







 本文介绍了使用Pytorch构建卷积神经网络(CNN)进行面部表情识别的项目,包括数据可视化、自定义数据集、模型搭建、训练与模型保存。项目涉及数据分离、数据可视化、在Pytorch中创建数据集和重写Dataset类,以及模型训练与评估,最终在给定的7类表情识别任务中达到一定准确率。
本文介绍了使用Pytorch构建卷积神经网络(CNN)进行面部表情识别的项目,包括数据可视化、自定义数据集、模型搭建、训练与模型保存。项目涉及数据分离、数据可视化、在Pytorch中创建数据集和重写Dataset类,以及模型训练与评估,最终在给定的7类表情识别任务中达到一定准确率。
一、项目说明
给定数据集train.csv,要求使用卷积神经网络CNN,根据每个样本的面部图片判断出其表情。在本项目中,表情共分7类,分别为:(0)生气,(1)厌恶,(2)恐惧,(3)高兴,(4)难过,(5)惊讶和(6)中立(即面无表情,无法归为前六类)。所以,本项目实质上是一个7分类问题。


数据集介绍:
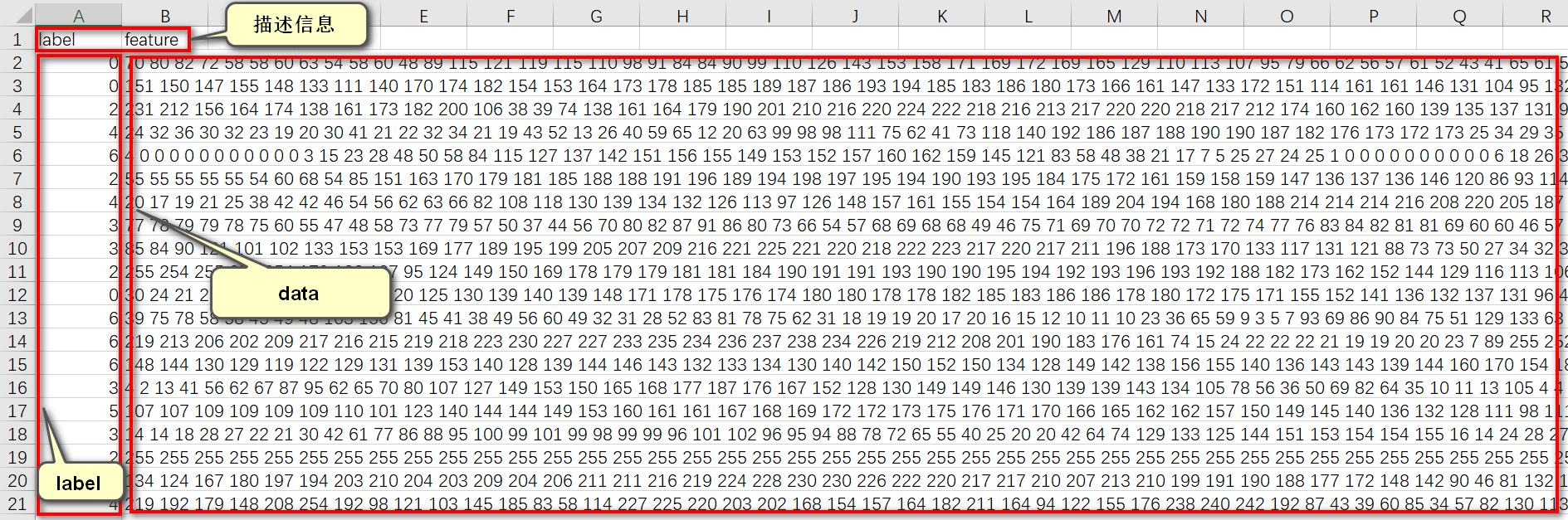
(1)、CSV文件,大小为28710行X2305列;
(2)、在28710行中,其中第一行为描述信息,即“label”和“feature”两个单词,其余每行内含有一个样本信息,即共有28709个样本;
(3)、在2305列中,其中第一列为该样本对应的label,取值范围为0到6。其余2304列为包含着每个样本大小为48X48人脸图片的像素值(2304=48X48),每个像素值取值范围在0到255之间;
(4)、数据集地址:https://pan.baidu.com/s/1hwrq5Abx8NOUse3oew3BXg ,提取码:ukf7 。
二、思路分析及代码实现
给定的数据集是csv格式的,考虑到图片分类问题的常规做法,决定先将其全部可视化,还原为图片文件再送进模型进行处理。
借助深度学习框架Pytorch1.0 CPU(穷逼)版本,搭建模型,由于需用到自己的数据集,因此我们需要重写其中的数据加载部分,其余用现成的API即可。
作业要求使用CNN实现功能,因此基本只能在调参阶段自由发挥(不要鄙视调参,通过这次作业才发现,参数也不是人人都能调得好的,比如我)。
2.1 数据可视化
我们需要将csv中的像素数据还原为图片并保存下来,在python环境下,很多库都能实现类似的功能,如pillow,opencv等。由于笔者对opencv较为熟悉,且opencv又是专业的图像处理库,因此决定采用opencv实现这一功能。
2.1.1 数据分离
原文件中,label和人脸像素数据是集中在一起的。为了方便操作,决定利用pandas库进行数据分离,即将所有label 读出后,写入新创建的文件label.csv;将所有的像素数据读出后,写入新创建的文件data.csv。
