






 本文介绍了一个简单的文本处理程序,该程序能够读取文件内容,并统计其中各个单词出现的频率,最后输出出现频率最高的十个单词。
本文介绍了一个简单的文本处理程序,该程序能够读取文件内容,并统计其中各个单词出现的频率,最后输出出现频率最高的十个单词。
胡伟业
2017035107065
程序分析说明
1.读文件到缓冲区
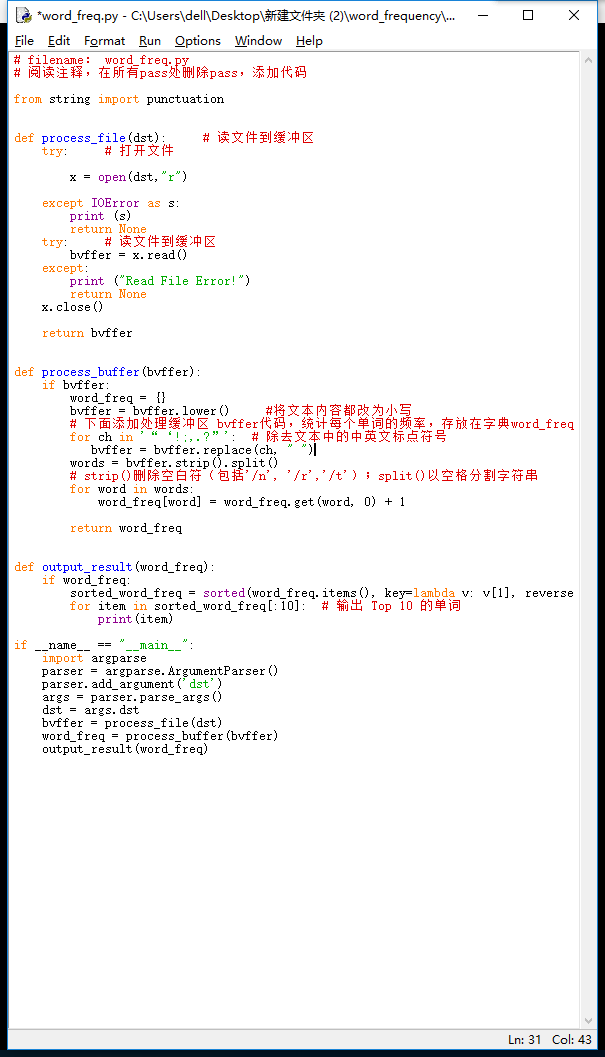
def process_file(dst):
try:
x = open(dst,"r")
except IOError as s:
print (s)
return None
try:
bvffer = x.read()
except:
print ("Read File Error!")
return None
x.close()
return bvffer
2.下面添加处理缓冲区 bvffer代码,统计每个单词的频率,存放在字典word_freq
def process_buffer(bvffer):
if bvffer:
word_freq = {}
bvffer = bvffer.lower()
for ch in '“‘!;,.?”':
bvffer = bvffer.replace(ch, " ")
words = bvffer.strip().split()
for word in words:
word_freq[word] = word_freq.get(word, 0) + 1
return word_freq
3.输出top10的词
