






 本文通过一系列指标探讨了游戏用户流失分析的重要性。分析了不同流失率水平对游戏活跃用户数(MAU)及日活跃用户数(DAU)的影响,并从数学角度解释了为何流失率会影响游戏用户量变化。
本文通过一系列指标探讨了游戏用户流失分析的重要性。分析了不同流失率水平对游戏活跃用户数(MAU)及日活跃用户数(DAU)的影响,并从数学角度解释了为何流失率会影响游戏用户量变化。
早先我曾探讨一个关于流失分析的整套流程问题,也说了流失分析是如何的重要,大概这种解说是苍白无力的,因为拿不出数据来说明这个问题,因此大家就会感觉比较飘渺,今天就是流失分析再次进行探讨,这次从数据的角度来理解为什么要做好流失分析。
挽留一个老用户相比于拉动一个新用户,在游戏收入、产品周期维护方面都有好处的,只是我们现在解决用户入口的问题,但是没有重视用户流失的问题。这个问题就好像一个水池子,有进口,但是也有出口,我们不能只关注进口的进水速率,却忽略了出水口的出水速率。这点对应了我们对于指标的量化和关注,比如当今我们考虑和分析更多的是留存的问题,却鲜有讨论流失问题,不过也可以理解,因为移动互联网上大家都从平台,渠道获得海量用户,至于你愿不愿意待着,我们就不关心了。不过,移动互联网的手游行业却不能不关心,因为手游也是一种端游缩小后一种存在形式,一定意义上手游的分析应去借鉴端游的一些分析思路和管理方法。
因此,我们需要去做好流失分析,并不断的训练、实践。
今天我将利用一系列的指标,来说明流失问题,首先,列出来今天用到的指标:
MNU:月新增用户
MAU:月活跃用户
DAU/MAU:活跃比
M_Churn_Rate:月流失率
OMAU:老活跃用户
M_1-Churn_Rate:月存留用户率
首先我们要明确对于月流失用户的定义:
一般而言,上个月(自然月)登录过游戏但在本月未登录过游戏的用户数。
自然的,对于流失率就是这部分用户数占上个月月活跃的百分比。
针对流失率的计算一种是通过技术手段精确的按照定义进行计算,而另一种方式就是粗略的进行估计计算,此处,说一下如何进行粗略的计算,在后续的讲解中,也会用到此部分知识。
我们知道上个月的月活跃中存在两部分群体:

上个月月活跃用户构成中,一部分是上个月流失用户,另一部分就是过渡到下个月活跃用户中的存留用户。
而在下个月的用户中也存在两部分,一部分就是上个月过度来的存留用户,另一部分就是本月的新增用户。
至此我们得到两个等式
上个月MAU=流失用户+存留用户
本月的MAU=存留用户+本月新增
那么上个月流失用户=上个月MAU-本月的MAU+本月新增
上述的计算方式和通过技术手段计算的流失率基本一致,可以作为粗略估计使用。解决了流失率的计算问题,下面我们就能详细开始分析流失率背后的秘密。
之前在文章中说过,游戏产品是存在一个生命周期问题的,从具体游戏产品的一系列运营来看,产品经理CB、OB和商业化运营阶段,这里面是包含着流失问题的,而且在每个时期的策略和侧重是不同的,今天我将做一些假设,来分析流失,这样便于理解。
假设如下:
月导入新增用户为20000;
月1-Churn_Rate=20%(存留率为20%,即上个月登录过游戏,且本月又登录的用户比例为20%);
月流失率为80%;
DAU/MAU为0.15;
我们可以根据上述的指标进行下述的计算:
上线第一个月
已知:
MNU1=20000
M_1-Churn_Rate1=20%
M_Churn_Rate1=80%
DAU/MAU1=0.15
Old_User(老用户)1=0
那么:
平均的DAU1=0.15*20000=3000
MAU1=20000
上线第二个月
已知:
MNU2=20000
M_1-Churn_Rate2=20%
M_Churn_Rate2=80%
DAU/MAU2=0.15
MAU1=20000
那么:
Old_User(老用户)2=MAU1* M_1-Churn_Rate1=4000
MAU2= Old_User(老用户)2+ MNU2=24000
平均的DAU2=0.15*24000=3600
上线第三个月
……
按照以上的思路进行数据计算,最终能得出来一些数据。
下图为按照流失率80%,月导入量20000进行的计算。

下图为按照流失率70%,月导入量20000进行的计算。

下图为按照流失率60%,月导入量20000进行的计算。

下图为按照流失率90%,月导入量20000进行的计算。
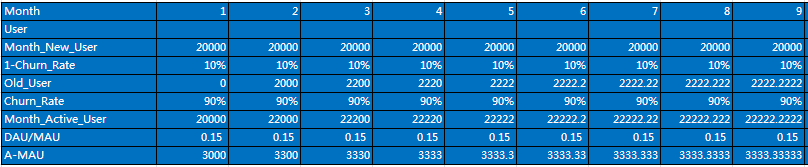
如果大家仔细观察会发现,流失率处于不同水平,反馈的MAU以及DAU都是有差异的,这点差异就是因为流失率的变化引起的。
说到此处,再仔细观察,会发现,流失率达到90%时,基本在第四个月游戏的增长就停滞了,而为80%时,在第6个月开始增长停滞了,70%时在第8个月增长停滞了,60%时在第12个月增长停滞了。也就是说流失率水平的高低也刺激了游戏的用户量变化情况,从游戏设计的角度来看这点是因为游戏大量用户流失,对新用户进入带来一种负面的反馈,对于来用户而言,则生存和游戏下去的信心不足。时间久了,用户群流失就打破游戏原本稳定的环境,此时我们一般通过加大新用户的注入来解决办法。
以上是从游戏角度来解释问题的,下面从数学角度简单的解释一下为什么到了一定的时候,后期数据变化减小,基本上达到了稳定状态。
我们了解到
注:1-Churn_Rate简写为CR%
MAU1=MUN1
MAU2=MAU1*CR1%+MUN2
MAU3=MAU2*CR2%+MNU3
MAU4=MAU3*CR3%+MNU4
……
那么
MAUn=MAUn-1 *CRn-1%+MNUn,且MNUn-1=MNUn-2=…=MNU1,CRn-1%=CRn-2%=…=CR1%,即有
MAUn=MNU*(CR%^n-1+ CR%^n-2+…+ CR1%+1)
由上述等式,可以发现,随着n逐渐增大到一定阶段,对于MAU的影响就变得越来越小。逐步稳定。
侧面来看,如果CR%本身就很小那么这种影响就更小了,也就是说MAU变化很小,但是相对应的流失率就会居高不下,游戏处于了一个放水内耗的时期。
以上是利用一些指标对于流失率进行了一个探讨分析,其实重点就是说流失分析对于一款游戏而言是非常重要的,小处来说是挽留用户,避免流失,大处来说是拉长产品生命周期。
后记:文中所用计算方式和方法作为探讨之用,不妥和纰漏之处望各位斟酌使用,如有以为和错误,欢迎指出,不胜感激。

















 1440
1440

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









