



seq 序列用法:
seq 【option】...last
seq 【option】...first last
seq 【option】...first increment last
例如:seq 5 //1-5
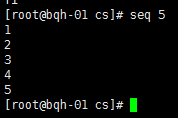
seq 2 5 //2-5
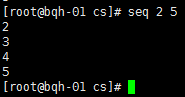
seq 1 2 10 //1-10 基数
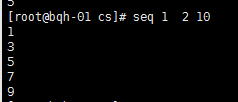
seq 2 2 10 //1-10 偶数
-s指定序列的分隔符,横向展示
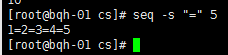
seq -s "=" 5
生成的序列追加的bqh.txt文件中:
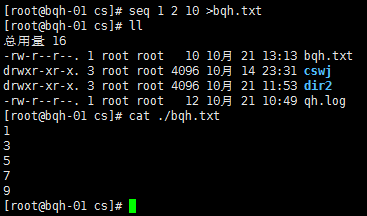
seq 1 2 10 >bqh.txt
seq 序列用法:
seq 【option】...last
seq 【option】...first last
seq 【option】...first increment last
例如:seq 5 //1-5
seq 2 5 //2-5
seq 1 2 10 //1-10 基数
seq 2 2 10 //1-10 偶数
-s指定序列的分隔符,横向展示
seq -s "=" 5
生成的序列追加的bqh.txt文件中:
seq 1 2 10 >bqh.txt
转载于:https://www.cnblogs.com/su-root/p/9826266.html
 2581
2581

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























