.format("parquet")
.mode("overwrite")
.saveAsTable("iteblog_tab2")
运行完上面的代码之后,iteblog_tab1 表将产生 10000 个分区,iteblog_tab2 表将产生 100 个分区。我们运行下面的查询语句: spark.sql("SELECT * FROM iteblog_tab1 t1 JOIN iteblog_tab2 t2 ON t1.k = t2.k AND t2.id < 2").show()
在没有启用动态分区裁剪的情况下 == Physical Plan ==
CollectLimit 21
+- *(2) Project [cast(id#0L as string) AS id#12, cast(k#1L as string) AS k#13, cast(id#2L as string) AS id#14, cast(k#3L as string) AS k#15]
+- *(2) BroadcastHashJoin [k#1L], [k#3L], Inner, BuildRight
:- *(2) ColumnarToRow
: +- FileScan parquet default.iteblog_tab1[id#0L,k#1L] Batched: true, DataFilters: [], Format: Parquet, Location: PrunedInMemoryFileIndex[file:/user/hive/warehouse/iteblog_tab1/k=0, file:/user/hive/warehouse/ite..., PartitionFilters: [isnotnull(k#1L)], PushedFilters: [], ReadSchema: struct
+- BroadcastExchange HashedRelationBroadcastMode(List(input[1, bigint, true])), [id=#41]
+- *(1) Project [id#2L, k#3L]
+- *(1) Filter (isnotnull(id#2L) AND (id#2L < 2))
+- *(1) ColumnarToRow
+- FileScan parquet default.iteblog_tab2[id#2L,k#3L] Batched: true, DataFilters: [isnotnull(id#2L), (id#2L < 2)], Format: Parquet, Location: PrunedInMemoryFileIndex[file:/user/hive/warehouse/iteblog_tab2/k=0, file:/user/hive/warehouse/ite..., PartitionFilters: [isnotnull(k#3L)], PushedFilters: [IsNotNull(id), LessThan(id,2)], ReadSchema: struct
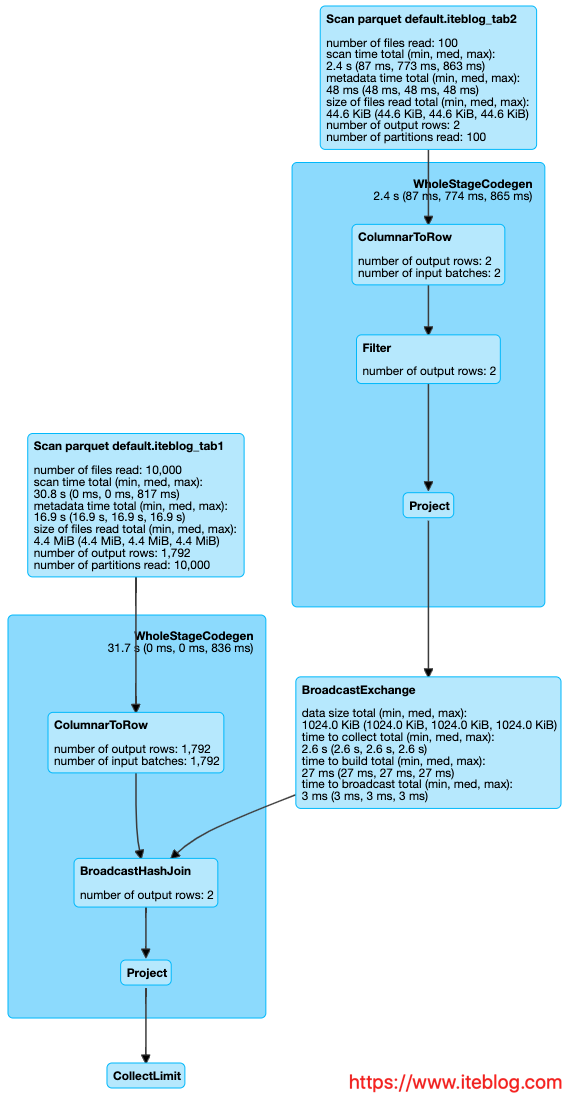
DAG 图如下:
如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop
从上面的 物理执行计划和 DAG 执行图可以看出,这个就是正常的算子下推的结果。
如果我们使用 Apache == Physical Plan ==
CollectLimit 21