1 # 将label和像素数据分离 2 import pandas as pd 3 4 # 修改为train.csv在本地的相对或绝对地址 5 path = './/ml2019spring-hw3//train.csv' 6 # 读取数据 7 df = pd.read_csv(path) 8 # 提取label数据 9 df_y = df[['label']] 10 # 提取feature(即像素)数据 11 df_x = df[['feature']] 12 # 将label写入label.csv 13 df_y.to_csv('label.csv', index=False, header=False) 14 # 将feature数据写入data.csv 15 df_x.to_csv('data.csv', index=False, header=False)
以上代码执行完毕后,在该代码脚本所在的文件夹下,就会生成两个新文件label.csv以及data.csv。在执行代码前,注意修改train.csv在本地的路径。
2.1.2 数据可视化
将数据分离后,人脸像素数据全部存储在data.csv文件中,其中每行数据就是一张人脸。按行读取数据,利用opencv将每行的2304个数据恢复为一张48X48的人脸图片,并保存为jpg格式。在保存这些图片时,将第一行数据恢复出的人脸命名为0.jpg,第二行的人脸命名为1.jpg......,以方便与label[0]、label[1]......一一对应。
1 import cv2 2 import numpy as np 3 4 # 指定存放图片的路径 5 path = './/face' 6 # 读取像素数据 7 data = np.loadtxt('data.csv') 8 9 # 按行取数据 10 for i in range(data.shape[0]): 11 face_array = data[i, :].reshape((48, 48)) # reshape 12 cv2.imwrite(path + '//' + '{}.jpg'.format(i), face_array) # 写图片
以上代码虽短,但涉及到大量数据的读取和大批图片的写入,因此占用的内存资源较多,且执行时间较长(视机器性能而定,一般要几分钟到十几分钟不等)。代码执行完毕,我们来到指定的图片存储路径,就能发现里面全部是写好的人脸图片。
粗略浏览一下这些人脸图片,就能发现这些图片数据来源较广,且并不纯净。就前60张图片而言,其中就包含了正面人脸,如1.jpg;侧面人脸,如18.jpg;倾斜人脸,如16.jpg;正面人头,如7.jpg;正面人上半身,如55.jpg;动漫人脸,如38.jpg;以及毫不相关的噪声,如59.jpg。放大图片后仔细观察,还会发现不少图片上还有水印。种种因素均给识别提出了严峻的挑战。

2.2 在pytorch下创建数据集
现在我们有了图片,但怎么才能把图片读取出来送给模型呢?
