






 本文介绍了Embedding技术,包括其在降低数据维度、提高计算效率和准确率方面的作用。通过Keras实现的DNN和MatrixFactorization示例,展示了如何使用Embedding层处理用户和电影ID。此外,文章还探讨了Embedding在电影评分预测和语义计算中的应用,并提到了t-SNE等降维算法在数据可视化中的作用。
本文介绍了Embedding技术,包括其在降低数据维度、提高计算效率和准确率方面的作用。通过Keras实现的DNN和MatrixFactorization示例,展示了如何使用Embedding层处理用户和电影ID。此外,文章还探讨了Embedding在电影评分预测和语义计算中的应用,并提到了t-SNE等降维算法在数据可视化中的作用。
Embedding表示map f: X(高维) -> Y(低维),减小数据维度,方便计算+提高准确率。
参看Kaggle Learn:https://www.kaggle.com/learn/embeddings
官方DNN示例:
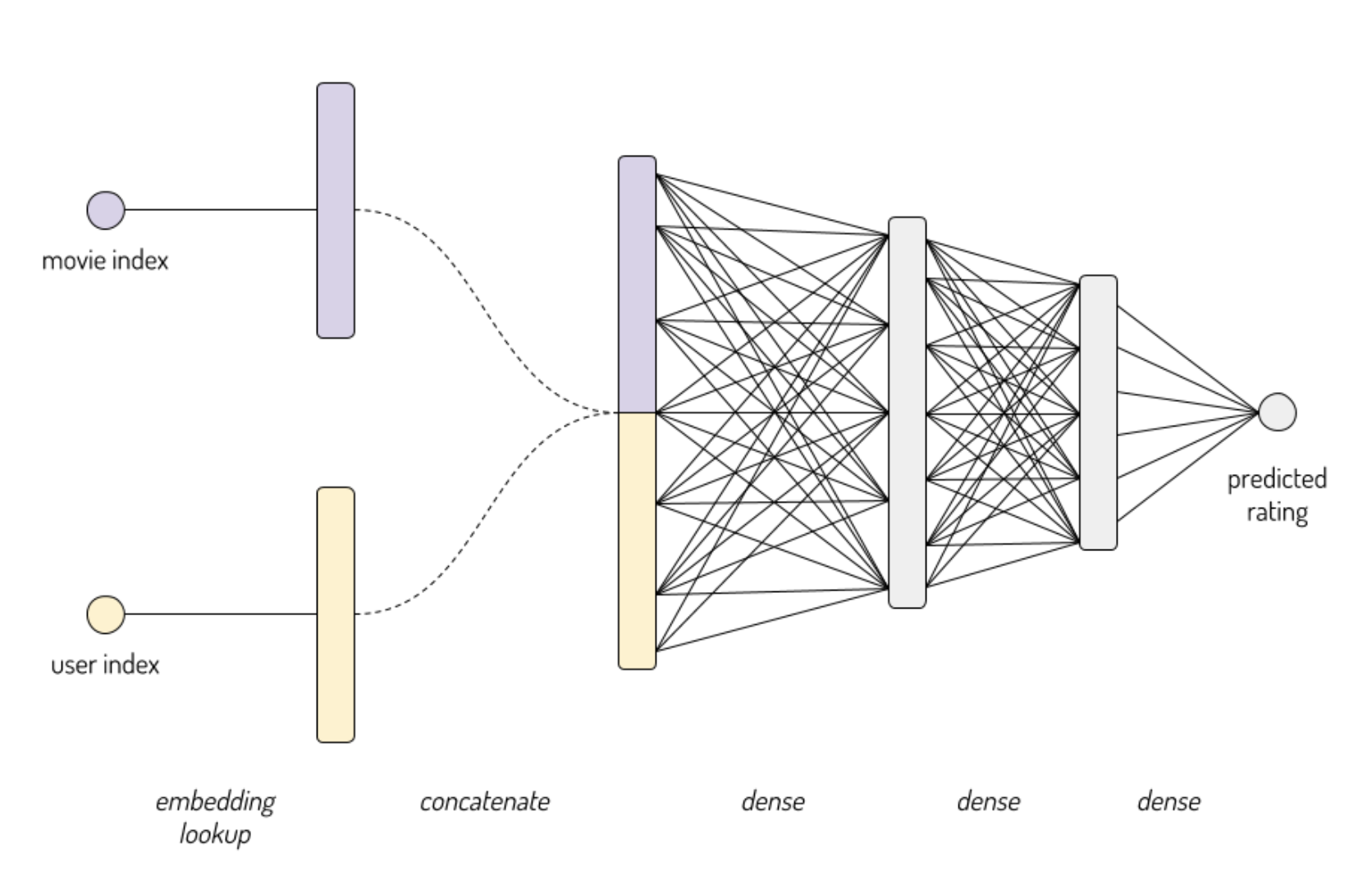
user_id_input = keras.Input(shape=(1,), name='user_id') movie_id_input = keras.Input(shape=(1,), name='movie_id') user_embedded = keras.layers.Embedding(df.userId.max()+1, user_embedding_size, input_length=1, name='user_embedding')(user_id_input) movie_embedded = keras.layers.Embedding(df.movieId.max()+1, movie_embedding_size,
