



1.运行如下代码时,为何会出现如下结果?

运行结果:[Ljava.lang.Object;@2a139a55
解释:因为数组内的数据类型不一致。这里是自己定义的数组,数组元素是引用类型,使用之前必须先创建特定对象。对于数组元素是引用类型的数组,在访问数组中对象之前,需要创建相应的对象并让数组元素引用它!
2.有如下代码,观察并分析结果。
1 // PassArray.java 2 // Passing arrays and individual array elements to methods 3 4 public class PassArray { 5 6 public static void main(String[] args) { 7 int a[] = { 1, 2, 3, 4, 5 }; 8 String output = "The values of the original array are:\n"; 9 10 for (int i = 0; i < a.length; i++) 11 output += " " + a[i]; 12 13 output += "\n\nEffects of passing array " + "element call-by-value:\n" 14 + "a[3] before modifyElement: " + a[3]; 15 16 modifyElement(a[3]); 17 18 output += "\na[3] after modifyElement: " + a[3]; 19 20 output += "\n Effects of passing entire array by reference"; 21 22 modifyArray(a); // array a passed call-by-reference 23 24 output += "\n\nThe values of the modified array are:\n"; 25 26 for (int i = 0; i < a.length; i++) 27 output += " " + a[i]; 28 29 System.out.println(output); 30 } 31 32 public static void modifyArray(int b[]) { 33 for (int j = 0; j < b.length; j++) 34 b[j] *= 2; 35 } 36 37 public static void modifyElement(int e) { 38 e *= 2; 39 } 40 41 }
解释:这里是两种传参的方法。按引用传递与按值传送数组类型方法参数的最大关键在于:使用前者时,如果方法中有代码更改了数组元素的值,实际上是直接修改了原始的数组元素。使用后者则没有这个问题,方法体中修改的仅是原始数组元素的一个拷贝。
3.以下代码的输出结果是什么?为什么会有这个结果?
1 int[] a = {5, 7 , 20}; 2 int[] b = new int[4]; 3 System.out.println("b数组的长度为:" + b.length); 4 b = a; 5 System.out.println("b数组的长度为:" + b.length); 6 测试用代码:ArrayInRam.java
解释:第一个值为4,第二个值为3。因为a是int[]类型,b也是int[]类型,所以可以将a的值赋给b。也就是让b引用指向a引用指向的数组。对象赋值,不是赋的值,赋的是地址。a的地址赋值给b了。
4.阅读下列程序, 解释程序所完成的功能。
1 public class WhatDoesThisDo { 2 static int result; 3 static String output; 4 5 public static void main(String[] args) { 6 int a[] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 }; 7 result = whatIsThis(a, a.length); 8 output = "Result is: " + result; 9 System.out.println(output); 10 } 11 12 public static int whatIsThis(int b[], int size) { 13 if (size == 1) 14 return b[0]; 15 else 16 return b[size - 1] + whatIsThis(b, size - 1); 17 } 18 }
解释:程序通过迭代的方法,利用数组,实现1到10的累加和。
5.阅读下列程序, 解释程序所完成的功能。
1 public class WhatDoesThisDo2 { 2 public static void main(String[] args) { 3 int a[] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 }; 4 StringBuilder sbBuilder=new StringBuilder(); 5 someFunction(a, 0, sbBuilder); 6 System.out.println(sbBuilder); 7 } 8 public static void someFunction(int b[], int x, StringBuilder out) { 9 if (x < b.length) { 10 someFunction(b, x + 1, out); 11 out.append(b[x] + " "); 12 } 13 } 14 }
解释:StringBuilder的作用:如果要修改字符串而不创建新的对象,则可以使用System.Text.StringBuilder类。append的作用:连接一个字符串到末尾。此处用了迭代的方式,实现了数组元素的倒置。
6.请编写一个程序将一个整数转换为汉字读法字符串。比如“1123”转换为“壹千壹百贰十叁”。
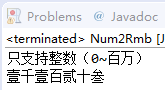
1 public class Num2Rmb 2 { 3 private String[] hanArr = {"零" , "壹" , "贰" , "叁" , "肆" , 4 "伍" , "陆" , "柒" , "捌" , "玖"}; 5 private String[] unitArr = {"十" , "百" , "千","万","十万","百万"}; 6 7 private String toHanStr(String numStr) 8 { 9 String result = ""; 10 int numLen = numStr.length(); 11 //依次遍历数字字符串的每一位数字 12 for (int i = 0 ; i < numLen ; i++ ) 13 { 14 //把char型数字转换成的int型数字,因为它们的ASCII码值恰好相差48 15 //因此把char型数字减去48得到int型数字,例如'4'被转换成4。 16 int num = numStr.charAt(i) - 48; 17 //如果不是最后一位数字,而且数字不是零,则需要添加单位(千、百、十) 18 if ( i != numLen - 1 && num != 0) 19 { 20 result += hanArr[num] + unitArr[numLen - 2 - i]; 21 } 22 //否则不要添加单位 23 else 24 { 25 26 //上一个数是否为“零”,不为“零”时就添加 27 if(result.length()>0 && hanArr[num].equals("零") && result.charAt(result.length()-1)=='零') 28 continue; 29 result += hanArr[num]; 30 } 31 } 32 //只有个位数,直接返回 33 if(result.length()==1) 34 return result; 35 36 int index=result.length()-1; 37 while(result.charAt(index)=='零'){ 38 index--; 39 } 40 if(index!=result.length()-1) 41 return result.substring(0,index+1); 42 else { 43 return result; 44 } 45 } 46 47 public static void main(String[] args) 48 { 49 Num2Rmb nr = new Num2Rmb(); 50 System.out.println("只支持整数(0~百万)"); 51 //测试把一个四位的数字字符串变成汉字字符串 52 System.out.println(nr.toHanStr("1123")); 53 } 54 }
结果:
7.随机生成10个数,填充一个数组,然后用消息框显示数组内容,接着计算数组元素的和,将结果也显示在消息框中。
程序代码:
1 import java.util.*; 2 public class Add10 { 3 public static void main(String[] args) { 4 int[] number=new int [10]; 5 int sum=0; 6 for(int i=0;i<number.length;i++) 7 { 8 number[i]=new Random().nextInt(10) + 1; 9 int k=i+1; 10 System.out.println("第"+k+"个数组元素为"+number[i]); 11 } 12 for(int i=0;i<number.length;i++) 13 { 14 sum+=number[i]; 15 } 16 System.out.println("十个数之和为:"+sum); 17 } 18 19 }
结果截图:


















 522
522

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