最简单粗暴的方法就是直接用opencv将所有图片读取出来,以numpy中array的数据格式直接送给模型。如果这样做的话,会一次性把所有图片全部读入内存,占用大量的内存空间,且只能使用单线程,效率不高,也不方便后续操作。
其实在pytorch中,有一个类(torch.utils.data.Dataset)是专门用来加载数据的,我们可以通过继承这个类来定制自己的数据集和加载方法。以下为基本流程。
2.2.1 创建data-label对照表
首先,我们需要划分一下训练集和验证集。在本次作业中,共有28709张图片,取前24000张图片作为训练集,其他图片作为验证集。新建文件夹train和val,将0.jpg到23999.jpg放进文件夹train,将其他图片放进文件夹val。
在继承torch.utils.data.Dataset类定制自己的数据集时,由于在数据加载过程中需要同时加载出一个样本的数据及其对应的label,因此最好能建立一个data-label对照表,其中记录着data和label的对应关系(“data-lable对照表”并非官方名词,这个技术流程是笔者参考了他人的博客后自己摸索的,这个名字也是笔者给命的名)。
有童鞋看到这里就会提出疑问了:在人脸可视化过程中,每张图片的命名不都和label的存放顺序是一一对应关系吗,为什么还要多此一举,再重新建立data-label对照表呢?笔者在刚开始的时候也是这么想的,按顺序(0.jpg, 1.jpg, 2.jpg......)加载图片和label(label[0], label[1], label[2]......),岂不是方便、快捷又高效?结果在实际操作的过程中才发现,程序加载文件的机制是按照文件名首字母(或数字)来的,即加载次序是0,1,10,100......,而不是预想中的0,1,2,3......,因此加载出来的图片不能够和label[0],label[1],lable[2],label[3]......一一对应,所以建立data-label对照表还是相当有必要的。
建立data-label对照表的基本思路就是:指定文件夹(train或val),遍历该文件夹下的所有文件,如果该文件是.jpg格式的图片,就将其图片名写入一个列表,同时通过图片名索引出其label,将其label写入另一个列表。最后利用pandas库将这两个列表写入同一个csv文件。
执行这段代码前,注意修改相关文件路径。代码执行完毕后,会在train和val文件夹下各生成一个名为dataset.csv的data-label对照表。
1 import os 2 import pandas as pd 3 4 def data_label(path): 5 # 读取label文件 6 df_label = pd.read_csv('label.csv', header = None) 7 # 查看该文件夹下所有文件 8 files_dir = os.listdir(path) 9 # 用于存放图片名 10 path_list = [] 11 # 用于存放图片对应的label 12 label_list = [] 13 # 遍历该文件夹下的所有文件 14 for file_dir in files_dir: 15 # 如果某文件是图片,则将其文件名以及对应的label取出,分别放入path_list和label_list这两个列表中 16 if os.path.splitext(file_dir)[1] == ".jpg": 17 path_list.append(file_dir) 18 index = int(os.path.splitext(file_dir)[0]) 19 label_list.append(df_label.iat[index, 0]) 20 21 # 将两个列表写进dataset.csv文件 22 path_s = pd.Series(path_list) 23 label_s = pd.Series(label_list) 24 df = pd.DataFrame() 25 df['path'] = path_s 26 df['label'] = label_s 27 df.to_csv(path+'\\dataset.csv', index=False, header=False) 28 29 30 def main(): 31 # 指定文件夹路径 32 train_path = 'F:\\0gold\\ML\\LHY_class\\FaceData\\train' 33 val_path = 'F:\\0gold\\ML\\LHY_class\\FaceData\\val' 34 data_label(train_path) 35 data_label(val_path) 36 37 if __name__ == "__main__": 38 main()
OK,代码执行完毕,让我们来看一看data-label对照表里面具体是什么样子吧!

2.2.2 重写Dataset类
首先介绍一下Pytorch中Dataset类:Dataset类是Pytorch中图像数据集中最为重要的一个类,也是Pytorch中所有数据集加载类中应该继承的父类。其中父类中的两个私有成员函数getitem()和len()必须被重载,否则将会触发错误提示。其中getitem()可以通过索引获取数据,len()可以获取数据集的大小。在Pytorch源码中,Dataset类的声明如下:
1 class Dataset(object): 2 """An abstract class representing a Dataset. 3 4 All other datasets should subclass it. All subclasses should override 5 ``__
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









