



 本文详细介绍了使用Python的Pandas库进行数据处理的方法,包括如何用二维列表构造原始数据,将数据转换为DataFrame类型,以及如何进行数据索引、创建新列和分组汇总等高级操作。
本文详细介绍了使用Python的Pandas库进行数据处理的方法,包括如何用二维列表构造原始数据,将数据转换为DataFrame类型,以及如何进行数据索引、创建新列和分组汇总等高级操作。
- 用二维列表构造原始数据
1 import pandas as pd
2
3 data = [['li', 'math', 100], ['bob', 'pe', 99], ['sar', 'english', 98], ['li', 'pe', 89]]
- 将数据转换成DataFrame类型
1 import pandas as pd
2
3 dataFrame = pd.DataFrame(dada, columns = ['name', 'course', 'score']) # columns 为列名 并且必须是list类型
- 打印dataFrame对象
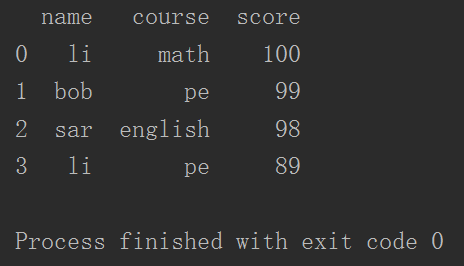
- 此时不能根据行号索引,但是可以根据列名索引
1 import pandas as pd
2
3 print(dataFrame[0])

1 import pandas as pd
2
3 print(dataFrame["name"])
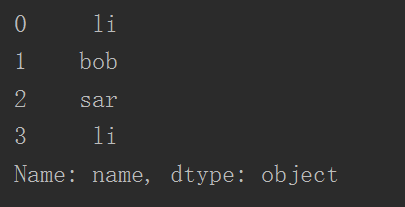
- 此时的dataFrame["name"] 是一个类似于一维数组的series对象,可根据下标索引
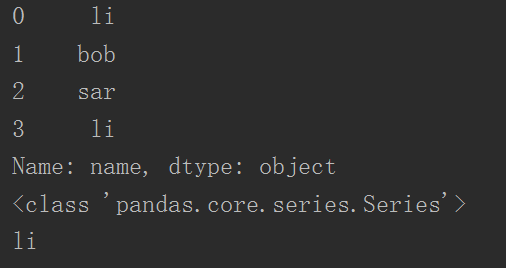
1 import pandas as pd 2 3 print(dataFrame["name"])
4 print(type(dataFrame["name"]))
5 print(dataFrame["name"][0])
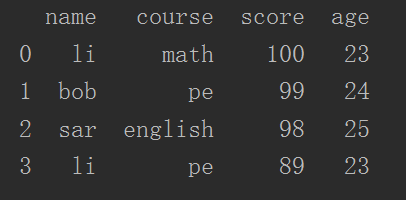
- 像字典一样用索引创建新列 dataFrame["age"]
1 import pandas as pd
2
3 dataFrame["age"] = [23, 24, 25, 23]
4 print(dataFrame)
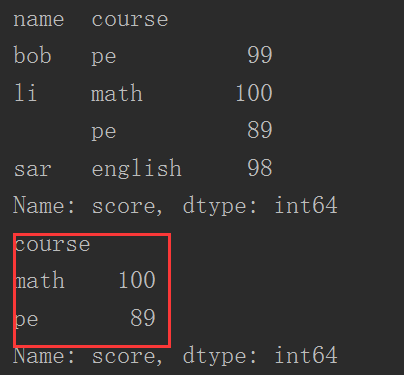
- 重点来了,dataFrame.groupby("name")根据name属性分组,name列数据项默认成为索引
1 import pandas as pd
2
3 dataFrame = dataFrame.groupby(["name", "course"])["score"].sum() # 可以通过as_index指定分组项要不要成为索引, 默认为True
4 print(dataFrame)
5 print(dataFrame["li"])

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









