






 报表项目中数据源常来自多种异构数据源,传统 ETL 方式配置复杂、成本高、数据无法实时访问等。而润乾报表可简单直接实现混合数据源报表,通过内置集算引擎读取数据源,以较小成本呈现实时报表。文中以《州销售人员销售报表》为例介绍了具体实现步骤。
报表项目中数据源常来自多种异构数据源,传统 ETL 方式配置复杂、成本高、数据无法实时访问等。而润乾报表可简单直接实现混合数据源报表,通过内置集算引擎读取数据源,以较小成本呈现实时报表。文中以《州销售人员销售报表》为例介绍了具体实现步骤。
在报表项目中,报表数据源常常会来自于多种异构数据源,例如:关系型数据库(oracle、db2、mysql)、nosql 数据库(mongodb)、http 数据源、hadoop(hive、hdfs),甚至是 excel 或者文本文件。针对这类情况,通常的做法是采用 ETL 工具,将这些数据源都同步到数据仓库中再进行计算。不过这种做法存在以下问题:
1、配置复杂,难度较大;
2、成本较高;
3、数据无法实时访问,时间延迟较长;
4、数据仓库的建设和管理都比较复杂;
5、如果数据量很大效率会很低,而且要不断的 ETL 各个应用系统的同步数据;
6、数据仓库利用的也是传统数据库的技术,负载增大的时候需要用较高的成本进行扩容。
和这种传统做法相比,采用润乾报表可以简单直接地实现混合数据源报表,具体做法是通过内置的集算引擎直接读取各种混合数据源,让数据采用最合适的方式存储,最终以较小的成本呈现基于混合数据源的实时报表。ETL 方式和润乾报表方式在体系结构上的对比如下图所示:
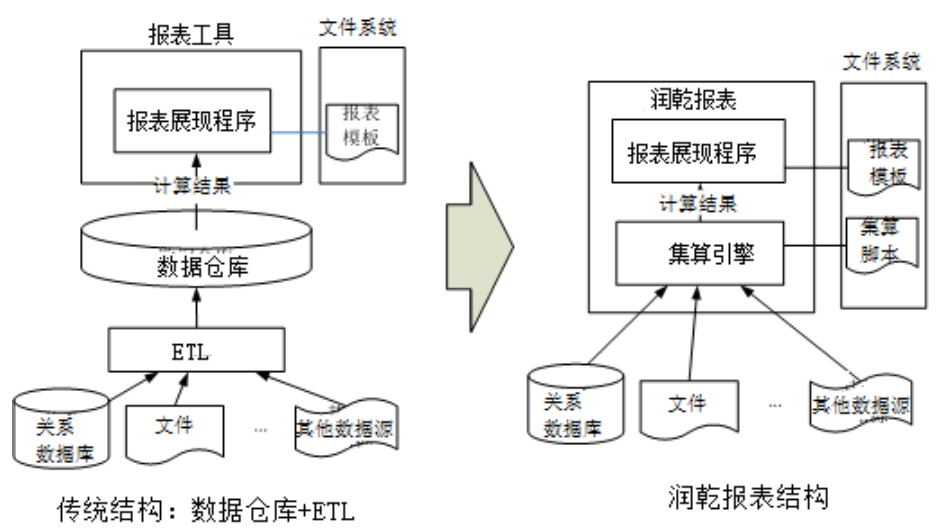
下面,通过《州销售人员销售报表》的设计制作来看一下具体的实现步骤。报表如下图:
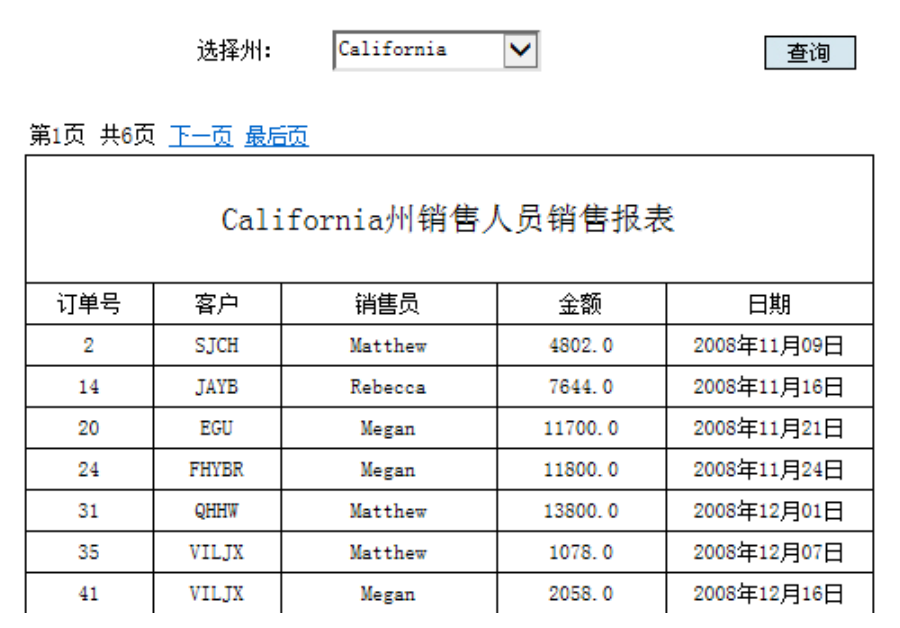
报表的销售数据来自于销售系统的 mongodb 数据库,销售员的信息则来自人力资源系统的 db2 数据库。采用润乾报表的混合数据源方式,报表数据源不需要定期同步,不会有时间上的延迟。
第一步,在集算器设计器中编写脚本,并保存为 statesales.dfx,脚本内容如下:
| A | |
|---|---|
| 1 | >hrdb=connect(“db22”) |
