



数据库内容,随机编了一些数据,其中认为两个字段Name、Address1一致为重复记录,保留其中一条
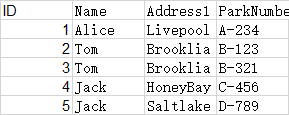
- 删除两个字段Name、Address1一致重 复的记录,保留一条:
- 找出,( 如果没有第三行,会有什么问题呢?可将示例数据中 ID 为4的行,Name字段改为Tom测试一下)
1 select * from tableabc 2 where Name in( select Name from tableabc group by Name, Address1 having count(Name) > 1) 3 and Address1 in( select Address1 from tableabc group by Name, Address1 having count(Address1) > 1)
-
- 删除
1 select * from tableabc 2 where Name in( select Name from tableabc group by Name, Address1 having count(Name) > 1) 3 and Address1 in( select Address1 from tableabc group by Name, Address1 having count(Address1) > 1) 4 and ID not in(select max(ID) from tableabc group by Name,Address1 having count(Name) > 1 )

















 6063
6063

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









