



第一部分:
请分析作业页面,爬取已提交作业信息,并生成已提交作业名单,保存为英文逗号分隔的csv文件。文件名为:
hwlist.csv 。
文件内容范例如下形式:
学号,姓名,作业标题,作业提交时间,作业URL
20194010101,张三,羊车门作业,2018-11-13 23:47:36.8,
http://www.cnblogs.com/sninius/p/12345678.html
20194010102,李四,羊车门,2018-11-14 9:38:27.03,
http://www.cnblogs.com/sninius/p/87654321.html
*注1:如制作定期爬去作业爬虫,请注意爬取频次不易太过密集;
*注2:本部分作业用到部分库如下所示:
(1)requests —— 第3方库
(2)json —— 内置库
第二部分:
在生成的 hwlist.csv 文件的同文件夹下,创建一个名为 hwFolder 文件夹,为每一个已提交作业的同学,新建一个以该生学号命名的文件夹,将其作业网页爬去下来,并将该网页文件存以学生学号为名,“.html”为扩展名放在该生学号文件夹中。
第一部分:大体没有问题
第二部分:爬下来的网页没有格式和图片
import requests import json import os def GetHTMLText(url): try: r=requests.get(url) r.raise_for_status() r.encoding=r.apparent_encoding return r.text except: return "产生异常" def MakeHTML(s,url): #将网页保存到本地 responces = requests.get(url) responces.encoding=responces.apparent_encoding file = open(s+'.html','w',encoding='UTF-8') file.write(responces.text) file.close() if __name__=="__main__": url='https://edu.cnblogs.com/Homework/GetAnswers?homeworkId=2420&_=1543321336479' json_data=json.loads(GetHTMLText(url)) datas=json_data['data'] information='' for data in datas: information+=str(data['StudentNo'])+','+data['RealName']+','+data['DateAdded'].replace('T',' ')+','+data['Url']+'\n' with open('F://hwlist.csv','w') as f: f.write(information) os.makedirs('F://hwFolder')#创建目录 os.chdir('F://hwFolder')#转到这个目录下面 for num in datas: os.makedirs(str(num['StudentNo']))#创建一个以学号命名的目录 os.chdir('F://hwFolder//'+str(num['StudentNo']))#转到这个目录下面 MakeHTML(str(num['StudentNo']),num['Url'])#开始把网页弄到本地 os.chdir('F://hwFolder')#转回 hwFolder 目录下
第一部分:
现状
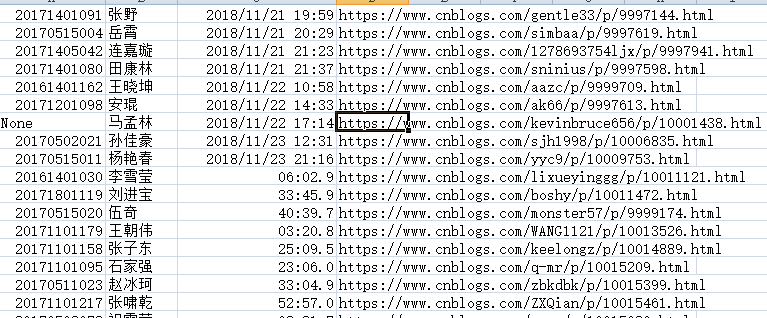
问题:::日期那里的格式好像有问题(暂未处理)
第二部分
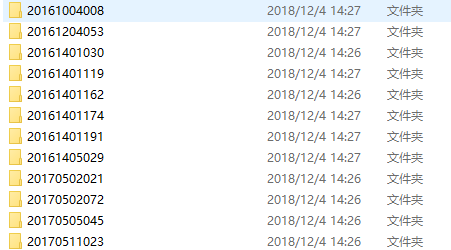

网页基本样子是这样的

问题:::没有格式 没有图片 (暂未处理)
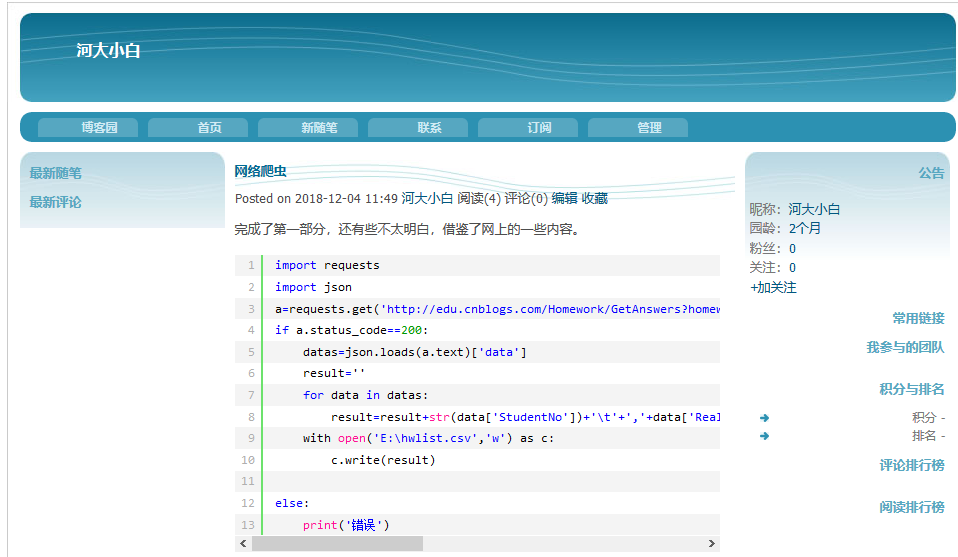
与原网页对比差距有点大。。。。。。。。

















 995
995

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









