






 本文解析了一个名为Cowtour的问题,该问题涉及寻找农场中牧区间添加路径以形成最小直径新牧场的最优解。通过使用Floyd算法计算最短路径,并枚举不同连通分支间的点对来确定新增路径后的最小直径。
本文解析了一个名为Cowtour的问题,该问题涉及寻找农场中牧区间添加路径以形成最小直径新牧场的最优解。通过使用Floyd算法计算最短路径,并枚举不同连通分支间的点对来确定新增路径后的最小直径。
floyd
一开始脑残地想到强连通分支 tarjan
后来看到数据规模约莫估计不会用这么高深的东西
农民 John的农场里有很多牧区。有的路径连接一些特定的牧区。一片所有连通的牧区称为一个牧场。但是就目前而言,你能看到至少有两个牧区通过任何路径都不连通。这样,Farmer John就有多个牧场了。
John想在农场里添加一条路径(注意,恰好一条)。
如果说像这样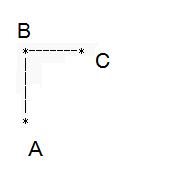
A->B->C A和C其实是有路径相连的 也就是说我不能连接A直达C的路径
即只有当两个牧区属于两个不同的牧场(两个不同的连通分支) 才有可能添加路径
这点很容易搞错吧。。 一开始就这样WA掉了
算法是这样的:
先用floyd求出任意两个可以互相到达的牧区之间的最短路径,如果两个牧区
属于不同牧场,则记f[i,j]=maxlongint
记录数组dm[i]表示i牧区所属连通分支离i最远的牧区 到i的距离 ,如果
此距离>nowmax ,更新nowmax
以此求出所有连通分支中直径的最大值
其实就是求直径最大值记为fmax
枚举两个属于不同连通分支(即不同牧场)的牧区,(点对<a,b>)
在之间添加路径,则dm[a]+dm[b]+<a,b>之间直线距离即为 新牧场的直径
找出最小的直径(题目中要求最小)记为fmin
如果fmin>fmax 即不管怎样建路径,最后 直径还是大于原先求出的
输出fmin 否则输出fmax
有个更好理解的版本
先求最短路,用Floyd就可以了。
算出所有牧场的直径,记其中最大值为pmax
每个牧区就是一个连通分支,枚举每个点对(a,b)
枚举(a,b)分为位于不同的连通分支,计算连接上以后的形成的新的连通分支的直径,
就是a,b距离再加上a,b分别位于的分支的直径。然后从所有的点对中找到连接以后形
成最小直径的牧区记为pmin。
如果 pmin>pmax那么就要输出pmin,这种情况表示新形成的牧区比原来的所有牧区都大
否则输出pmax
具体见程序
{
ID: xiaweiy1
PROG: cowtour
LANG: PASCAL
}
const maxn=200; //150
var n,i,j,k:longint;
tmp,fmax,fmin,nowmax:extended;
dm:array[1..maxn]of extended;
f:array[1..maxn,1..maxn]of extended;
g:array[1..maxn,1..maxn]of longint;
x,y:array[1..maxn]of longint;
t:char;
function calc(a,b:longint):extended;
var t,p:extended;
begin
t:=(x[a]-x[b])*(x[a]-x[b]);
p:=(y[a]-y[b])*(y[a]-y[b]);
exit(sqrt(t+p));
end;
begin
assign(input,'cowtour.in');
reset(input);
assign(output,'cowtour.out');
rewrite(output);
readln(n);
for i:=1 to n do
begin
readln(x[i],y[i]);
end;
for i:=1 to n do
begin
for j:=1 to n do
begin
read(t); g[i,j]:=ord(t)-ord('0');
if g[i,j]=1 then
f[i,j]:=calc(i,j)
else
f[i,j]:=maxlongint;
end;
readln;
end;
for k:=1 to n do
begin
for i:=1 to n do
begin
if i<>k then
begin
for j:=1 to n do
begin
if (i<>j)and(j<>k) then
begin
if (f[i,k]<>maxlongint)and(f[k,j]<>maxlongint) then
if f[i,k]+f[k,j]<f[i,j] then
f[i,j]:=f[i,k]+f[k,j];
end;
end;
end;
end;
end;
fmax:=0;
for i:=1 to n do
begin
nowmax:=0;
for j:=1 to n do
begin
if i<>j then
begin
if (f[i,j]<>maxlongint)and(f[i,j]>nowmax) then
nowmax:=f[i,j];
end;
end;
dm[i]:=nowmax; //dismax;
if nowmax>fmax then fmax:=nowmax;
end;
fmin:=maxlongint;
for i:=1 to n-1 do
begin
for j:=i+1 to n do
begin
if (i<>j)and(f[i,j]=maxlongint) then
begin
tmp:=calc(i,j);
if dm[i]+dm[j]+tmp<fmin then
fmin:=dm[i]+dm[j]+tmp;
end;
end;
end;
if fmin>fmax then fmax:=fmin;
writeln(fmax:0:6);
close(input);
close(output);
end.

















 1004
1004

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









