



 本文详细介绍了使用神经网络对手写数字图片进行识别的过程,包括图片预处理、模型预测及结果输出。通过具体代码示例,展示了如何从输入真实图片到获取预测结果的完整流程。
本文详细介绍了使用神经网络对手写数字图片进行识别的过程,包括图片预处理、模型预测及结果输出。通过具体代码示例,展示了如何从输入真实图片到获取预测结果的完整流程。
a)如何输入真实图片,输出预测结果
b)制作数据集,实现特定应用
1 真实图片输入-输出逻辑关系
首先我们需要了解输入-输出的过程
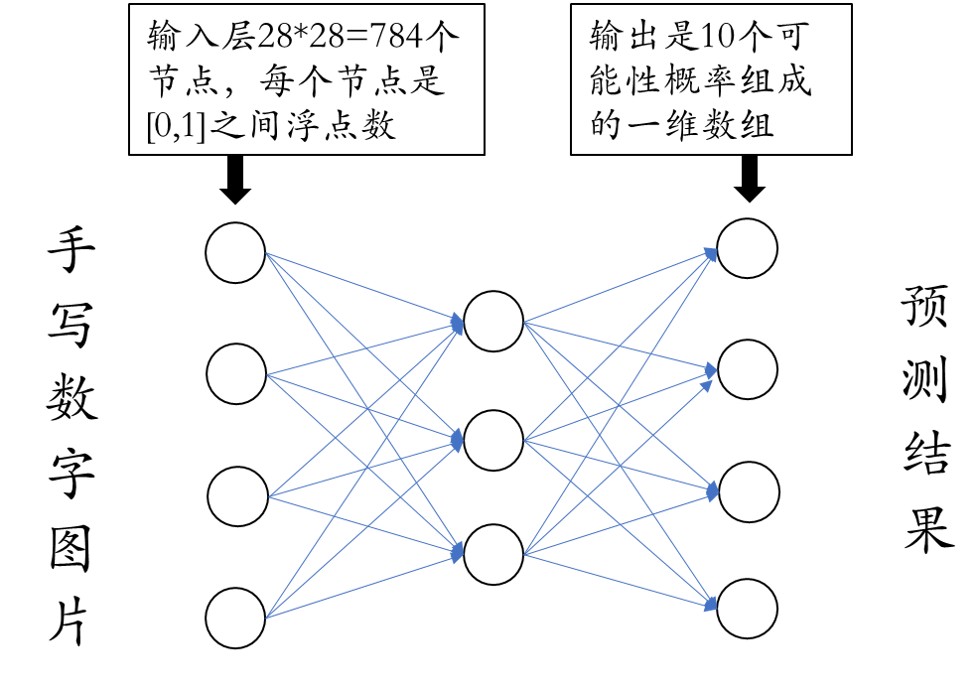
注:
1)每个像素点的值是 [0,1] 之间的浮点数。越接近 0 越黑,越接近 1 越白。
2)输出值中最大元素对应的索引号就是预测的结果。

