






 Uniprot数据库,作为全球最大的蛋白质资源库,分为高质量的手工注释数据集Swiss-Prot和计算分析结果数据集TrEMBL。博客详细介绍了如何通过Entry、Entryname、Proteinnames等字段搜索和理解蛋白质信息。
Uniprot数据库,作为全球最大的蛋白质资源库,分为高质量的手工注释数据集Swiss-Prot和计算分析结果数据集TrEMBL。博客详细介绍了如何通过Entry、Entryname、Proteinnames等字段搜索和理解蛋白质信息。
Uniprot数据库是Universal Protein的英文缩写,是信息最丰富、资源最广的蛋白质数据库。
UniprotKB由两部分组成:
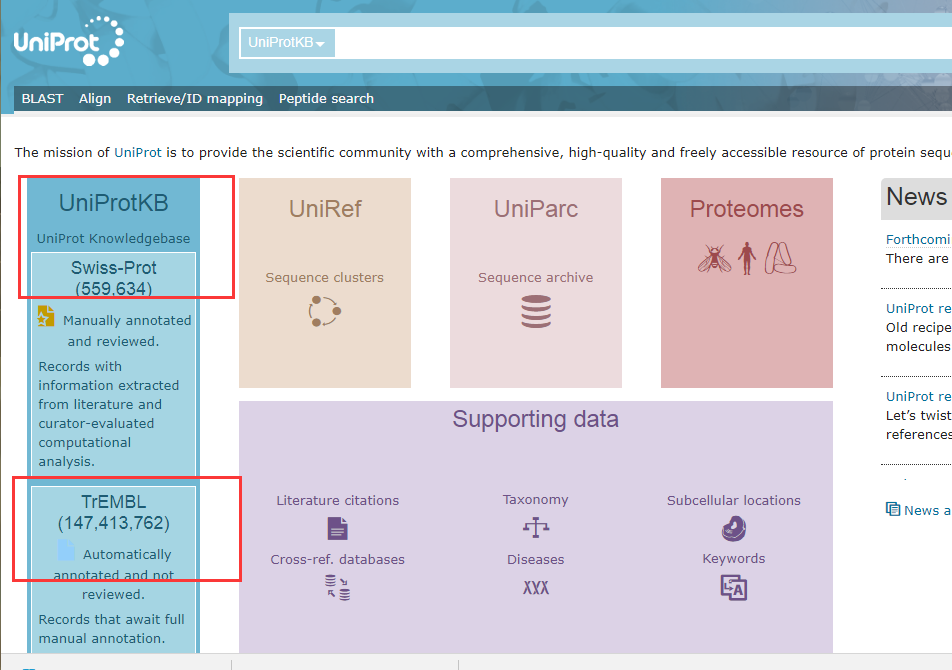
UniProtKB/Swiss-Prot
高质量的、手工注释的、非冗余的数据集,这些数据都是由质量保证的。
UniProtKB/TrEMBL
该数据集包含高质量的计算分析结果,需要我们手工注释。
当我们搜索蛋白质时,就会如下显示多个蛋白质的信息:
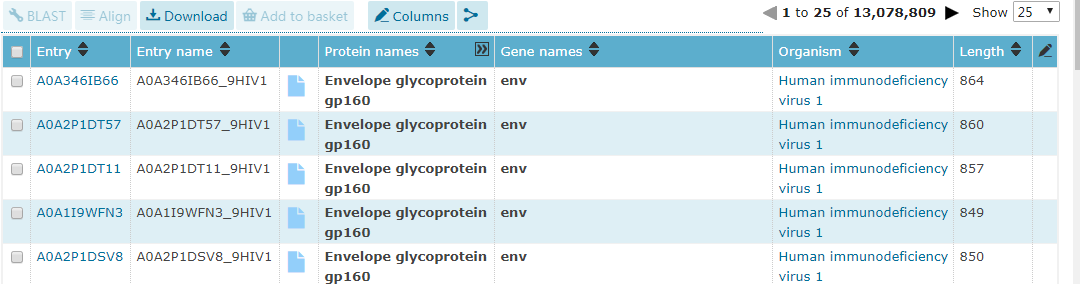
Entry:是Uniprot给每个蛋白质赋予的独一无二的ID
Entry name:是蛋白ID的简要名字
Protein names:蛋白质的名字
Gene names:编码这个蛋白的Gene名字
Organism:蛋白质的种属来源
Length:氨基酸长度

















 1239
1239

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