def output_result(word_freq):
if word_freq:
sorted_word_freq = sorted(word_freq.items(), key=lambda v: v[1], reverse=True)
for item in sorted_word_freq[:10]:
print(item)
if __name__ == "__main__":
import argparse
parser = argparse.ArgumentParser()
parser.add_argument('dst')
args = parser.parse_args()
dst = args.dst
bvffer = process_file(dst)
word_freq = process_buffer(bvffer)
output_result(word_freq)
性能分析结果及改进情况
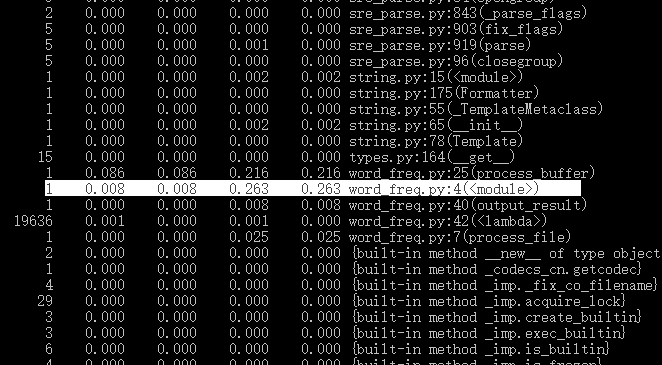
执行时间最长
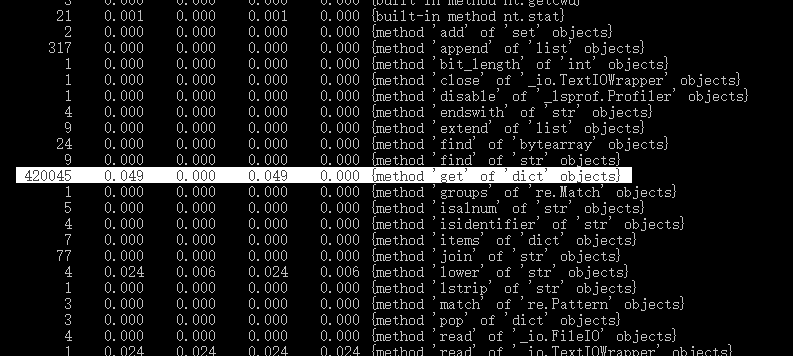
执行次数最多
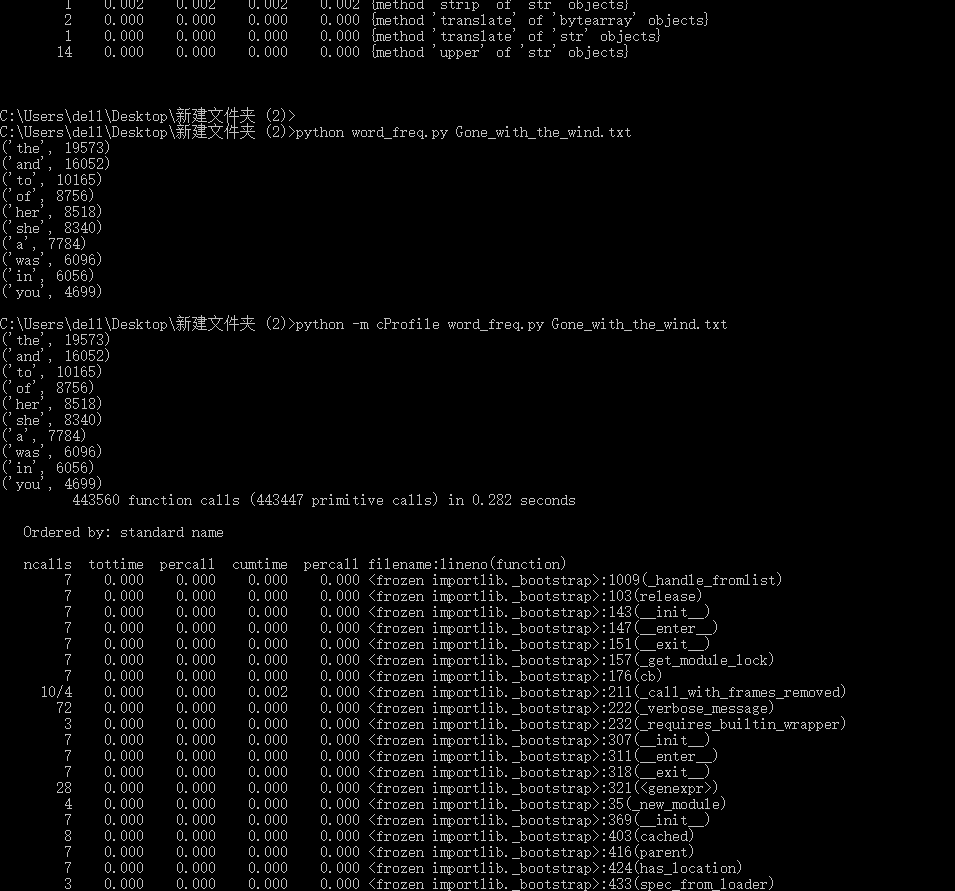
程序运行命令、结果截图
总结反思
这次的作业,我在同学的帮助下完成了这次的作业,从刚开始的 啥也看不懂,到可以看懂,感觉含有成就感,但我感觉还我还有许多的不足,对python的其他使用还不是很了解,还需要学习。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