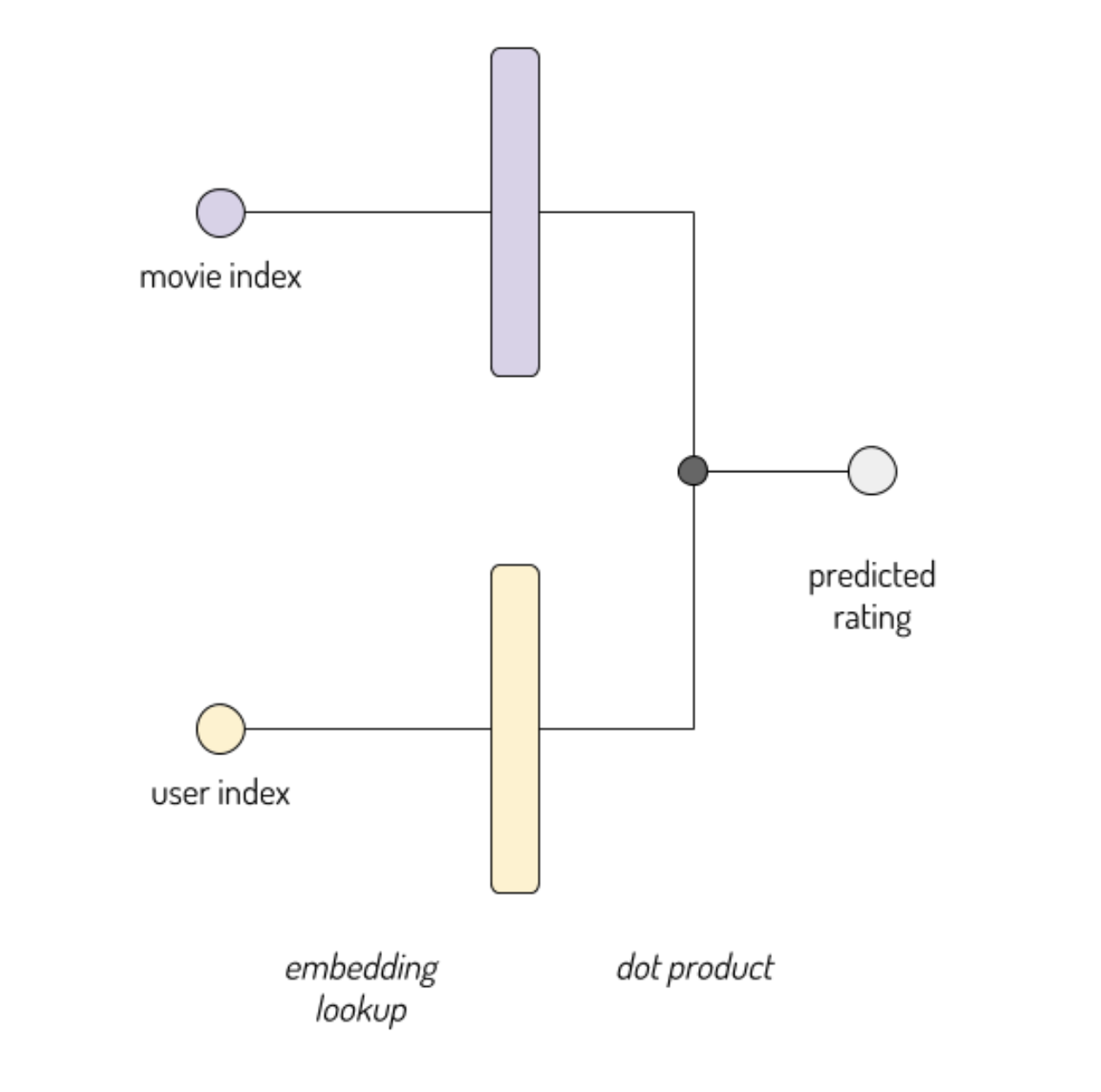
movie_embedding_size = user_embedding_size = 8 # Each instance consists of two inputs: a single user id, and a single movie id user_id_input = keras.Input(shape=(1,), name='user_id') movie_id_input = keras.Input(shape=(1,), name='movie_id') user_embedded = keras.layers.Embedding(df.userId.max()+1, user_embedding_size, input_length=1, name='user_embedding')(user_id_input) movie_embedded = keras.layers.Embedding(df.movieId.max()+1, movie_embedding_size, input_length=1, name='movie_embedding')(movie_id_input) dotted = keras.layers.Dot(2)([user_embedded, movie_embedded]) out = keras.layers.Flatten()(dotted)
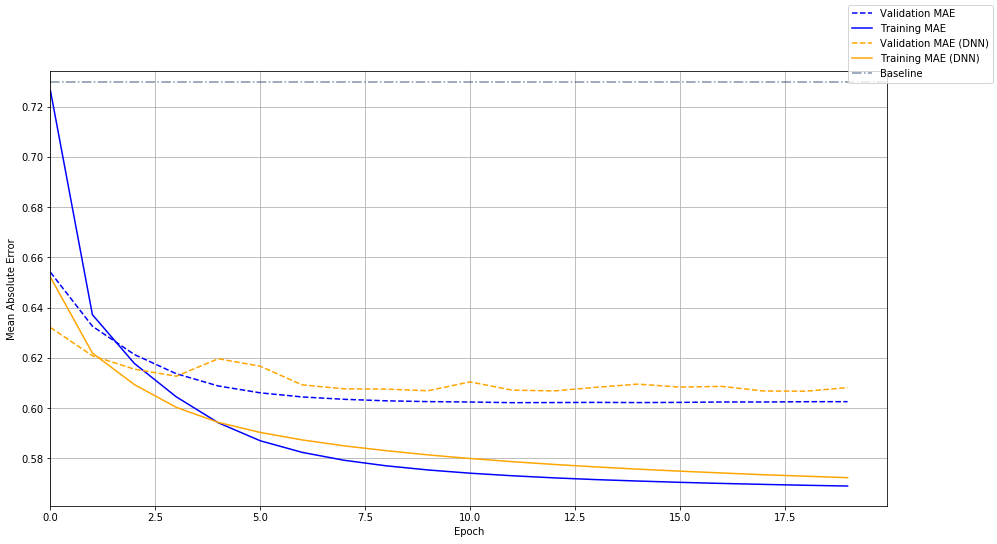
两种类型对比如下,简单模型(蓝色)的表现也相当好,两个模型都有明显的过拟合。
虽源于词向量模型,但是对于电影评价,电影向量模型仍然很实用。
可用于计算电影(或单词)的相似度,支持语义计算(+-),例如可用于求解如下问题:
‘Cars 2’:‘Brave’== '?':‘Pocahontas’,解释,‘Cars 2’相对于‘Brave’就如'?'相对于‘Pocahontas’,求电影'?'最佳匹配。
方程组:
Cars 2 = Brave + X '?' = Pocahontas + X
解方程得到:
'?' = Pocahontas + (Cars 2 - Brave)
Scripts关键语句:
kv.most_similar( ['Pocahontas', 'Cars 2'], negative = ['Brave'] )
Visualizing Embeddings With t-SNE,参考Kaggle Learn: https://www.kaggle.com/colinmorris/visualizing-embeddings-with-t-sne
t-SNE是一种降维算法,一种数据探索和可视化技术,常用于高维数据可视化(降维到2D)
全称:随机邻近嵌入stochastic neighborhood embedding
其基本原理,参考:https://blog.youkuaiyun.com/scythe666/article/details/79203239, https://www.analyticsvidhya.com/blog/2017/01/t-sne-implementation-r-python/

















 487
487

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