| 2 | =hrdb.query(“select * from employee where state=?”,state) |
| 3 | =mongodb(“mongo://localhost:27017/test?user=test&password=test”) |
| 4 | =A3.find(“orders”,,“{_id:0}”).fetch() |
| 5 | =A4.switch@i(SELLERID,A2:EID) |
| 6 | =A5.new(ORDERID,CLIENT,SELLERID.NAME:SELLERNAME,AMOUNT,ORDERDATE) |
| 7 | >hrdb.close() |
| 8 | >A3.close() |
| 9 | result A6 |
代码说明:
A1:连接预先配置好的 db22 数据源。
A2:执行 SQL,从表 employee 取数,参数 state=“California”。
A3、A4:从销售系统的 mongodb 读取 collection orders。
A5:使用集算器的 switch 函数,将 A4 中的 sellerid 字段切换成 A2 中的记录,关联条件为 sellerid=eid。@i 选项是指如果找不到对应的记录,则删除该行。
A6:生成一个新的序表,得到需要的字段。
A7、A8:关闭数据库连接。
A9:返回给集算报表。
第二,在报表设计器中定义参数 state,配置集算数据集:
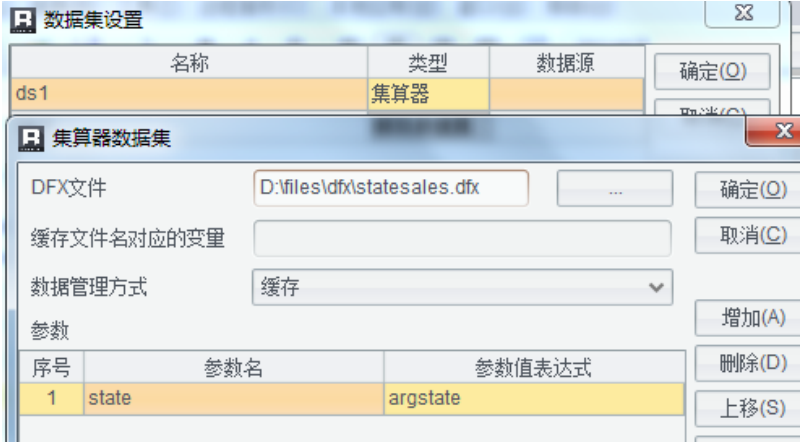
第三,设计报表如下:

运行报表,输入参数计算后,即可得到前面希望的报表。报表上部的查询界面是润乾报表自动提供的“参数模板”功能。参数模板和 db2、mongodb 数据源配置的具体做法参见教程和其他文档,这里不再赘述。
需要说明的是,如果数据源类型发生了变化,只需进行小幅改动即可使报表生效。比如新上线的销售系统采用了 oracle 数据库,只要修改 statesales.dfx 的 A1 改为:
hrdb=connect(“ora”)
同时复制 oracle jdbc 驱动、配置 oracle 数据库的连接参数即可。

















 15
15

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