将两个任务分为两个函数解决,先将数字图片 testPic 做预处理,当图片符合神经网络输入要求后,再将其喂给复现的神经网络模型,最后输出预测值 preValue。
def application(): testNum = input("input the number of test pictures:") for i in range(testNum): testPic = raw_input("the path of test picture:") # 对手写数字图片testPic做预处理 testPicArr = pre_pic(testPic) # 将符合神经网络输入要求的图片喂给复现的神经网络模型,输出预测值 preValue = restore_model(testPicArr) print("The prediction number is:", preValue)
2 真实图片输入-输出代码示例
该段代码中增加了应用程序 mnist_app.py,其他代码与 神经网络优化(三) - 全连接网络基础 相同
- 前向传播 mnist_forward.py
- 反向传播 mnist_backward.py
- 测试程序 mnist_test.py
- 应用程序 mnist_app.py
2.1 mnist_app.py 文件
其中 mnist_app.py 文件内容如下
# coding:utf-8 import tensorflow as tf import numpy as np from PIL import Image import mnist_backward import mnist_forward def restore_model(testPicArr): # with 语句重现计算图 with tf.Graph().as_default() as tg: # x 占位 x = tf.placeholder(tf.float32, [None, mnist_forward.INPUT_NODE]) # 计算求得输出y y = mnist_forward.forward(x, None) # y的最大值对应的索引号就是预测结果preValue preValue = tf.argmax(y, 1) # 实例化具有滑动平均值的 saver variable_averages = tf.train.ExponentialMovingAverage(mnist_backward.MOVING_AVERAGE_DECAY) variables_to_restore = variable_averages.variables_to_restore() saver = tf.train.Saver(variables_to_restore) # 创建会话 with tf.Session() as sess: # 加载ckpt ckpt = tf.train.get_checkpoint_state(mnist_backward.MODEL_SAVE_PATH) # 如果ckpt存在,则恢复ckpt中w、b等参数信息到当前会话 if ckpt and ckpt.model_checkpoint_path: saver.restore(sess, ckpt.model_checkpoint_path) # 将刚准备好的testPicArr待识别图片喂入网络 # 执行预测操作 preValue = sess.run(preValue, feed_dict={x: testPicArr}) return preValue else: # 若无ckpt,则给出提示 print("No checkpoint file found") return -1 def pre_pic(picName): # 打开 pic,形成 img 资源句柄 img = Image.open(picName) # ANTIALIAS是消除锯齿的方法进行 resize reIm = img.resize((28,28), Image.ANTIALIAS) # 为符合模型对颜色的要求,用 convert函数将其变为灰度图 # 最后用array将其转为矩阵 im_arr = np.array(reIm.convert('L')) # 纯白色/纯黑色界限值,可以适当调整 threshold = 50 # 由于模型要求的是黑底白字,而图片是白底黑字,故将图片像素值反转 # for 循环语句双层循环,逐一像素反转 for i in range(28): for j in range(28): im_arr[i][j] = 255 - im_arr[i][j] if (im_arr[i][j] < threshold): # 对像素点进行二值化处理,使得图片只有纯白色点和纯黑色点 # 过滤点图片中的噪点,留下图片的主要特征 # 小于threshold赋为纯黑色0 im_arr[i][j] = 0 # 大于threshold赋为纯白色255 else: im_arr[i][j] = 255 # 将im_arr整理形状--> 1 行 784 列 nm_arr = im_arr.reshape([1, 784]) # 由于模型要求像素点值为0-1之间的浮点数,故将其变为浮点型 nm_arr = nm_arr.astype(np.float32) # 将图片的0-255之间的数变为0-1之间的数 # 经过以上操作,图片的格式就满足模型要求了 img_ready = np.multiply(nm_arr, 1.0/255.0) # 返回整理好的图片值img_ready return img_ready def application(): # input函数实现从控制台输入图片的数量 testNum = input("input the number of test pictures:") for i in range(testNum): # raw_input函数可以实现从控制台读入图片路径字符串,如pic/01.png testPic = raw_input("the path of test picture:") # 由于是使用的已有模型,所以对输入图片要求较为严格,先对图片进行预处理 testPicArr = pre_pic(testPic) # 将整理好的图片喂入模型中 preValue = restore_model(testPicArr) # 打印预测结果 print("The prediction number is:", preValue) def main(): application() if __name__ == '__main__': main()
注意
1)main 函数中的 application 函数:输入要识别的几张图片(注意要给出待识别图片的路径和名称)。
2)代码处理过程:
- 模型的要求是黑底白字,但输入的图是白底黑字,所以需要对每个像素点的值改为 255 减去原值以得到互补的反色。
- 对图片做二值化处理(这样以滤掉噪声,另外调试中可适当调节阈值)。
3)把图片形状拉成 1 行 784 列,并把值变为浮点型(因为要求像素点是 0-1之间的浮点数)。
4)接着让现有的 RGB 图从 0-255 之间的数变为 0-1 之间的浮点数。
5)运行完成后返回到 main 函数。
6)计算求得输出 y,y 的最大值所对应的列表索引号就是预测结果。
2.2 运行

















 617
617

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