+- *(2) Project [cast(id#0L as string) AS id#12, cast(k#1L as string) AS k#13, cast(id#2L as string) AS id#14, cast(k#3L as string) AS k#15]
+- *(2) BroadcastHashJoin [k#1L], [k#3L], Inner, BuildRight
:- *(2) ColumnarToRow
: +- FileScan parquet default.iteblog_tab1[id#0L,k#1L] Batched: true, DataFilters: [], Format: Parquet, Location: PrunedInMemoryFileIndex[file:/user/hive/warehouse/iteblog_tab1/k=0, file:/user/hive/warehouse/ite..., PartitionFilters: [isnotnull(k#1L), dynamicpruningexpression(k#1L IN dynamicpruning#20)], PushedFilters: [], ReadSchema: struct
: +- SubqueryBroadcast dynamicpruning#20, 0, [k#3L], [id=#96]
: +- ReusedExchange [id#2L, k#3L], BroadcastExchange HashedRelationBroadcastMode(List(input[1, bigint, true])), [id=#72]
+- BroadcastExchange HashedRelationBroadcastMode(List(input[1, bigint, true])), [id=#72]
+- *(1) Project [id#2L, k#3L]
+- *(1) Filter (isnotnull(id#2L) AND (id#2L < 2))
+- *(1) ColumnarToRow
+- FileScan parquet default.iteblog_tab2[id#2L,k#3L] Batched: true, DataFilters: [isnotnull(id#2L), (id#2L < 2)], Format: Parquet, Location: PrunedInMemoryFileIndex[file:/user/hive/warehouse/iteblog_tab2/k=0, file:/user/hive/warehouse/ite..., PartitionFilters: [isnotnull(k#3L)], PushedFilters: [IsNotNull(id), LessThan(id,2)], ReadSchema: struct
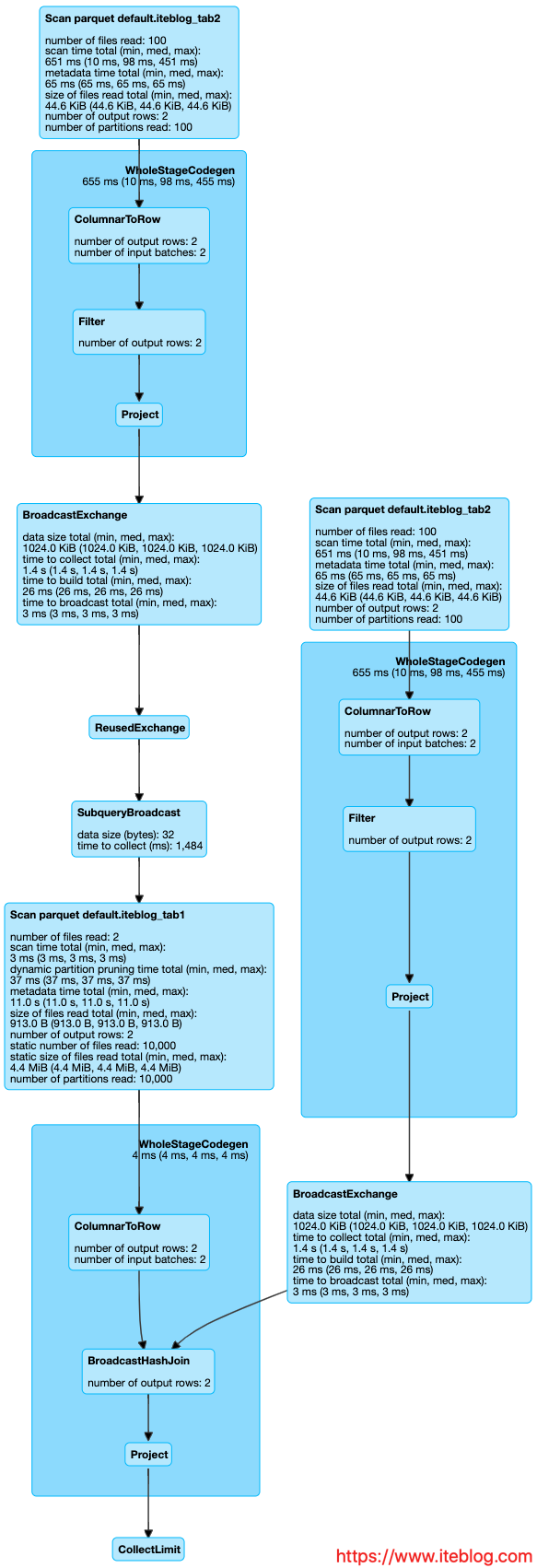
DAG 图如下:
如果想及时了解Spark、Hadoop或者Hbase相关的文章,欢迎关注微信公共帐号:iteblog_hadoop
可以看出,iteblog_tab1 表的扫描相比上面那个多了一个分区过滤(PartitionFilters),在一些情况下性能提升能达到 2 - 18 倍。

















 2099
2099

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









