



如图所示:
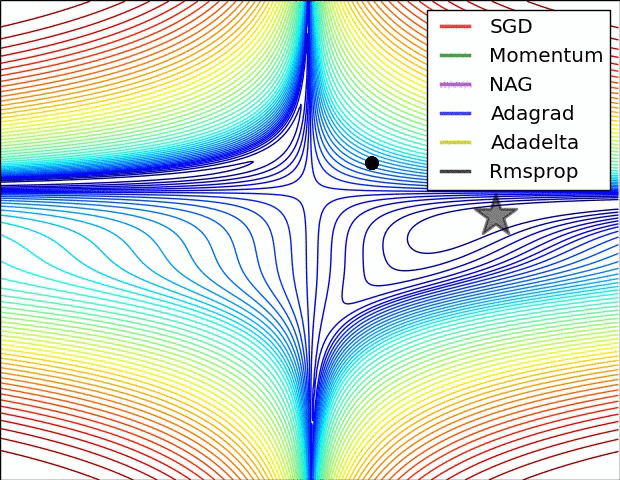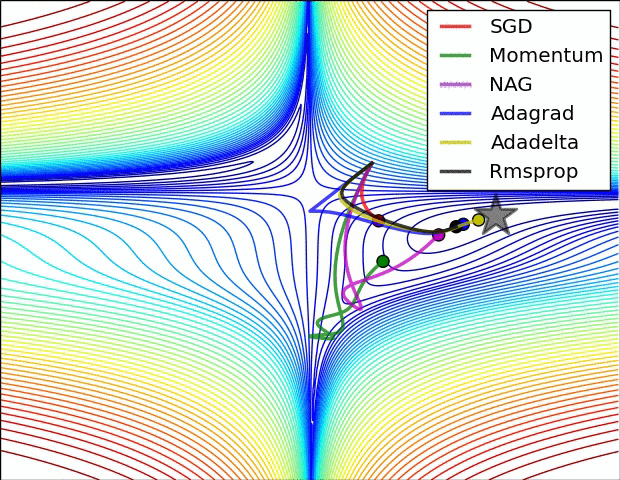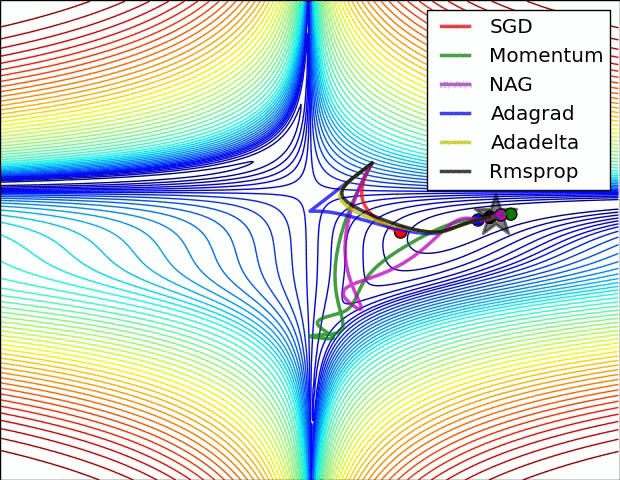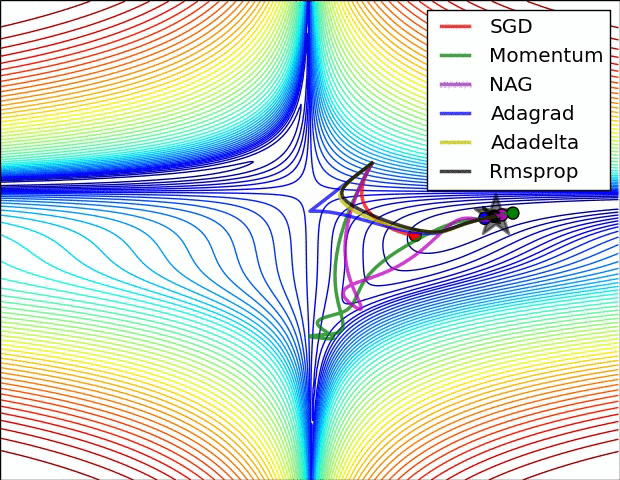
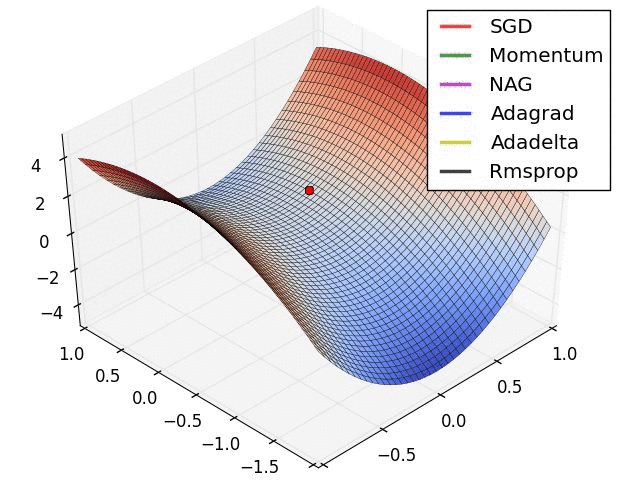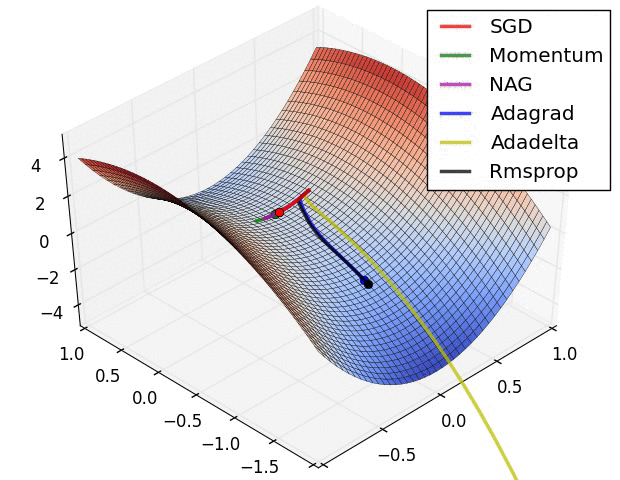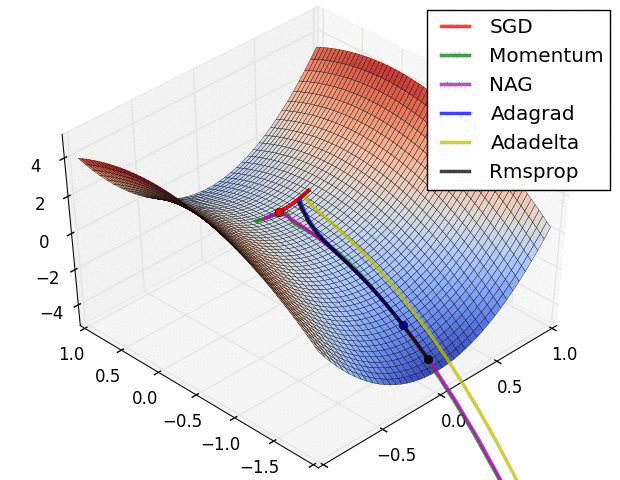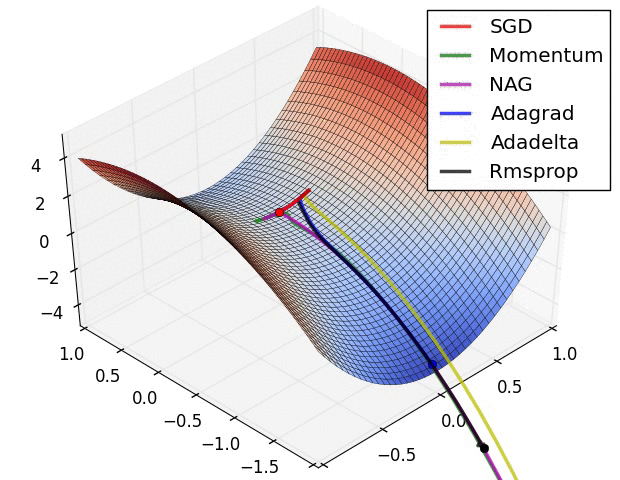
经验之谈
对于稀疏数据,尽量使用学习率可自适应的优化方法,不用手动调节,而且最好采用默认值
SGD通常训练时间更长,但是在好的初始化和学习率调度方案的情况下,结果更可靠
如果在意更快的收敛,并且需要训练较深较复杂的网络时,推荐使用学习率自适应的优化方法。
Adadelta,RMSprop,Adam是比较相近的算法,在相似的情况下表现差不多。
在想使用带动量的RMSprop,或者Adam的地方,大多可以使用Nadam取得更好的效果
参考
1. https://blog.youkuaiyun.com/fengchao03/article/details/78208414
2. https://blog.youkuaiyun.com/g11d111/article/details/76639460

















 8663
8663

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









